Spark Streaming实时流处理项目7——Spark Streaming实战2
Spark Streaming实时流处理项目1——分布式日志收集框架Flume的学习
Spark Streaming实时流处理项目2——分布式消息队列Kafka学习
Spark Streaming实时流处理项目3——整合Flume和Kafka完成实时数据采集
Spark Streaming实时流处理项目4——实战环境搭建
Spark Streaming实时流处理项目5——Spark Streaming入门
Spark Streaming实时流处理项目6——Spark Streaming实战1
Spark Streaming实时流处理项目7——Spark Streaming实战2
Spark Streaming实时流处理项目8——Spark Streaming与Flume的整合
Spark Streaming实时流处理项目9——Spark Streaming整合Kafka实战
Spark Streaming实时流处理项目10——日志产生器开发并结合log4j完成日志的输出
Spark Streaming实时流处理项目11——综合实战
源码
案例四:Spark Streaming实战之窗口函数的使用:
窗口机制:定时的进行一个时间段内的数据处理,时间段可以重叠,看下图:
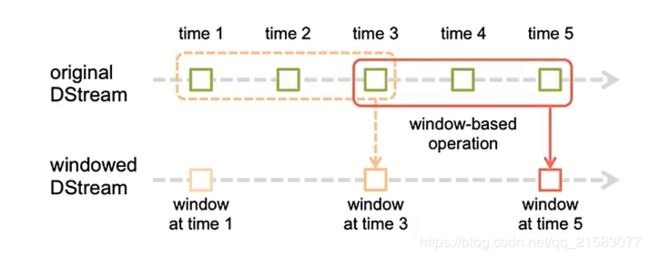
window length :窗口的长度,上图中窗口的长度为3;
window interval:窗口的间隔,上图中窗口间隔是2.
这两个参数和之前提到的batch size是有倍数关系的。使用window我们可以每隔多久计算某个范围内的数据,例如,我们可以每隔10秒计算一次前10分钟内的数据(数据肯定是会有重叠)。
/ Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))案例五:Spark Streaming实战之黑名单过滤:
需求:从数据流中过滤掉指定的数据
假如有如下访问日志(DStream):
20180808,zhangsan
20180808,lisi
20180808,wangwu
黑名单表(RDD):
zhangsan
lisi
过滤掉黑名单里面的人名之后,就只输出 20180808,wangwu
思路:
首先对访问日志(DStream)作如下操作:
==> (zhangsan:20180808,zhangsan)(lisi:20180808,lisi)(wangwu:20180808,wangwu)写成key-value形式,key是姓名,value是原访问日志
然后再对黑名单(RDD)也做类似操作:
==>(zhansan:true)(lisi:true)
再然后,我们使用leftjoin,得到如下结果:
(zhangsan:[<20180808,zhangsan>,
(lisi:[<20180808,lisi>,
(wangwu:[<20180808,wangwu>,
最后只需要过滤第二个为true的,剩下的就是我们想要的结果了。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @author YuZhansheng
* @desc 黑名单过滤
* @create 2019-02-20 15:33
*/
object TransformApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("TransformApp")
//创建StreamingContext需要两个参数:SparkConf和batch interval
val ssc = new StreamingContext(sparkConf,Seconds(5))
//构建黑名单
val blacks = List("zhangsan","lisi")
val blacksRDD = ssc.sparkContext.parallelize(blacks).map(x=>(x,true))
val lines = ssc.socketTextStream("localhost",6789)
val clicklog = lines.map(x => (x.split(",")(1),x)).transform(rdd => {
rdd.leftOuterJoin(blacksRDD)
.filter(x => x._2._2.getOrElse(false) != true)
.map(x => x._2._1)
})
clicklog.print()
ssc.start()
ssc.awaitTermination()
}
}
测试:在客户端使用nc -lk 6789命令,发送数据,看控制台打印出的结果验证。
案例六:Spark Streaming整合SparkSQL 完成词频统计操作
先添加依赖
org.apache.spark
spark-sql_2.11
${spark.version}
import java.beans.Transient
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
/**
* @author YuZhansheng
* @desc Spark Streaming整合SparkSQL 完成词频统计操作
* @create 2019-02-20 16:03
*/
object SqlNetworkWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("SqlNetworkWordCount")
//创建StreamingContext需要两个参数:SparkConf和batch interval
val ssc = new StreamingContext(sparkConf,Seconds(5))
val lines = ssc.socketTextStream("localhost",6789)
val words = lines.flatMap(_.split(" "))
words.foreachRDD { (rdd:RDD[String],time:Time) =>
val spark = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
import spark.implicits._
val wordsDataFrame = rdd.map(w => Record(w)).toDF()
wordsDataFrame.createOrReplaceTempView("words")
val wordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word")
println(s"======= $time =======")
wordCountsDataFrame.show()
}
ssc.start()
ssc.awaitTermination()
}
case class Record(word:String)
object SparkSessionSingleton{
@Transient private var instance:SparkSession = _
def getInstance(sparkConf: SparkConf):SparkSession = {
if (instance == null){
instance = SparkSession
.builder()
.config(sparkConf)
.getOrCreate()
}
instance
}
}
}
测试:在客户端使用nc -lk 6789命令,发送数据,看控制台打印出的结果验证。
+----+-----+
|word|total|
+----+-----+
| ds| 2|
| e| 1|
| d| 1|
| a| 2|
| as| 1|
+----+-----+
(这个案例运行时打印的日志会比较多噢。)