ElasticSearch分片不均匀,集群负载不均衡
ElasticSearch负载不均衡
某天晚上,服务器告警,发现服务器接口出现很多400,初步定为是ES服务器CPU达到了98%以上,ES日志出现了很多错误日志,具体如下:
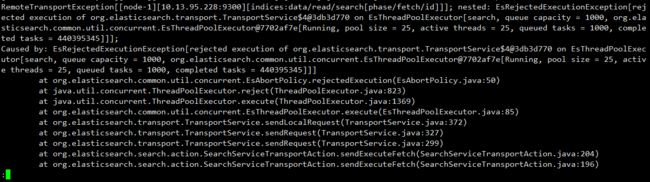
参考https://blog.csdn.net/wwd0501/article/details/78399943也就是Elasticsearch在并发查询量大的情况下,访问流量超过了集群中单个Elasticsearch实例的处理能力,Elasticsearch服务端会触发保护性的机制,拒绝执行新的访问,并且抛出EsRejectedExecutionException异常,通过观察ES集群发现了下面的几个问题:
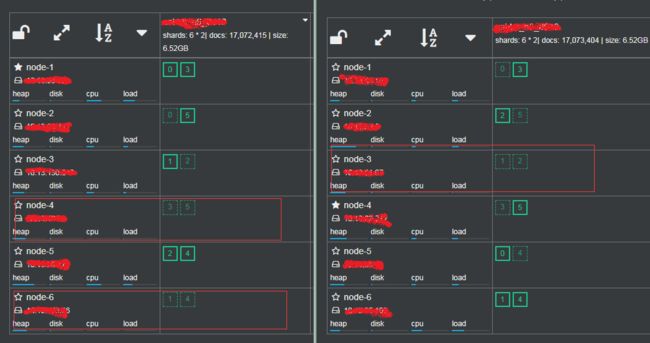
为什么会出现这个问题呢?通过这里面的步骤可以很容易的复现出这个问题。
(1) primary shard主副分片分布不均
primary true代表的是主数据,检索的时候从该分片拿,false是备份的副本,是做容错时的冗余数据。短信告警也是从10.13.95.228主节点开始而后10.23.28.177、10.13.28.197和10.13.130.248这几台出现的。
从上图看出两个集群中有三个节点中没有primaryshard,下图是第二个集群在傍晚时期CPU的使用率,后面两台是上面CPU都是0的node-4和node-6节点,也就是这两台完全没有计算能力,只是长期备份数据。
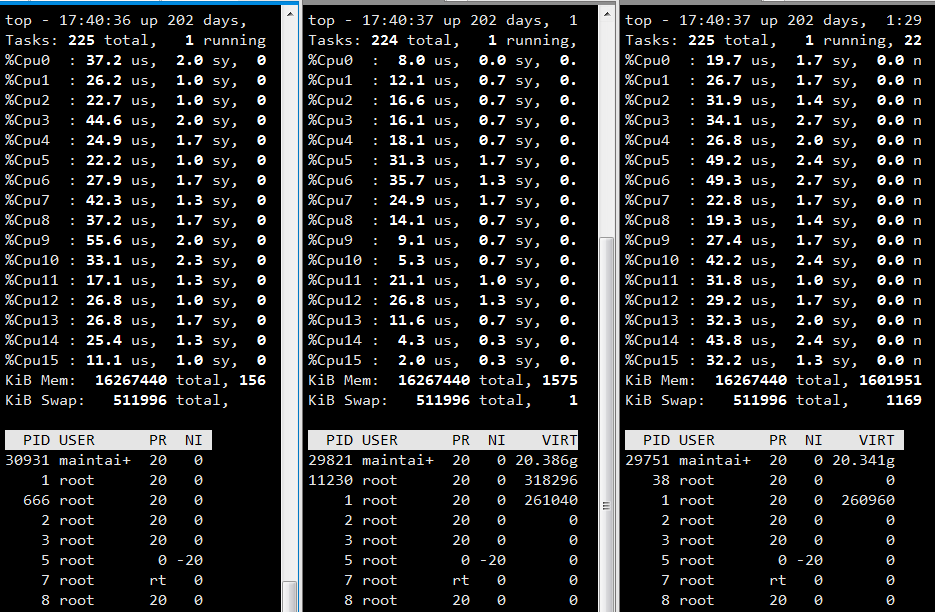
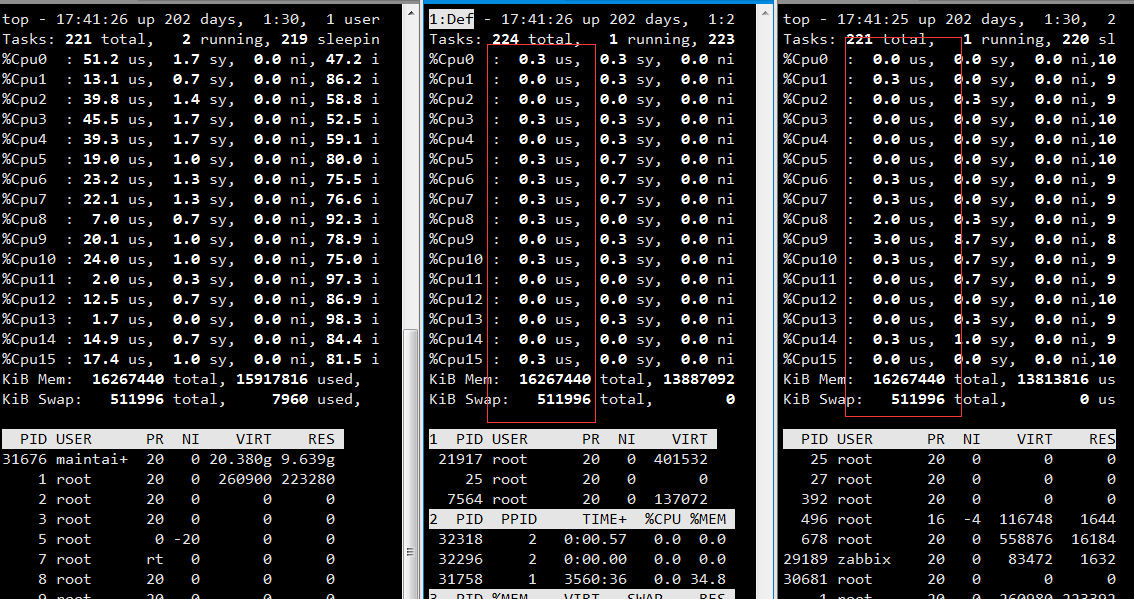
(2) master node既是master node又是data node
master node既要做数据检索,也要做集群的负载均衡转发器,导致每个集群的master node的CPU都很高,因此每次告警首先都是master node
解决方案
(1) 方案一:手动移动分片
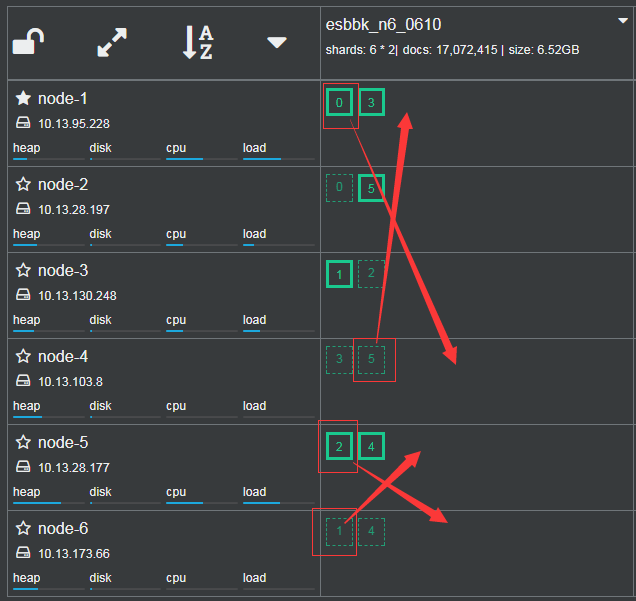
例如移动node-1的分片0到node-4
curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"move":{
"index":"indexName",
"shard":0,
"from_node":"node-1",
"to_node":"node-4"
}}]}'
优点:操作简单,恢复时间短;不必修改master node的配置,master node长期负载后高
缺点:索引大,移动时有很高的IO,索引容易损坏,需要做备份,不能解决master node既是数据节点又是负载均衡转发器的问题
注意:分片和副本无法移动到同一个节点
(2) 方案二:重建索引,从另外一个集群导入
删除原来的索引,重新建立索引,;利用elasticsearch dump等工具从另一个集群中把数据导入到新的索引中
优点:可以重新配置master node和data node,主从负载均匀
缺点:费时间,容易数据丢失,需要验证数据的一致性
开始操作
经过讨论,我们选了趁着月黑风高,我们选择了第一个方案,因为第一个方案操作起来比较简单,有经过本地的测试,风险也比较小。
然而理想很美好,现实确实很骨干,当天晚上一操作就出现了问题,载移动分片的过程中报了下面的错误:
{
"error" : {
"root_cause" : [
{
"type" : "remote_transport_exception",
"reason" : "[node-2][host:9301][cluster:admin/reroute]"
}
],
"type" : "illegal_argument_exception",
"reason" : "[move_allocation] can't move 1, from {node-2}{i5VJB-iSS_KNQnlxMxSJfA}{tif3N5vtTRuM-Z63C4cW5A}{host}{host:9301}, to {node-1}{j8h-FRjISRikUC8l8FTkMQ}{RNOZ2orcS36HGNk5m1CF3w}{host}{host:9300}, since its not allowed, reason: [YES(shard has no previous failures)][YES(shard is primary and can be allocated)][YES(explicitly ignoring any disabling of allocation due to manual allocation commands via the reroute API)][YES(target node version [6.2.2] is the same or newer than source node version [6.2.2])][YES(no snapshots are currently running)][YES(ignored as shard is not being recovered from a snapshot)][YES(node passes include/exclude/require filters)][YES(the shard does not exist on the same node)][YES(enough disk for shard on node, free: [84.6gb], shard size: [267.6kb], free after allocating shard: [84.6gb])][YES(below shard recovery limit of outgoing: [0 < 2] incoming: [0 < 2])][NO(too many shards [1] allocated to this node for index [indexName], index setting [index.routing.allocation.total_shards_per_node=2])][YES(allocation awareness is not enabled, set cluster setting [cluster.routing.allocation.awareness.attributes] to enable it)]"
},
"status" : 400
}
NO(too many shards [1] allocated to this node for index [indexName], index setting [index.routing.allocation.total_shards_per_node=2]意思是对于索引indexName,它的分片在该节点数量超过了它的配置index.routing.allocation.total_shards_per_node=2。在stackoverflow在发现了遇见了同样问题的人,可能是因为版本有点差异,所以异常信息可能有点不一样Too many shards on node for attribute: [rack], required per attribute: [1], node count: [2], leftover: [0]
看了一下这个应该就是集群的配置造成的,但是到elasticsearch.yml配置中确实没有找到该配置项,最后在无意中发现有人动态修改了集群的setting值,这个可以通过命令列出当前集群索引的配置:curl http://localhost:9200/_settings?pretty
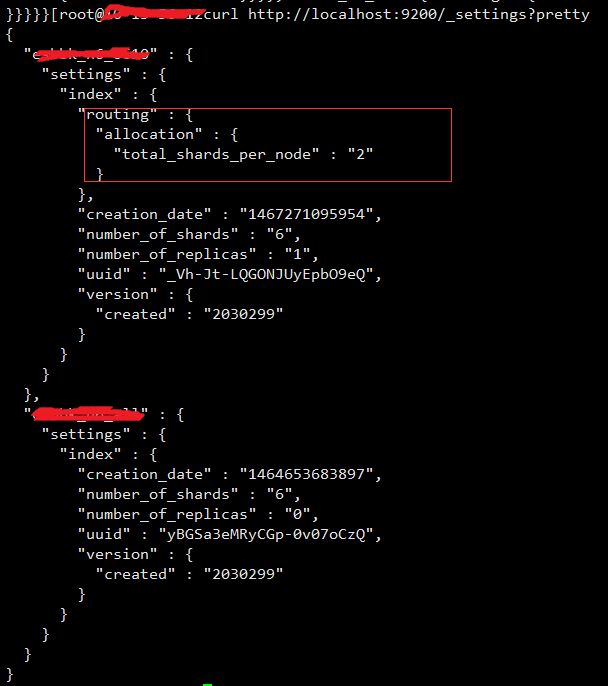
我们发现服务器集群配置了total_shards_per_node这个属性,并且该值的值为2,也就验证了上面的错误,该配置没配置在elasticsearch.yml配置文件中,elasticsearch可以通过settings动态修改索引的分片和副本数等一些配置,我们发现集群中total_shards_per_node配置了每个节点上允许的最多分片是2,然而我们在移动分片的时候需要某个节点在一段时间内允许同时存在三个分片,因此,我们需要修改该配置,修改此配置不需要重新启动集群,风险较小。
找到原因后,我们需要修改这个参数的值然后才能继续操作,修改这个值也很简单,直接一个curl命令就可以搞定:
curl -XPUT 'http://localhost:9200/esbbk_n6_0610/_settings' -d '{
"index.routing.allocation.total_shards_per_node":3
}'
修改完之后再查一次,这个值已经被修改为3,我们继续上面报错的步骤:
curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"move":{
"index":"indexName",
"shard":0,
"from_node":"node-1",
"to_node":"node-4"
}}]}'
省略...
ok,移动完成后主副分片分布正常,用测试环境做压测,集群负载也均衡,没有发生主分片再移动现象,如下:
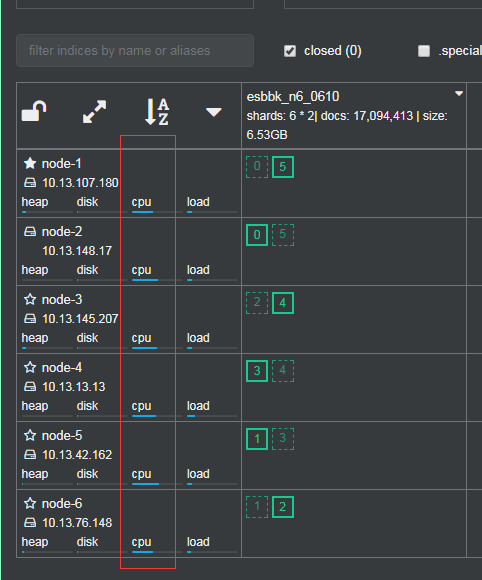
详细过程记录在个人github上