hadoop笔记整理(-)
java环境搭建:
查看本机java版本:
[xiangkun@hadoop-senior01 ~]$ rpm -qa|grep java
卸载本机java版本:
[xiangkun@hadoop-senior01 ~]$ rpm -e --nodeps java-1.6.0-
执行权限:
[xiangkun@hadoop-senior01 softwares]$ chmod u+x ./*
解压到modules目录:
[xiangkun@hadoop-senior01 softwares]$ tar -zxf jkd-1.8.0 -C /opt/modules/
配置环境变量:
###JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_131
export PATH=$PATH:$JAVA_HOME/bin
========================================================
[root@bigdata-cdh00 bin]# vim /etc/profile
fi
HOSTNAME=`/bin/hostname 2>/dev/null`
HISTSIZE=1000
if [ "$HISTCONTROL" = "ignorespace" ] ; then
export HISTCONTROL=ignoreboth
else
export HISTCONTROL=ignoredups
fi
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
export JAVA_HOME=/opt/modules/jdk1.7.0_79
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
# By default, we want umask to get set. This sets it for login shell
# Current threshold for system reserved uid/gids is 200
# You could check uidgid reservation validity in
# /usr/share/doc/setup-*/uidgid file
Hadoop安装:
apache所有文件的归档(历史版本):http://archive.apache.org/dist/
hadoop所有版本的归档:http://archive.apache.org/dist/hadoop/common
解压:
[xiangkun@hadoop-senior01 softwares]$ tar -zxf hadoop-2.5.0.tar.gz -C /opt/modules/
hadoop-env.xml
export JAVA_HOME=/opt/modules/jdk1.8.0_131
mapreduce 三种运行方式
- Local (Standalone) Mode 本地模式
- Pseudo-Distributed Mode 尾分布式模式
- Fully-Distributed Mode 分布式模式
第一种 :Local Mode
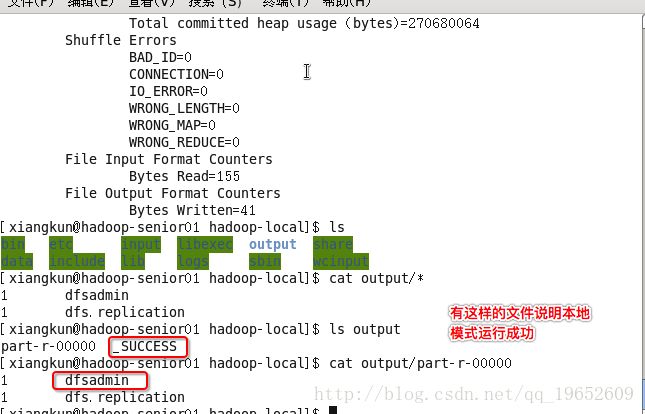
cd 到hadoop安装目录:
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar grep input output 'dfs[a-z.]+'
$ cat output/*
经典案例:使用mapreduce统计单词的个数
xiangkun@xiangkun-X550LD:/opt/modules/hadoop-2.5.0$ sudo mkdir wcinput
xiangkun@xiangkun-X550LD:/opt/modules/hadoop-2.5.0$ cd wcinput
xiangkun@xiangkun-X550LD:/opt/modules/hadoop-2.5.0/wcinput$ sudo touch wc.input // 创建一个文件
xiangkun@xiangkun-X550LD:/opt/modules/hadoop-2.5.0/wcinput$ vim wc.input //编辑这个文件
hadoop hdfs
hadoop yarn
hadoop mapreduce
$bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount wcinput wcoutput
$ cat wcoutput/*
第二种 :Pseudo-Distributed Mode
etc/hadoop/core-site.xml:
配置一:
fs.defaultFS
###这主机名,就指定了namenode运行的机器
hdfs://localhost:9000
配置二:
hadoop.tmp.dir
/opt/modules/hadoop-2.5.0/data/tmp
etc/hadoop/hdfs-site.xml:
dfs.replication
1
###指定secondarynamenode运行在那台机器上
dfs.namenode.secondary.http-address
hadoop-senior01.xiangkun:50090
###
格式化:
$ bin/hdfs namenode -format
启动:
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ sudo sbin/hadoop-daemon.sh start namenode
[sudo] password for xiangkun:
starting namenode, logging to /opt/modules/hadoop-2.5.0/logs/hadoop-root-namenode-hadoop-senior01.xiangkun.out
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ jps
4001 Jps
3878 NameNode
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/modules/hadoop-2.5.0/logs/hadoop-xiangkun-datanode-hadoop-senior01.xiangkun.out
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ jps
4032 DataNode
3878 NameNode
4103 Jps
hdfs:启动后,通过web 访问的端口是50070
在hdfs文件系统创建一个目录
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ bin/hdfs dfs -mkdir -p /usr/xiangkun/mapreduce/wordcount/input
给这个目录上传一个文件:
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ bin/hdfs dfs -put wcinput/wc.input /usr/xiangkun/mapreduce/wordcount/input
执行mapreduce程序:
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /usr/xiangkun/mapreduce/wordcount/input /usr/xiangkun/mapreduce/wordcount/output
查看执行结果:
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ bin/hdfs dfs -cat /usr/xiangkun/mapreduce/wordcount/output/*
配置yarn,将hdfs文件系统运行在yarn上
yarn-env.sh
JAVA_HOME=/opt/modules/jdk1.8.0_131
slaves (决定datanode ,nodemanager在那台机器)
hadoop-senior01.xiangkun
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop-senior01.xiangkun
启动yarn:
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start nodemanager
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ jps
4032 DataNode
5299 Jps
5268 NodeManager
3878 NameNode
5021 ResourceManager
mapped-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_131
mapred-site.xml
mapreduce.framework.name
yarn
yarn:启动后,通过web 访问的端口是8088
将hdfs运行在yarn上:
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ bin/hdfs dfs -rm -R /usr/xiangkun/mapreduce/wordcount/output/
[xiangkun@hadoop-senior01 hadoop-2.5.0]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /usr/xiangkun/mapreduce/wordcount/input /usr/xiangkun/mapreduce/wordcount/output
tips:
-
数据流只经过datanode,不经过namenode,namenode仅仅存储元数据
-
默认的default.xml是相应的jar包中。
-
日志查看方式:
- more :翻页查看
- tail: 文件的末尾 (man tail: 查看tail使用方法)
- tail -100f: 文件倒数100行日志
yarn历史监控启动:
配置日志聚集属性:
yarn-site.xml
yarn.log-aggregation-enable
true
##该属性,表示日志保存的时间
yarn.log-aggregation-retain-seconds
640800
[xiangkun@hadoop-senior01 hadoop-2.5.0]$sbin/mr-jobhistory-daemon.sh start historyserver
配置删除的文件在垃圾箱保存的时间
core-site.xml
fs.trash.interval
640800
启动方式总结:
1. 各个服务组件逐一启动
1.hdfs:
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
2.yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
3.mapreduce
mr-historyserver-daemon.sh start|stop historyserver
2.各个模块分开启动:
1.hdfs
start-dfs.sh
stop-dfs.sh
namenode先链接自己,在链接别的阶段datanode,
配置ssh无密码登录:
[xiangkun@hadoop-senior01 .ssh]$ pwd
/home/xiangkun/.ssh
[xiangkun@hadoop-senior01 .ssh]$ ssh-keygen -t rsa
###发送到其它机器(用户名一样)
[xiangkun@hadoop-senior01 .ssh]$ ssh-copy-id hostname
2.yarn
start-yarn.sh
stop-yarn.sh
3.全部启动(不推荐:因为启动hdfs,yarn都需要在主节点上,实际上是分布式的,namenode ,resoursemanager 在不同的节点上)
1.start-all.sh
2.stop-all.sh
namenode运行在那台机器:
etc/hadoop/core-site.xml:
配置一:
fs.defaultFS
###这主机名,就指定了namenode运行的机器
hdfs://localhost:9000
datanode运行在那台机器:
slaves (决定datanode ,nodemanager在那台机器)
hadoop-senior01.xiangkun
secondarynamenode运行在那台机器:
etc/hadoop/hdfs-site.xml:
###指定secondarynamenode运行在那台机器上
dfs.namenode.secondary.http-address
hadoop-senior01.xiangkun:50090
###
ResourceManager/NodeManager运行在那台机器:
yarn-site.xml
yarn.resourcemanager.hostname
hadoop-senior01.xiangkun
yarn.nodemanager.aux-services
mapreduce_shuffle
MapReduce HistoryServer运行在那台机器:
mapped-site.xml
mapreduce.jobhistory.address
hadoop-senior01.xiangkun:10020
mapreduce.jobhistory.webapp.address
hadoop-senior01.xiangkun:19888
hdfs:sbin/start-all.sh启动顺序:namenode–>datanode—>secodarynamenode—>resourcemanager—>nodemanager
然后启动mapreduce:sbin/mr-jobhistory-daemon.sh start historyserver