操作系统_学习日志_缓存
来写写一些看了很多遍才了解的东西吧。
以下大部分内容复制于:内存与缓存:https://wdxtub.com/2016/04/16/thin-csapp-3/,部分内容是我自己理解补充的。
理解高速缓冲存储器
高速缓存存储器(Cache Memory)是 CPU 缓存系统甚至是金字塔式存储体系中最有代表性的缓存机制,前面我们了解了许多概念,这一节我们具体来看看高速缓存存储器是如何工作的。
首先要知道的是,高速缓存存储器是由硬件自动管理的 SRAM 内存,CPU 会首先从这里找数据,其所处的位置如下(蓝色部分):
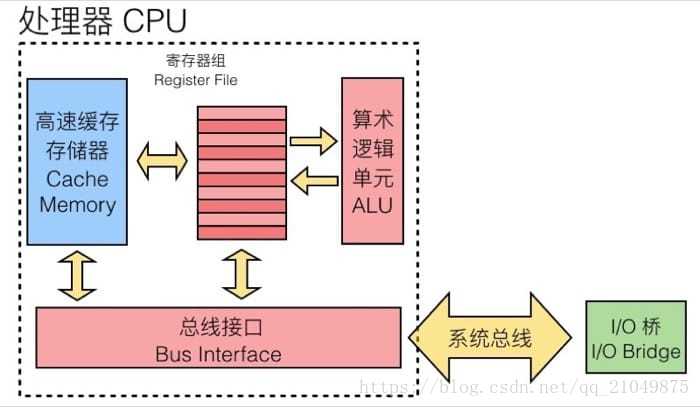
然后我们需要关注高速缓冲存储器的三个关键组成部分(注意区分大小写):
S 表示集合(set)数量
E 表示数据行(line)的数量
B 表示每个缓存块(block)保存的字节数目 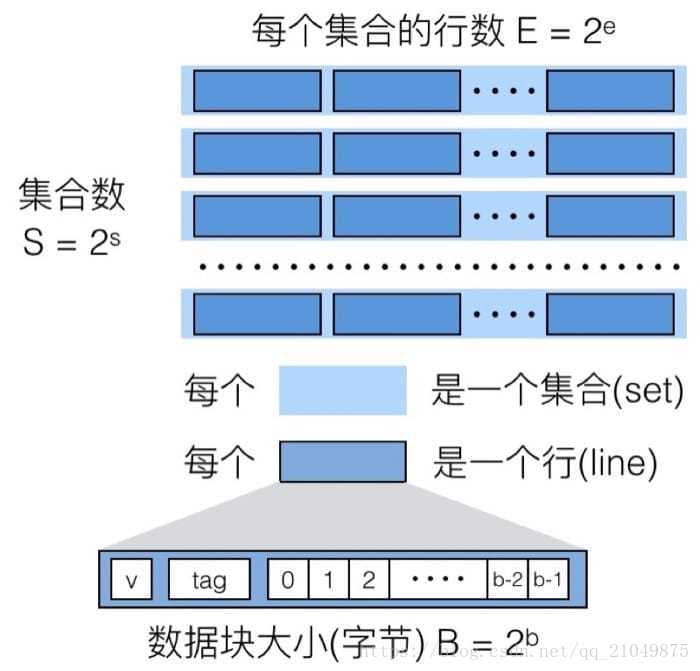
所以缓存中存放数据的空间大小为: C=SxExB
当处理器需要访问一个地址时,会先在高速缓冲存储器中进行查找,查找过程中我们首先在概念上把这个地址划分成三个部分:

读取
具体在从缓存中读取一个地址时,首先我们通过 set index 确定要在哪个 set 中寻找,确定后利用 tag 和同一个 set 中的每个 line 进行比对,找到 tag 相同的那个 line,最后再根据 block offset 确定要从 line 的哪个位置读起(这里的而 line 和 block 是一个意思)。
当 E=1 时,也就是每个 set 只有 1 个 line 的时候,称之为直接映射缓存(Direct Mapped Cache),如下图所示:
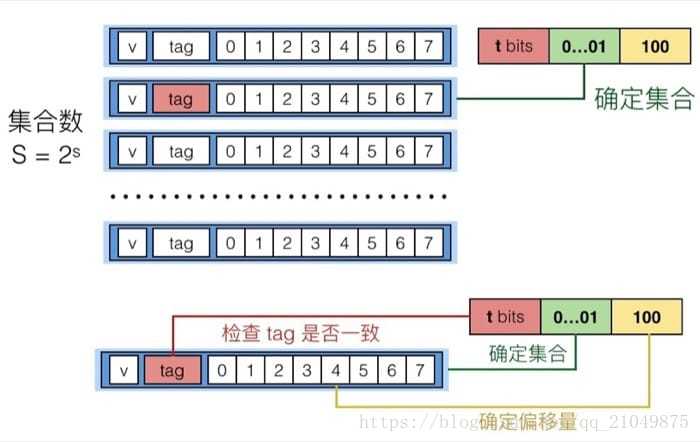
这种情况下,因为每个 set 对应 1 个 line,反过来看,1 个 line 就需要一个 set,所以 set index 的位数就会较多(和之后的多路映射对比)。具体的检索过程就是先通过 set index 确定哪个 set,然后看是否 valid,然后比较那个 set 里唯一 line 的 tag 和地址的 t bits 是否一致,就可以确定是否缓存命中。
命中之后根据 block offset 确定偏移量,因为需要读入一个 int,所以会读入 4 5 6 7 这四个字节(假设缓存是 8 个字节)。如果 tag 不匹配的话,这行会被扔掉并放新的数据进来。
这里个人补充一个内容:
下面的内容中,s:集合的索引,t:标记位数量,b:块偏移位数量,t:标记位数量,m:内存地址的位数。
其中s=log2(S),b=log2(B),t=m-(s+b)。
然后我们来看一个具体的例子,假设我们的寻址空间是 M=16 字节,也就是 m=4 位的地址,对应 B=2, S=4, E=1,则s=2,b=1,t=1我们按照如下顺序进行数据读取:
0 00 0, miss
0 00 1, hit
0 11 1, miss
1 00 0, miss
0 00 0, miss 缓存中的具体情况是,这里 x 表示没有任何内容。
ps:看到这得时候我就有些懵,因为前面看得不够认真所以就看不懂。
上面读入和下面的缓存状态意思是,当我们读取第一个0000(地址)的数据的时候,CPU会先去访问缓存,而0000地址对应的是tag=0,访问的是Set 0,访问数据块的偏移量b=0,因为在缓存中Set 0之前没有存入这数据,所以造成miss,然后就在缓存中,也就是在Set 0中更新,就出现了下面Set状态表的第一行。
当再次读入0001地址的时候,即和第一个地址相同,然后就hit。
再然后读取0111,此时访问的是Set 3,缓存中没有存有,所以在Set 3中更新了。
接下来读取1000,访问的是Set 0,tag=1与之前的不匹配,所以再次更新Set 0中的数据行,变成:Set 0 1 1 M[0-1].
再然后读取0000,又因为不匹配,就替换了.
这里我们就可以看出E=1直接映射缓存的坏处,若我们不是进行连续地址的访问,就可能效率很慢,一直没命中缓存,造成缓存大部分的更新。
v Tag Block
Set 0 1 0 M[0-1]
Set 1 x x x
Set 2 x x x
Set 3 1 0 M[6-7] 缓存的大小如图所示,对应就是有 4 个 set,所以需要 2 位的 set index,所以进行读入的时候,会根据中间两位来确定在哪个 set 中查找,其中 8 和 0,因为中间两位相同,会产生冲突,导致连续 miss,这个问题可以用多路映射来解决。
当 E 大于 1 时,也就是每个 set 有 E 个 line 的时候,称之为 E 路联结缓存。这里每个 set 有两个 line,所以就没有那么多 set,也就是说 set index 可以少一位(集合数量少一倍)。
再简述一下整个过程,先从 set index 确定那个 set,然后看 valid 位,接着利用 t bits 分别和每个 line 的 tag 进行比较,如果匹配则命中,那么返回 4 5 位置的数据,如果不匹配,就需要替换,可以随机替换,也可以用 least recently used(LRU) 来进行替换。
我们再用刚才的例子来看看是否会增加命中率,这里假设我们的寻址空间是 M=16 字节,也就是 4 位的地址,对应 B=2, S=2, E=2,我们按照如下顺序进行数据读取:
0 00 0, miss
0 00 1, hit
0 11 1, miss
1 00 0, miss
0 00 0, hit缓存中的具体情况是,这里 x 表示没有任何内容
v Tag Block
Set 0 1 00 M[0-1]
Set 0 1 10 M[8-9]
Set 1 1 01 M[6-7]
Set 1 0 x x 可以看到因为每个 set 有 2 个 数据行,所以只有 2 个 set,set index 也只需要 1 位了,这个情况下即使 8 和 0 的 set index 一致,因为一个 set 可以容纳两个数据,所以最后一次访问 0,就不会 miss 了。
PS:看到这里,我大概能理解为什么缓存是很小,而有能够快速访问数据的原因了。
写入
在整个存储层级中,不同的层级可能会存放同一个数据的不同拷贝(如 L1, L2, L3, 主内存, 硬盘)。如果发生写入命中的时候(也就是要写入的地址在缓存中有),有两种策略:
Write-through: 命中后更新缓存,同时写入到内存中
Write-back: 直到这个缓存需要被置换出去,才写入到内存中(需要额外的 dirty bit 来表示缓存中的数据是否和内存中相同,因为可能在其他的时候内存中对应地址的数据已经更新,那么重复写入就会导致原有数据丢失)
在写入 miss 的时候,同样有两种方式:
Write-allocate: 载入到缓存中,并更新缓存(如果之后还需要对其操作,这个方式就比较好)
No-write-allocate: 直接写入到内存中,不载入到缓存
这四种策略通常的搭配是:
Write-through + No-write-allocate
Write-back + Write-allocate
其中第一种可以保证绝对的数据一致性,第二种效率会比较高(通常情况下)。