深度学习 1. CNN的构建和解释--最简单的CNN构造(LeNet-5)# By deepLearnToolbox-master
本文为原创文章转载请注明出处,博主博客地址:http://blog.csdn.net/qq_20259459 和
作者( [email protected] )信息。
今天介绍一个曾经用过的简单的CNN Toolbox--------DeepLearnToolbox-master。
DeepLearnToolbox-master 介绍:
贡献者:Rasmus Berg Palm(丹麦)
最后更新时间:2012年
现在状态:停止维护
简介:DeepLearnToolbox-master 最为一个工具箱里面包括了CAE,CNN,DBN,NN,SAE这些模型。其本身而言是非常简单的设计,所以就目前而言早已经过时了。也不会再被用于开发中。现在主流当然是: Theano, torch, tensorflow, Matconvnet, MxNet, caffe,后面我会选择介绍。
但是对于新学者来说,DeepLearnToolbox-master 中的CNN模型是以LeNet-5编写的,所以非常好,适合我们去理解学习。
DeepLearnToolbox-master下载地址: https://github.com/rasmusbergpalm/DeepLearnToolbox
CNN 流程:
首先我们运行 test_example_CNN.m.
然后 test_example_CNN.mat 会载入mnist_uint8.mat
接着去调用cnnsetup.m, cnntrain.m, cnntest.m.
接下来cnntrain.m 会去调用 cnnff.m, cnnbp.m, cnnapplygrads.m.
最后就是画出 MSE-- data 的图像。
所以可以看出流程还是非常简单明了的。
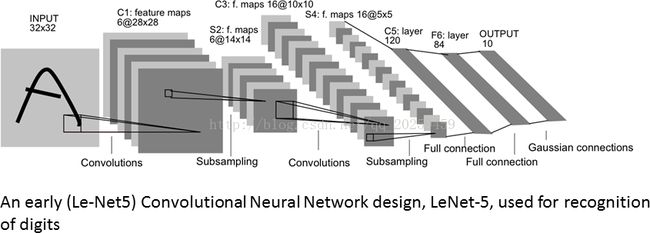
最终我们会形成的CNN图示--经典的LeNet-5:
如果初学者不知道权重权值怎么计算请看下图,当时自己学习时做的笔记。我一步一步都写的非常的清楚,很好理解。

下面开始介绍CODE:
1. test_example_CNN.mat :
%主要功能:在mnist数据库上做实验,验证工具箱的有效性
% 算法流程:1)载入训练样本和测试样本
% 2)设置CNN参数,并进行训练
% 3)进行检测cnntest()
% 注意事项:1)由于直接将所有测试样本输入会导致内存溢出,故采用一次只测试一个训练样本的测试方法
function test_example_CNN
%%load data
load mnist_uint8; %载入数据
%% input data
train_x = double(reshape(train_x',28,28,60000))/255; %标准化数据(这里作者给出的方法并不是很好需要改进)
test_x = double(reshape(test_x',28,28,10000))/255;
train_y = double(train_y');
test_y = double(test_y');
%% ex1 Train a 6c-2s-12c-2s Convolutional neural network
%will run 1 epoch in about 200 second and get around 11% error.
%With 100 epochs you'll get around 1.2% error
%% 翻译内容:
%%%%%%%%%%%%%%%%%%%%设置卷积神经网络参数%%%%%%%%%%%%%%%%%%%%
% 主要功能:训练一个6c-2s-12c-2s形式的卷积神经网络,预期性能如下:
% 1)迭代一次需要200秒左右,错误率大约为11%
% 2)迭代一百次后错误率大约为1.2%
% 算法流程:1)构建神经网络并进行训练,以CNN结构体的形式保存
% 2)用已知的训练样本进行测试
% 注意事项:1)之前在测试的时候提示内存溢出,后来莫名其妙的又不溢出了,估计到了系统的内存临界值
%%=========================================================================
rand('state',0)
cnn.layers = {
struct('type', 'i') %input layer%输入层
struct('type', 'c', 'outputmaps', 6, 'kernelsize', 5) %convolution layer%卷积层
struct('type', 's', 'scale', 2) %sub sampling layer%下采样层
struct('type', 'c', 'outputmaps', 12, 'kernelsize', 5) %convolution layer%卷积层
struct('type', 's', 'scale', 2) %subsampling layer%下采样层
};
%% 训练选项,alpha学习效率(不用),batchsiaze批训练总样本的数量,numepoches迭代次数
opts.alpha = 0.1;
opts.batchsize = 100;
opts.numepochs = 100;
%%
cnn = cnnsetup(cnn, train_x, train_y);
cnn = cnntrain(cnn, train_x, train_y, opts);
[er, bad] = cnntest(cnn, test_x, test_y);
%plot mean squared error
figure; plot(cnn.rL);
assert(er<0.12, 'Too big error');
% 输入参数:net,待设置的卷积神经网络;x,训练样本;y,训练样本对应标签;
% 输出参数:net,初始化完成的卷积神经网络
% 主要功能:对CNN的结构进行初始化
% 注意事项:isOctave错误发生,请把 util 文件添加至运行路径中。
function net = cnnsetup(net, x, y)
assert(~isOctave() || compare_versions(OCTAVE_VERSION, '3.8.0', '>='), ['Octave 3.8.0 or greater is required for CNNs as there is a bug in convolution in previous versions. See http://savannah.gnu.org/bugs/?39314. Your version is ' myOctaveVersion]);
inputmaps = 1; %初始化网络输入层数为1层
%%=========================================================================
% 主要功能:得到输入图像的行数和列数
% 注意事项:1)B=squeeze(A) 返回和矩阵A相同元素但所有单一维都移除的矩阵B,单一维是满足size(A,dim)=1的维。
% train_x中图像的存放方式是三维的reshape(train_x',28,28,60000),前面两维表示图像的行与列,
% 第三维就表示有多少个图像。这样squeeze(x(:, :, 1))就相当于取第一个图像样本后,再把第三维
% 移除,就变成了28x28的矩阵,也就是得到一幅图像,再size一下就得到了训练样本图像的行数与列数了
%%=========================================================================
mapsize = size(squeeze(x(:, :, 1)));
% mapsize = size(x);
%%%%%%%%%%%%%%%%%%%%下面通过传入net这个结构体来逐层构建CNN网络%%%%%%%%%%%%%%%%%%%%
for l = 1 : numel(net.layers) %对于每一层
if strcmp(net.layers{l}.type, 's') %如果当前层是下采样层
%%=========================================================================
% 主要功能:获取下采样之后特征map的尺寸
% 注意事项:1)subsampling层的mapsize,最开始mapsize是每张图的大小28*28
% 这里除以scale=2,就是pooling之后图的大小,pooling域之间没有重叠,所以pooling后的图像为14*14
% 注意这里的右边的mapsize保存的都是上一层每张特征map的大小,它会随着循环进行不断更新
%%=========================================================================
mapsize = mapsize / net.layers{l}.scale;
assert(all(floor(mapsize)==mapsize), ['Layer ' num2str(l) ' size must be integer. Actual: ' num2str(mapsize)]);
for j = 1 : inputmaps %对于上一层的每个特征图
net.layers{l}.b{j} = 0; %将偏置初始化为零
end
end
if strcmp(net.layers{l}.type, 'c') %如果当前层是卷基层
%%=========================================================================
% 主要功能:获取卷积后的特征map尺寸以及当前层待学习的卷积核的参数数量
% 注意事项:1)旧的mapsize保存的是上一层的特征map的大小,那么如果卷积核的移动步长是1,那用
% kernelsize*kernelsize大小的卷积核卷积上一层的特征map后,得到的新的map的大小就是下面这样
% 2)fan_out代表该层需要学习的参数个数。每张特征map是一个(后层特征图数量)*(用来卷积的patch图的大小)
% 因为是通过用一个核窗口在上一个特征map层中移动(核窗口每次移动1个像素),遍历上一个特征map
% 层的每个神经元。核窗口由kernelsize*kernelsize个元素组成,每个元素是一个独立的权值,所以
% 就有kernelsize*kernelsize个需要学习的权值,再加一个偏置值。另外,由于是权值共享,也就是
% 说同一个特征map层是用同一个具有相同权值元素的kernelsize*kernelsize的核窗口去感受输入上一
% 个特征map层的每个神经元得到的,所以同一个特征map,它的权值是一样的,共享的,权值只取决于
% 核窗口。然后,不同的特征map提取输入上一个特征map层不同的特征,所以采用的核窗口不一样,也
% 就是权值不一样,所以outputmaps个特征map就有(kernelsize*kernelsize+1)* outputmaps那么多的权值了
% 但这里fan_out只保存卷积核的权值W,偏置b在下面独立保存
%%====================================================================
mapsize = mapsize - net.layers{l}.kernelsize + 1;
fan_out = net.layers{l}.outputmaps * net.layers{l}.kernelsize ^ 2;
for j = 1 : net.layers{l}.outputmaps % %对于卷积层的每一个输出map
%%=========================================================================
% 主要功能:获取卷积层与前一层输出map之间需要链接的参数链个数
% 注意事项:1)fan_out保存的是对于上一层的一张特征map,我在这一层需要对这一张特征map提取outputmaps种特征,
% 提取每种特征用到的卷积核不同,所以fan_out保存的是这一层输出新的特征需要学习的参数个数
% 而,fan_in保存的是,我在这一层,要连接到上一层中所有的特征map,然后用fan_out保存的提取特征
% 的权值来提取他们的特征。也即是对于每一个当前层特征图,有多少个参数链到前层
%%=================================================================
fan_in = inputmaps * net.layers{l}.kernelsize ^ 2;
for i = 1 : inputmaps %对于上一层的每一个输出特征map(本层的输入map)
%%=========================================================================
% 主要功能:随机初始化卷积核的权值,再将偏置均初始化为零
% 注意事项:1)随机初始化权值,也就是共有outputmaps个卷积核,对上层的每个特征map,都需要用这么多个卷积核去卷积提取特征。
% rand(n)是产生n×n的 0-1之间均匀取值的数值的矩阵,再减去0.5就相当于产生-0.5到0.5之间的随机数
% 再 *2 就放大到 [-1, 1]。然后再乘以后面那一数,why?
% 反正就是将卷积核每个元素初始化为[-sqrt(6 / (fan_in + fan_out)), sqrt(6 / (fan_in + fan_out))]
% 之间的随机数。因为这里是权值共享的,也就是对于一张特征map,所有感受野位置的卷积核都是一样的
% 所以只需要保存的是 inputmaps * outputmaps 个卷积核。
% 2)为什么这里是inputmaps * outputmaps个卷积核?
%%===============================================================
net.layers{l}.k{i}{j} = (rand(net.layers{l}.kernelsize) - 0.5) * 2 * sqrt(6 / (fan_in + fan_out));
end
net.layers{l}.b{j} = 0;
end
inputmaps = net.layers{l}.outputmaps; %在卷积层会更新每层网络的输出map数量
end
end
% 'onum' is the number of labels, that's why it is calculated using size(y, 1). If you have 20 labels so the output of the network will be 20 neurons.
% 'fvnum' is the number of output neurons at the last layer, the layer just before the output layer.
% 'ffb' is the biases of the output neurons.
% 'ffW' is the weights between the last layer and the output neurons. Note that the last layer is fully connected to the output layer, that's why the size of the weights is (onum * fvnum)
%%=========================================================================
% 主要功能:初始化最后一层,也就是输出层的参数值
% 算法流程:1)fvnum 是输出层的前面一层的神经元个数。这一层的上一层是经过pooling后的层,包含有inputmaps个
% 特征map。每个特征map的大小是mapsize,所以,该层的神经元个数是 inputmaps * (每个特征map的大小)
% 2)onum 是标签的个数,也就是输出层神经元的个数。你要分多少个类,自然就有多少个输出神经元
% 3)net.ffb和net.ffW为最后一层(全连接层)的偏置和权重
%%=========================================================================
fvnum = prod(mapsize) * inputmaps;
onum = size(y, 1);
net.ffb = zeros(onum, 1);
net.ffW = (rand(onum, fvnum) - 0.5) * 2 * sqrt(6 / (onum + fvnum));
end3. cnntrain.m:
%输入参数:net,神经网络;x,训练数据矩阵;y,训练数据的标签矩阵;opts,神经网络的相关训练参数
%输出参数:net,训练完成的卷积神经网络
%算法流程:1)将样本打乱,随机选择进行训练;
% 2)取出样本,通过cnnff2()函数计算当前网络权值和网络输入下网络的输出
% 3)通过BP算法计算误差对网络权值的导数
% 4)得到误差对权值的导数后,就通过权值更新方法去更新权值
%注意事项:1)使用BP算法计算梯度
function net = cnntrain(net, x, y, opts)
m = size(x, 3); %m保存的是训练样本个数
numbatches = m / opts.batchsize; %numbatches表示每次迭代中所选取的训练样本数
if rem(numbatches, 1) ~= 0 %如果numbatches不是整数,则程序发生错误
error('numbatches not integer');
end
%%=====================================================================
%主要功能:CNN网络的迭代训练
%实现步骤:1)通过randperm()函数将原来的样本顺序打乱,再挑出一些样本来进行训练
% 2)取出样本,通过cnnff2()函数计算当前网络权值和网络输入下网络的输出
% 3)通过BP算法计算误差对网络权值的导数
% 4)得到误差对权值的导数后,就通过权值更新方法去更新权值
%注意事项:1)P = randperm(N),返回[1, N]之间所有整数的一个随机的序列,相当于把原来的样本排列打乱,
% 再挑出一些样本来训练
% 2)采用累积误差的计算方式来评估当前网络性能,即当前误差 = 以前误差 * 0.99 + 本次误差 * 0.01
% 使得网络尽可能收敛到全局最优
%%=====================================================================
net.rL = []; %代价函数值,也就是误差值
for i = 1 : opts.numepochs %对于每次迭代
disp(['epoch ' num2str(i) '/' num2str(opts.numepochs)]);
tic; %使用tic和toc来统计程序运行时间
%%%%%%%%%%%%%%%%%%%%取出打乱顺序后的batchsize个样本和对应的标签 %%%%%%%%%%%%%%%%%%%%
kk = randperm(m);
for l = 1 : numbatches
batch_x = x(:, :, kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize));
batch_y = y(:, kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize));
%%%%%%%%%%%%%%%%%%%%在当前的网络权值和网络输入下计算网络的输出(特征向量)%%%%%%%%%%%%%%%%%%%%
net = cnnff(net, batch_x);
%%%%%%%%%%%%%%%%%%%%通过对应的样本标签用bp算法来得到误差对网络权值的导数%%%%%%%%%%%%%%%%%%%%
net = cnnbp(net, batch_y);
%%%%%%%%%%%%%%%%%%%%通过权值更新方法去更新权值%%%%%%%%%%%%%%%%%%%%
net = cnnapplygrads(net, opts);
if isempty(net.rL)
net.rL(1) = net.L; %代价函数值,也就是均方误差值 ,在cnnbp.m中计算初始值 net.L = 1/2* sum(net.e(:) .^ 2) / size(net.e, 2);
end
net.rL(end + 1) = 0.99 * net.rL(end) + 0.01 * net.L; %采用累积的方式计算累计误差
end
toc;
end
end
4. cnntest.m:
function [er, bad] = cnntest(net, x, y)
% feedforward
net = cnnff(net, x);
[~, h] = max(net.o);
[~, a] = max(y);
bad = find(h ~= a);
er = numel(bad) / size(y, 2);
end
%输入参数:net,神经网络;x,训练数据矩阵;
%输出参数:net,训练完成的卷积神经网络
%主要功能:使用当前的神经网络对输入的向量进行预测
%算法流程:1)将样本打乱,随机选择进行训练;
% 2)讲样本输入网络,层层映射得到预测值
%注意事项:1)使用BP算法计算梯度
function net = cnnff(net, x)
n = numel(net.layers); %层数
net.layers{1}.a{1} = x; %网络的第一层就是输入,但这里的输入包含了多个训练图像
inputmaps = 1; %输入层只有一个特征map,也就是原始的输入图像
for l = 2 : n % for each layer %对于每层(第一层是输入层,循环时先忽略掉)
if strcmp(net.layers{l}.type, 'c') %如果当前是卷积层
% !!below can probably be handled by insane matrix operations
for j = 1 : net.layers{l}.outputmaps % for each output map %对每一个输入map,需要用outputmaps个不同的卷积核去卷积图像
%%=========================================================================
%主要功能:创建outmap的中间变量,即特征矩阵
%实现步骤:用这个公式生成一个零矩阵,作为特征map
%注意事项:1)对于上一层的每一张特征map,卷积后的特征map的大小是:(输入map宽 - 卷积核的宽 + 1)* (输入map高 - 卷积核高 + 1)
% 2)由于每层都包含多张特征map,则对应的索引则保存在每层map的第三维,及变量Z中
%%=========================================================================
% create temp output map
z = zeros(size(net.layers{l - 1}.a{1}) - [net.layers{l}.kernelsize - 1 net.layers{l}.kernelsize - 1 0]);
for i = 1 : inputmaps % for each input map %对于输入的每个特征map
%%=========================================================================
%主要功能:将上一层的每一个特征map(也就是这层的输入map)与该层的卷积核进行卷积
%实现步骤:1)进行卷积
% 2)加上对应位置的基b,然后再用sigmoid函数算出特征map中每个位置的激活值,作为该层输出特征map
%注意事项:1)当前层的一张特征map,是用一种卷积核去卷积上一层中所有的特征map,然后所有特征map对应位置的卷积值的和
% 2)有些论文或者实际应用中,并不是与全部的特征map链接的,有可能只与其中的某几个连接
%%============================================================
% convolve with corresponding kernel and add to temp output map
z = z + convn(net.layers{l - 1}.a{i}, net.layers{l}.k{i}{j}, 'valid');
end
% add bias, pass through nonlinearity
net.layers{l}.a{j} = sigm(z + net.layers{l}.b{j}); %加基(加上加性偏置b)
end
% set number of input maps to this layers number of outputmaps
inputmaps = net.layers{l}.outputmaps; %更新当前层的map数量;
elseif strcmp(net.layers{l}.type, 's') %如果当前层是下采样层
% downsample
for j = 1 : inputmaps
%%=========================================================================
%主要功能:对特征map进行下采样
%实现步骤:1)进行卷积
% 2)最终pooling的结果需要从上面得到的卷积结果中以scale=2为步长,跳着把mean pooling的值读出来
%注意事项:1)例如我们要在scale=2的域上面执行mean pooling,那么可以卷积大小为2*2,每个元素都是1/4的卷积核
% 2)因为convn函数的默认卷积步长为1,而pooling操作的域是没有重叠的,所以对于上面的卷积结果
% 3)是利用卷积的方法实现下采样
%%=========================================================================
z = convn(net.layers{l - 1}.a{j}, ones(net.layers{l}.scale) / (net.layers{l}.scale ^ 2), 'valid'); % !! replace with variable
net.layers{l}.a{j} = z(1 : net.layers{l}.scale : end, 1 : net.layers{l}.scale : end, :); %跳读mean pooling的值
end
end
end
%%=========================================================================
%主要功能:输出层,将最后一层得到的特征变成一条向量,作为最终提取得到的特征向量
%实现步骤:1)获取倒数第二层中每个特征map的尺寸
% 2)用reshape函数将map转换为向量的形式
% 3)使用sigmoid(W*X + b)函数计算样本输出值,放到net成员o中
%注意事项:1)在使用sigmoid()函数是,是同时计算了batchsize个样本的输出值
%%=========================================================================
% concatenate all end layer feature maps into vector
net.fv = []; %net.fv为神经网络倒数第二层的输出map
for j = 1 : numel(net.layers{n}.a) %最后一层的特征map的个数
sa = size(net.layers{n}.a{j}); %第j个特征map的大小
net.fv = [net.fv; reshape(net.layers{n}.a{j}, sa(1) * sa(2), sa(3))];
end
% feedforward into output perceptrons
net.o = sigm(net.ffW * net.fv + repmat(net.ffb, 1, size(net.fv, 2))); %通过全连接层的映射得到网络的最终预测结果输出
end6. cnnbp.m:
%输入参数:net,呆训练的神经网络;y,训练样本的标签,即期望输出
%输出参数:net,经过BP算法训练得到的神经网络
%主要功能:通过BP算法训练神经网络参数
%实现步骤:1)将输出的残差扩展成与最后一层的特征map相同的尺寸形式
% 2)如果是卷积层,则进行上采样
% 3)如果是下采样层,则进行下采样
% 4)采用误差传递公式对灵敏度进行反向传递
%注意事项:1)从最后一层的error倒推回来deltas,和神经网络的BP十分相似,可以参考“UFLDL的反向传导算法”的说明
% 2)在fvd里面保存的是所有样本的特征向量(在cnnff.m函数中用特征map拉成的),所以这里需要重新换回来特征map的形式,
% d保存的是delta,也就是灵敏度或者残差
% 3)net.o .* (1 - net.o))代表输出层附加的非线性函数的导数,即sigm函数的导数
function net = cnnbp(net, y)
n = numel(net.layers); %网络层数
% error
net.e = net.o - y; %实际输出与期望输出之间的误差
% loss function
net.L = 1/2* sum(net.e(:) .^ 2) / size(net.e, 2); %代价函数,采用均方误差函数作为代价函数
%% backprop deltas
net.od = net.e .* (net.o .* (1 - net.o)); % output delta%输出层的灵敏度或者残差,(net.o .* (1 - net.o))代表输出层的激活函数的导数
net.fvd = (net.ffW' * net.od); % feature vector delta%残差反向传播回前一层,net.fvd保存的是残差
if strcmp(net.layers{n}.type, 'c') % only conv layers has sigm function%只有卷积层采用sigm函数
net.fvd = net.fvd .* (net.fv .* (1 - net.fv)); %net.fv是前一层的输出(未经过simg函数),作为输出层的输入
end
%%%%%%%%%%%%%%%%%%%%将输出的残差扩展成与最后一层的特征map相同的尺寸形式%%%%%%%%%%%%%%%%%%%%
% reshape feature vector deltas into output map style
sa = size(net.layers{n}.a{1}); %最后一层特征map的大小。这里的最后一层都是指输出层的前一层
fvnum = sa(1) * sa(2); %因为是将最后一层特征map拉成一条向量,所以对于一个样本来说,特征维数是这样
for j = 1 : numel(net.layers{n}.a) %最后一层的特征map的个数
net.layers{n}.d{j} = reshape(net.fvd(((j - 1) * fvnum + 1) : j * fvnum, :), sa(1), sa(2), sa(3));
end
for l = (n - 1) : -1 : 1 %对于输出层前面的层(与输出层计算残差的方式不同)
if strcmp(net.layers{l}.type, 'c') %如果是卷积层,则进行上采样
for j = 1 : numel(net.layers{l}.a) %该层特征map的个数
%%=========================================================================
%主要功能:卷积层的灵敏度误差传递
%注意事项:1)net.layers{l}.d{j} 保存的是 第l层 的 第j个 map 的 灵敏度map。 也就是每个神经元节点的delta的值
% expand的操作相当于对l+1层的灵敏度map进行上采样。然后前面的操作相当于对该层的输入a进行sigmoid求导
% 这条公式请参考 Notes on Convolutional Neural Networks
%%=========================================================================
net.layers{l}.d{j} = net.layers{l}.a{j} .* (1 - net.layers{l}.a{j}) .* (expand(net.layers{l + 1}.d{j}, [net.layers{l + 1}.scale net.layers{l + 1}.scale 1]) / net.layers{l + 1}.scale ^ 2);
end
elseif strcmp(net.layers{l}.type, 's') %如果是下采样层,则进行下采样
%%=========================================================================
%主要功能:下采样层的灵敏度误差传递
%注意事项:1)这条公式请参考 Notes on Convolutional Neural Networks
%%====================================================================
for i = 1 : numel(net.layers{l}.a) %第i层特征map的个数
z = zeros(size(net.layers{l}.a{1}));
for j = 1 : numel(net.layers{l + 1}.a) %第l+1层特征map的个数
z = z + convn(net.layers{l + 1}.d{j}, rot180(net.layers{l + 1}.k{i}{j}), 'full');
end
net.layers{l}.d{i} = z;
end
end
end
%%=========================================================================
%主要功能:计算梯度
%实现步骤:
%注意事项:1)这里与Notes on Convolutional Neural Networks中不同,这里的子采样层没有参数,也没有
% 激活函数,所以在子采样层是没有需要求解的参数的
%%=========================================================================
%% calc gradients
for l = 2 : n
if strcmp(net.layers{l}.type, 'c')
for j = 1 : numel(net.layers{l}.a)
for i = 1 : numel(net.layers{l - 1}.a)
%%%%%%%%%%%%%%%%%%%%dk保存的是误差对卷积核的导数%%%%%%%%%%%%%%%%%%%%
net.layers{l}.dk{i}{j} = convn(flipall(net.layers{l - 1}.a{i}), net.layers{l}.d{j}, 'valid') / size(net.layers{l}.d{j}, 3);
end
%%%%%%%%%%%%%%%%%%%%db保存的是误差对于bias基的导数%%%%%%%%%%%%%%%%%%%%
net.layers{l}.db{j} = sum(net.layers{l}.d{j}(:)) / size(net.layers{l}.d{j}, 3);
end
end
end
%%%%%%%%%%%%%%%%%%%%最后一层perceptron的gradient的计算%%%%%%%%%%%%%%%%%%%%
net.dffW = net.od * (net.fv)' / size(net.od, 2);
net.dffb = mean(net.od, 2);
function X = rot180(X)
X = flipdim(flipdim(X, 1), 2);
end
end
7. cnnapplygrads:
%函数名称:cnnapplygrads(),权值更新函数
%输入参数:net,权值待更新的卷积神经网络;opts,神经网络训练的相关参数
%输出参数:
%算法流程:先更新卷积层的参数,再更新全连接层参数
function net = cnnapplygrads(net, opts)
for l = 2 : numel(net.layers)
if strcmp(net.layers{l}.type, 'c')
for j = 1 : numel(net.layers{l}.a)
for ii = 1 : numel(net.layers{l - 1}.a)
%这里没什么好说的,就是普通的权值更新的公式:W_new = W_old - alpha * de/dW(误差对权值导数)
net.layers{l}.k{ii}{j} = net.layers{l}.k{ii}{j} - opts.alpha * net.layers{l}.dk{ii}{j};
end
net.layers{l}.b{j} = net.layers{l}.b{j} - opts.alpha * net.layers{l}.db{j};
end
end
end
net.ffW = net.ffW - opts.alpha * net.dffW;
net.ffb = net.ffb - opts.alpha * net.dffb;
end
本文为原创文章转载请注明出处,博主博客地址:http://blog.csdn.net/qq_20259459 和
作者( [email protected] )信息。