【论文笔记】Neural Machine Translation by Jointly Learning to Align and Translate
Neural Machine Translation by Jointly Learning to Align and Translate
--这篇论文算是在自然语言处理(NLP)中或是encoder-decoder中第一个使用attention机制的工作,将attention机制用到了神经网络机器翻译(NMT) 。
Abstract 神经机器翻译是最近提出的一种机器翻译的方法。不像传统的统计机器翻译,神经机器翻译的目标是建立一个单个的神经网络,可以共同调整,以最大限度地提高翻译性能。最近提出的神经翻译通常属于编码器-解码器(encoder-decoder)和解码器将一个目标序列编码为固定长度的向量,解码器从这些向量中生成译文。在本文中,我们推测定长向量的使用是一个提高基本的编码器-解码器框架性能的瓶颈,并提出了允许模型(软)搜索原句中与预测目标词相关的部分,不必将这些部分显示分割。通过这种新的方法,我们可以达到与现有的最先进的基于短语的英法翻译系统相当的翻译效果。此外,定性实验发现模型的(软)对齐方式和我们的直觉是一致的。
1 Introduction
神经网络机器翻译是2013年和2014年新提出来的一种机器翻译的方法。 不同于传统的基于段的翻译系统--由很多被分别调优的小子部件组成,神经机器翻译的目标是建立并训练一个可以读取一个句子并输出正确的翻译的单一的、大型的的神经网络。
很多提出的神经机器翻译都属于encoder-decoder,每种语言有一个编码器和解码器,或者是将某个特定语言的编码器应用在某个句子上,并比较它们的输出。一个解码神经网络读取和编码一个原序列为一个定长的向量。解码器输出编码向量的翻译。整个encoder-decoder系统,是由一个语言对的编码器和解码器组成的,它可以被整合训练来提高给定源句被正确翻译的概率。(encoder-decoder的工作机制)
这种encoder-decoder方法有一个潜在的问题是,神经网络需要将源句所有的必要信息压缩成定长的向量。这可能使神经网络难以处理长句子,尤其是那些比训练语料库中更长的句子。Cho(2014)发现,随着输入句子长度的增加,基本的encoder-decoder的性能会迅速下降。(encoder-decoder的缺点是难以处理长句子)
为了解决这一问题,我们引入了一种对encoder-decoder模型的拓展。每当生成的模型在翻译中生成一个单词的时候,它会(软)搜索源句中最相关信息集中的位置。然后,该模型根据与源句位置相关的上下文向量和之前产生的所有目标词来预测目标词。(引入attention机制处理长句子)
这些方法与基本的encoder-decoder最大的区别是它不试图将整个输入序列编码成一个定长的向量。相反,它将输入序列编码成向量,然后当解码翻译的时候自适应地选择向量的子集。这使得神经翻译模型避免把源句的所有信息,不管它的长度,压扁成一个定长的向量。我们发现这可以让模型更好的处理长句子。(改进的模型与原来的区别)
在论文中,我们证明了提出地对齐和翻译联合学习的方法比基本的encoder-decoder模型在翻译性能上有显著提升。这样的提升句子越长,效果越明显,但任何长度的句子都能看到(改进)。在英法翻译任务上,提出的方法在单一的模型下实现了翻译性能相当或接近传统的基于短语的翻译系统。除此之外,数量分析揭示了提出的模型找到了一种语言学上可信的/源句和对应的目标句之间的(软)排列。
2 背景:神经机器翻译
从概略学的角度看,翻译等价于找到给定的源句x时最大的条件概率y对应的目标句y,![]() 。在神经机器翻译中,我们使用并行训练语料库来拟合参数化模型,以最大化句子对的条件概率。一旦翻译模型学到了条件分布,给定源句对应的翻译可以通过搜索能最大化条件概率的句子得到。
。在神经机器翻译中,我们使用并行训练语料库来拟合参数化模型,以最大化句子对的条件概率。一旦翻译模型学到了条件分布,给定源句对应的翻译可以通过搜索能最大化条件概率的句子得到。
最近,一些论文已经提出了神经网络的作用就是直接学习条件分布。神经机器翻译方法通常由两个部分组成,第一个是编码原序列,第二个是解码到目标序列。例如,Cho和Sutskever(2014)分别采用两个RNN将可变源句编码为定长向量以及将该向量解码为变长的目标句。
尽管作为一种比较新的方法,神经机器翻译早已经便显出良好的效果。Sutskever(2014)报道了基于使用了LSTM单元的RNN神经机器翻译在英法翻译任务上已经相当于最先进性能的传统基于短语的机器翻译系统。例如,对现有的翻译系统增加神经组件,以对短语表中的短语对进行评分或对候选翻译进行重新排序,已经超过了以前最先进的性能水平。
2.1 RNN encoder-decoder
encoder将向量x的序列![]() 转换成向量c,最常见的使用RNN的方法是
转换成向量c,最常见的使用RNN的方法是
![]() (1)
(1)
![]()
![]() 是 t 时刻的隐藏状态,c是由隐藏状态产生的向量,f 和 s 是一些非线性函数。例如,Sutskever(2014)曾使用一个LSTM作为 f 和
是 t 时刻的隐藏状态,c是由隐藏状态产生的向量,f 和 s 是一些非线性函数。例如,Sutskever(2014)曾使用一个LSTM作为 f 和![]() 。
。
解码器通常被训练给定文本向量c和所有之前预测过的单词 { ![]() } ,预测下一个单词
} ,预测下一个单词 ![]() 。换句话说,解码器通过分解将联合概率为有序的条件来定义在翻译y上的概率:
。换句话说,解码器通过分解将联合概率为有序的条件来定义在翻译y上的概率:
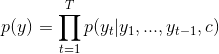 (2)
(2)
这里y= { ![]() }。对RNN,每个条件概率被描述为:
}。对RNN,每个条件概率被描述为:
![]() (3)
(3)
这里g是非线性的,可能是多层的函数,它的输出是![]() 的概率,
的概率,![]() 是RNN的隐层状态。需要注意的是,还可以使用其他架构,类似RNN和去卷积神经网络的混合。
是RNN的隐层状态。需要注意的是,还可以使用其他架构,类似RNN和去卷积神经网络的混合。
3 对齐和翻译学习
本节中,我们提出了一种新的神经机器翻译。新的框架由一个双向的RNN作为编码器(3.2)和一个在解码翻译时対源句模拟搜索的解码器组成(3.1)。
3.1 解码:通用描述
在新的模型框架中,我们定义了等式(2)中的每个条件概率:
![]() (4)
(4)
这里的![]() 是i时刻RNN的隐层状态,它被计算为:
是i时刻RNN的隐层状态,它被计算为:
![]()
应该注意到不同于现有的encoder-decoder方法,这里的概率是有一个对每个目标词 ![]() 不同的上下文向量
不同的上下文向量 ![]() 决定的。
决定的。
上下文向量 ![]() 取决于由编码器映射的输入序列的翻译序列
取决于由编码器映射的输入序列的翻译序列![]() 。每个注释
。每个注释 ![]() 包含整个输入序列的信息,特别是输入序列的第i个单词周围的部分。我们在下一节中详细的介绍了注释 是如何产生的。
包含整个输入序列的信息,特别是输入序列的第i个单词周围的部分。我们在下一节中详细的介绍了注释 是如何产生的。
上下文向量 ![]() 是通过计算所有注释的加权和:
是通过计算所有注释的加权和:
 (5)
(5)
每个注释 ![]() 的 权重
的 权重 ![]() 的计算方法:
的计算方法:
![]() (6)
(6)
这里 ![]() 是对齐模型,它可以评估 位置 j 附近的输入和位置 i 的输出的匹配程度。得分基于RNN隐层状态
是对齐模型,它可以评估 位置 j 附近的输入和位置 i 的输出的匹配程度。得分基于RNN隐层状态 ![]() 和 输入序列的第 j 个注释
和 输入序列的第 j 个注释 ![]() 来判断的。
来判断的。
我们把对齐模型 a 参数华为一个前馈神经网络,该神经网络与系统中的其他组件联合训练。注意,与传统的机器翻译不同,对齐不被认为是一个潜在的向量。相反,对齐模型直接计算软对齐,从而可以使代价函数的梯度反向传播。该梯度可用于联合训练对齐模型和整个翻译模型。
这样,我们可以理解这种将所有注释的加权和作为计算一种预期注释的方法,这里的期望基于可能的对齐。![]() 是目标词
是目标词 ![]() 是由源词
是由源词 ![]() 对齐,或者翻译过来的概率。那么,第 i 个上下文向量
对齐,或者翻译过来的概率。那么,第 i 个上下文向量 ![]() 是所有具有概率
是所有具有概率 ![]() 的注释中的期望注释。
的注释中的期望注释。
概率 ![]() ,或者其相关的能量
,或者其相关的能量![]() ,反映了注释
,反映了注释 ![]() 的在决定下一个状态
的在决定下一个状态![]() 和生成
和生成 ![]() 时,过去的隐藏状态
时,过去的隐藏状态![]() 的 重要程度。直观的来说,在解码阶段实现了一种注意力机制解码决定源句的关注部分。通过让解码器具有注意力机制,我们减轻了变发起必须要将源句中所有信息编码成一个定长向量的负担。用这种新方法,信息可以在注释序列中扩散,相应的解码器可以选择性的检索这些注释。
的 重要程度。直观的来说,在解码阶段实现了一种注意力机制解码决定源句的关注部分。通过让解码器具有注意力机制,我们减轻了变发起必须要将源句中所有信息编码成一个定长向量的负担。用这种新方法,信息可以在注释序列中扩散,相应的解码器可以选择性的检索这些注释。
3.2 编码器:用于注释序列的双向RNN
通常的RNN,像等式(1)描述的那样,从第一个符号![]() 到最后一个
到最后一个![]() 顺序读入输入序列 x 。然而,在我们提出的方案中,我们希望每个单词注释不仅要总结之前单词,还能总结之后的单词。因此,我们提出采用双向的RNN(biRNN,1997),它最近已经成功的被应用于语音识别。
顺序读入输入序列 x 。然而,在我们提出的方案中,我们希望每个单词注释不仅要总结之前单词,还能总结之后的单词。因此,我们提出采用双向的RNN(biRNN,1997),它最近已经成功的被应用于语音识别。
一个biRNN包括前向和后向RNN。前向RNN ![]() 按顺序读取输入向量(从
按顺序读取输入向量(从![]() 到
到![]() )并计算前向隐藏状态序列
)并计算前向隐藏状态序列 ![]() 。后向RNN
。后向RNN ![]() 逆序读取序列(从
逆序读取序列(从![]() 到
到![]() ),得到一个后向隐藏状态序列
),得到一个后向隐藏状态序列 ![]() 。
。
我们将前向隐层状态 ![]() 和后向隐层状态
和后向隐层状态 ![]() 联系起来(
联系起来(![]() ),得到每个单词
),得到每个单词 ![]() 的注释。用这样的方法,注释
的注释。用这样的方法,注释![]() 既能总结前面的单词又能总结后面的单词。因为RNN倾向于正好的表现最近的输入,注释
既能总结前面的单词又能总结后面的单词。因为RNN倾向于正好的表现最近的输入,注释 ![]() 就会更集中单词
就会更集中单词 ![]() 的注释。注释序列被解码器和排列模型之后用来计算文本向量(用等式(5)和(6))。
的注释。注释序列被解码器和排列模型之后用来计算文本向量(用等式(5)和(6))。
4 实验设置
4.1 数据
4.2 模型
我们训练了两种模型。一种是Cho2014年提出的RNN Encoder-Decoder(RNNencdec),另一个本文提出的模型,我们称之为RNNsearch。每个模型训练两次:先用长度为30个单词的句子训练(RNNencdec-30,RNNsearch-30),然后用长度为50的句子训练(RNNencdec-50,RNNsearch-50)。
RNNencdec的编码器和解码器有1000个隐层单元。RNNsearch的编码器由前向和后向RNN组成,每个RNN有1000个隐层单元。在这两种情况下,我们都采用了有带有single maxout的隐层组成的多层网络来计算每个目标词的条件概率。
我们和Adadelta(Zeiler,2012)一样使用小批量的随机梯度下降算法。每次SGD更新的方向是通过对80个句子的小批量样本计算得来的。我们对每个模型进行了大概5天的训练。
当训练模型时,我们使用波束来搜索近似条件概率最大的翻译。
5 结果
5.1 定量结果
表一中,我们列出以BLEU分数衡量翻译表现。在表中我们可以清晰地看到,在所有情况下,提出的RNNsearch都优于传统的RNNencdec。更重要的是,当只考虑由已知词组成的句子时,RNNsearch的性能和传统的基于短语的翻译系统(Moses)一样好。这是一个很重大的成就,因为考虑到Moses使用的是一个单独的语料库,而不是我们在训练RNNsearch和RNNencdec时使用的平行语料库。
我们提出方法的一个动机就是在基本的encoder-decoder中定长上下文向量的使用。我们推测这样的限制使得基本的encoder-decoder方法在长句子上表现不佳。实验进一步证明了提出的模型相较于基本的encoder-decoder模型的优势(在处理长句子方面)
5.2 定性分析
5.2.1 对齐
提出的方法提供了一种直观的方法来检查生成的译文中的词和源句中的词之间的对齐(软对齐)。矩阵的每一行都暗示了与译文相关的权重。由此我们可以看出,在生成目标词时,源句中的哪些位置被认为更重要。
从图3的排列中,我们可以看出英语和法语之间的单词对齐基本上是单调的。我们在每个矩阵的对角线上都能看到很重的权重。然而,我们也观察到一些非平凡的,非单调的对齐。形容词和名词在英语和法语中的顺序是不同的从图3中我们可以看出模型能正确的翻译单词。RNNsearch可以跳过两个单词,正确对齐对应单词,然后每次回头看一个词,将整个词完整地呈现出来。
从图3(d)能看出软对齐相较于硬对齐的力量。不像硬对齐处理翻译那么生硬,可以自然的考虑前后文进行对应;另一个好处是能自然的处理不同长度的源和目标短语,而不用以一种反直觉的方式把一些词映射成(NULL)。
5.2.2 长句子
RNNsearch可以在翻译长句方面比传统模型(RNNencdec)要好得多。这可能是因为RNNsearch不需要讲一个长句子完美的编码到一个固定长度的向量中,而只精确的编码输入句子中某个特定单词的周围。