Android ThreadLocal 源码分析
1.为啥 说是Android ThreadLocal ,而不是java ThreadLocal,因为Android 对它进行了 优化.优化地方:内存复用,使用弱引用解决内存泄漏.而且他们处理方式也不同Java 使用类来包裹 key和value的.使用魔数0x61c88647, 计算得到的索引值偶数和奇数之间不断切换.而Android 只是在偶数索引index 存放key ,index+1来存放值.魔数为0x61c88647*2 得到的索引值都是偶数,非常适合它的处理方式.
2.从使用来分析源码.
ThreadLocal3.ThreadLocal对象的创建:
public ThreadLocal() {}
就一个空构造 ,那么创建对象都做了什么呢,那就看它成员属性了.
/** Weak reference to this thread local instance. */
private final Reference> reference
= new WeakReference>(this);
//弱引用持有它,有利于回收,防止内存泄漏.如果他为null时它所在的存放数组索引的地方将被设置为TOMBSTONE 对象,value所在的地方设置为null,不在持有它对象也有利于回收.下一个ThreadLocal 对象set时.如果找到数组存放的索引,而且在这个索引数组里面的对象为TOMBSTONE将会被替换成这个.从而达到内存复用.
/** Hash counter. */
private static AtomicInteger hashCounter = new AtomicInteger(0);
/**
* Internal hash. We deliberately don't bother with #hashCode().
* Hashes must be even. This ensures that the result of
* (hash & (table.length - 1)) points to a key and not a value.
*
* We increment by Doug Lea's Magic Number(TM) (*2 since keys are in
* every other bucket) to help prevent clustering.
*/
private final int hash = hashCounter.getAndAdd(0x61c88647 * 2);
为啥使用0x61c88647 防止集中,为啥*2 因为key 所在的索引为偶数.第一次计算时hash 为零.也就是第一次创建ThreadLocal key 必然在0索引.然后系统已经使用了n次(hashCounter 为静态...). 主线程存放的对象
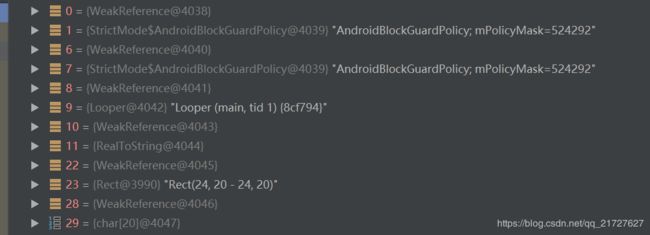
其中Looper最为熟悉.
3.get()方法
public T get() {
// Optimized for the fast path.
Thread currentThread = Thread.currentThread();
//value 是从线程对象 localValues 成员属性取出来的中,所以不同线程有不同value, 就是有不同的副本.
Values values = values(currentThread);
if (values != null) {
Object[] table = values.table;
int index = hash & values.mask;
// 尝试从第一次计算hash 得到索引取值,如果key 等于 将执行getAfterMiss 方法.一般都存在第一次计算得到索引的地方
if (this.reference == table[index]) {
return (T) table[index + 1];
}
} else {
//初始化数组
values = initializeValues(currentThread);
}
return (T) values.getAfterMiss(this);
}
Object getAfterMiss(ThreadLocal key) {
Object[] table = this.table;
int index = key.hash & mask;
// If the first slot is empty, the search is over.
//如果第一次存放的索引都为null ,那么必然没有set过数据
if (table[index] == null) {
Object value = key.initialValue();//默认是null
// If the table is still the same and the slot is still empty...
// 看到这里挺懵圈的,为啥这样判断呢.在同一个线程是串行执行的,不应该table 发生变化才对(并发问题)
// 直到看 这句话The table changed during initialValue() 就突然明白,如果继承重写initialValue方法在里面set 是不是有可能发生扩容,扩容时索引可能发生偏移.
if (this.table == table && table[index] == null) {
table[index] = key.reference;
table[index + 1] = value;
size++;
//扩容或者检查key 是否被回收
cleanUp();
return value;
}
// The table changed during initialValue().
// 当发生扩容时 就要重新遍历索引了
put(key, value);
return value;
}
// Keep track of first tombstone. That's where we want to go back
// and add an entry if necessary.
int firstTombstone = -1;
// Continue search.
// 如果不为空 那就继续遍历 而遍历的范围永远都在0-table.length-1 之间,而且必然是偶数
for (index = next(index);; index = next(index)) {
Object reference = table[index];
if (reference == key.reference) {
return table[index + 1]; //找到就返回
}
// If no entry was found...
// 这里的逻辑跟上面差不多的
if (reference == null) {
Object value = key.initialValue();
// If the table is still the same...
if (this.table == table) {
// If we passed a tombstone and that slot still
// contains a tombstone...
if (firstTombstone > -1
&& table[firstTombstone] == TOMBSTONE) {
//这里内存复用
table[firstTombstone] = key.reference;
table[firstTombstone + 1] = value;
tombstones--;
size++;
// No need to clean up here. We aren't filling
// in a null slot.
return value;
}
// If this slot is still empty...
if (table[index] == null) {
table[index] = key.reference;
table[index + 1] = value;
size++;
cleanUp();
return value;
}
}
// The table changed during initialValue().
put(key, value);
return value;
}
if (firstTombstone == -1 && reference == TOMBSTONE) {
// Keep track of this tombstone so we can overwrite it.
// 为啥不把 table[firstTombstone] = key.reference...这些语句 放到这里来执行呢.万一后面还有 //reference ==key.reference就不就重复了吗
firstTombstone = index;
}
}
}
4.cleanUp():扩容或者回收标记(设置TOMBSTONE)
private void cleanUp() {
// 检查是否扩容
if (rehash()) {
// If we rehashed, we needn't clean up (clean up happens as
// a side effect).
return;
}
//数量为0 那就没有必要进行回收标记了
if (size == 0) {
// No live entries == nothing to clean.
return;
}
// Clean log(table.length) entries picking up where we left off
// last time.
//这里要从上一次的位置开始检查,为什么呢 因为遍历次数为log2Table.length ,不能完全遍历完,索引需要记录上一次位置才能 完全遍历完.
int index = clean;
Object[] table = this.table;
for (int counter = table.length; counter > 0; counter >>= 1,
index = next(index)) {
Object k = table[index];
if (k == TOMBSTONE || k == null) { //已经标记跳过
continue; // on to next entry
}
// The table can only contain null, tombstones and references.
@SuppressWarnings("unchecked")
Reference> reference
= (Reference>) k;
if (reference.get() == null) {
// This thread local was reclaimed by the garbage collector.
table[index] = TOMBSTONE; //有利于回收
table[index + 1] = null;
tombstones++;
size--;
}
}
// Point cursor to next index.
clean = index;//记录
}
private boolean rehash() {
if (tombstones + size < maximumLoad) {
return false;
}
int capacity = table.length >> 1;
int newCapacity = capacity;
//当数量大于四分之一时 在扩容两倍 .而当数量大于2分之1 getAndAdd() 才会获得 0索引,后面获取的索引会跟之前一样(测试过).所以1/3 或者1/4 扩容都可以.也就是说在1/3 或者1/4之前获取 索引值是不冲突 ,在set 时用遍历有点想不通.
if (size > (capacity >> 1)) {
// More than 1/2 filled w/ live entries.
// Double size.
newCapacity = capacity * 2;
}
Object[] oldTable = this.table;
// Allocate new table.
initializeTable(newCapacity);
// We won't have any tombstones after this.
this.tombstones = 0;
// If we have no live entries, we can quit here.
if (size == 0) {
return true;
}
// Move over entries.
//既然索引不冲突 向后或者向前遍历都没有关系
for (int i = oldTable.length - 2; i >= 0; i -= 2) {
Object k = oldTable[i];
if (k == null || k == TOMBSTONE) {
// Skip this entry.
continue; //这里回收标记已经不用管了,因为创建了新的数组,所以上面this.tombstones = 0
}
// The table can only contain null, tombstones and references.
@SuppressWarnings("unchecked")
Reference> reference
= (Reference>) k;
ThreadLocal key = reference.get();
if (key != null) {
// Entry is still live. Move it over.
add(key, oldTable[i + 1]); // 找到位置添加进去就行了
} else {
// The key was reclaimed.
size--;
}
}
return true;
} 5.set(...) 方法:
直接贴vaules.put..
void put(ThreadLocal key, Object value) {
cleanUp();//说过
int firstTombstone = -1;
//getAfter 部分代码差不多 ,唯一比较不理解的是既然索引不冲突 ,是否直接用 key.hash & mask就得了?为啥还遍历?
for (int index = key.hash & mask;; index = next(index)) {
Object k = table[index];
if (k == key.reference) {
// Replace existing entry.
table[index + 1] = value;
return;
}
if (k == null) {
if (firstTombstone == -1) {
// Fill in null slot.
table[index] = key.reference;
table[index + 1] = value;
size++;
return;
}
// Go back and replace first tombstone.
table[firstTombstone] = key.reference;
table[firstTombstone + 1] = value;
tombstones--;
size++;
return;
}
// Remember first tombstone.
if (firstTombstone == -1 && k == TOMBSTONE) {
firstTombstone = index;
}
}
}ps.终于知道为啥要遍历了,因为 static AtomicInteger hashCounter 那么 在另一个线程创建多个Threadlocal 对象,在返回主线程创建就可能出现索引冲突.怪不得自己计算的索引值跟上面的图不一样.