prometheus的简单安装以及使用
下载你想安装的prometheus版本,地址为download prometheus
解压
tar xvfz prometheus-*.tar.gz
cd prometheus-*配置监控对象(本文现在配置的监控对象是prometheus本身)
root@fabric-cli prometheus-2.2.1.linux-amd64]# ls -l
总用量 108100
drwxrwxr-x 2 1000 1000 38 3月 14 22:14 console_libraries
drwxrwxr-x 2 1000 1000 173 3月 14 22:14 consoles
-rw-rw-r-- 1 1000 1000 11357 3月 14 22:14 LICENSE
-rw-rw-r-- 1 1000 1000 2769 3月 14 22:14 NOTICE
-rwxr-xr-x 1 1000 1000 66176282 3月 14 22:17 prometheus
-rw-rw-r-- 1 1000 1000 928 3月 14 22:14 prometheus.yml
-rwxr-xr-x 1 1000 1000 44492910 3月 14 22:18 promtool从prometheus.yml配置文件的内容可以看出,该配置文件就是让prometheus监控自己
关于配置文件的详细说明请参考prometheus configuration
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: ' prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']启动prometheus服务
[root@fabric-cli prometheus-2.2.1.linux-amd64]# ./prometheus --config.file="prometheus.yml"
level=info ts=2018-05-04T02:05:15.984674897Z caller=main.go:220 msg="Starting Prometheus" version="(version=2.2.1, branch=HEAD, revision=bc6058c81272a8d938c05e75607371284236aadc)"
level=info ts=2018-05-04T02:05:15.984789564Z caller=main.go:221 build_context="(go=go1.10, user=root@149e5b3f0829, date=20180314-14:15:45)"
level=info ts=2018-05-04T02:05:15.984816024Z caller=main.go:222 host_details="(Linux 3.10.0-693.21.1.el7.x86_64 #1 SMP Wed Mar 7 19:03:37 UTC 2018 x86_64 fabric-cli (none))"
level=info ts=2018-05-04T02:05:15.984841453Z caller=main.go:223 fd_limits="(soft=1024, hard=4096)"
level=info ts=2018-05-04T02:05:15.997654037Z caller=main.go:504 msg="Starting TSDB ..."
level=info ts=2018-05-04T02:05:16.00942241Z caller=web.go:382 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2018-05-04T02:05:16.015855882Z caller=main.go:514 msg="TSDB started"
level=info ts=2018-05-04T02:05:16.015894187Z caller=main.go:588 msg="Loading configuration file" filename=prometheus.yml
level=info ts=2018-05-04T02:05:16.017592228Z caller=main.go:491 msg="Server is ready to receive web requests."
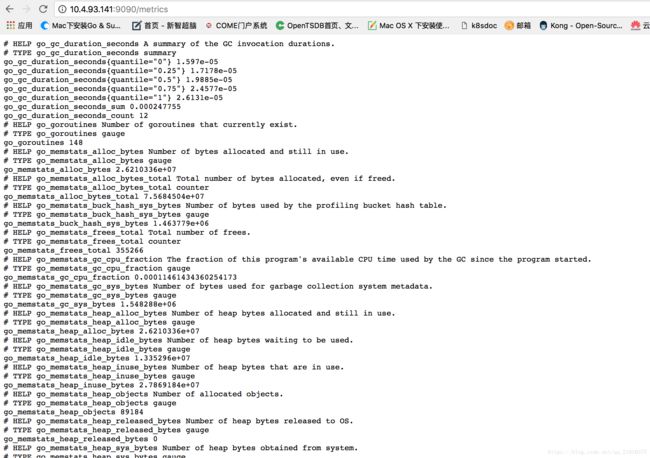
通过访问http://10.4.93.141:9090/metrics,可以查看搜集的性能指标
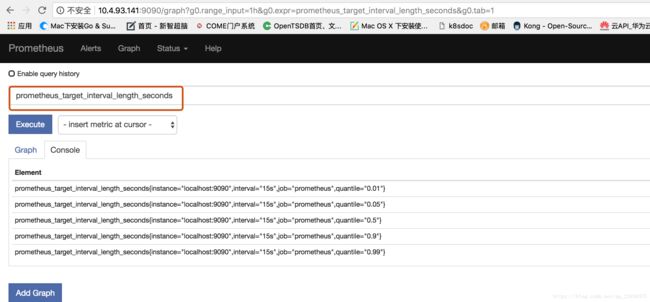
访问http://10.4.93.141:9090/graph可以查看图形界面
执行prometheus_target_interval_length_seconds,查看实际采集的时间
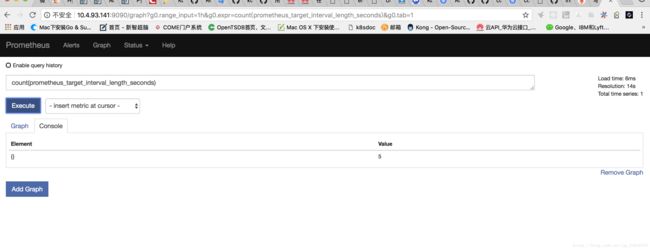
查看请求的数量count(prometheus_target_interval_length_seconds)
查看更多的表达式,请参考expression language documentation
启动简单的实例
git clone https://github.com/prometheus/client_golang.git
cd client_golang/examples/random
go get -d
go build
# 启动
./random -listen-address=:8080 &
./random -listen-address=:8081 &
./random -listen-address=:8082 &修改prometheus.yml文件
[root@fabric-cli prometheus-2.2.1.linux-amd64]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: 'example-random'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:8080', 'localhost:8081']
labels:
group: 'production'
- targets: ['localhost:8082']
labels:
group: 'canary'
执行rpc_durations_seconds

配置收集规则
avg(rate(rpc_durations_seconds_count[5m])) by (job, service)创建文件搜集规则文件prometheus.rules.yml
[root@fabric-cli prometheus-2.2.1.linux-amd64]# cat prometheus.rules.yml
groups:
- name: example
rules:
- record: job_service:rpc_durations_seconds_count:avg_rate5m
expr: avg(rate(rpc_durations_seconds_count[5m])) by (job, service)修改配置文件prometheus.yml
[root@fabric-cli prometheus-2.2.1.linux-amd64]# cat prometheus.yml
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # Evaluate rules every 15 seconds.
# Attach these extra labels to all timeseries collected by this Prometheus instance.
external_labels:
monitor: 'codelab-monitor'
rule_files:
- 'prometheus.rules.yml'
scrape_configs:
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'example-random'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:8080', 'localhost:8081']
labels:
group: 'production'
- targets: ['localhost:8082']
labels:
group: 'canary'
重新启动prometheus服务
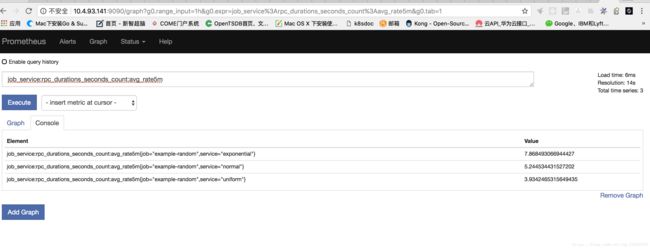
执行job_service:rpc_durations_seconds_count:avg_rate5m表达式
参考:
getting_started
END
https://blog.csdn.net/yevvzi/article/details/79561150
infludb集群安装
https://www.cnblogs.com/tianqing/p/7153023.html