Transfomer
代码:https://www.github.com/kyubyong/transformer
重点解读:https://jalammar.github.io/illustrated-transformer/

全连接层:重新拟合,减少特征信息的损失
seq2seq
http://www.51ui.cn/66/829571/
编码器,按照顺序处理源句,得到一个描述(representation)向量。
然后解码器利用这个描述,来翻译出整个句子。
然而这导致了信息的大量丢失,特别是对一些长的句子,和有不同语序的语言对。
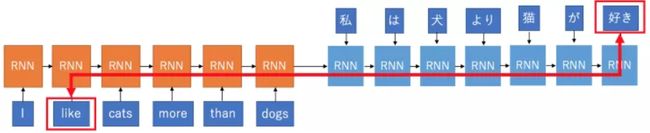
把 “like” 翻译成 “好き(suki)”:得经历很长的距离,这中间会混入噪音,还会丢失有用信息,所以很难翻译准确。
即使之后,加了部分注意力机制来辅助翻译,也会因为对关系的捕捉不足,而出现翻译失误。
翻译任务中,需要发现的关系有三种:源句内部的关系;目标句内部的关系;源句和目标句之间的关系。
seq2seq 只在捕捉源句和目标句之间关系用注意力机制进行了捕捉,而源句内部和目标句内部还是在用 RNN,从一边到另一边来捕捉关系,但这样并不够直接,特别是对一些距离远的关系捕捉很差。
除了对远距离关系难以学习的不足以外,RNN默认是按时序来进行处理的,所以得一个个词从左到右看过去,再逐词生成翻译。这样导致 RNN 不能像 CNN 一样,充分利用 GPU 的并行运算优势。
attention机制
先用 query 和所有的 keys 值相乘(也能用其他一些运算),于是每个 key 都能得到一个值,看做是每个 key 的权重,为了使得权重加起来等于1,这里需要用 softmax 压一下得到注意力评分(attention score);最后用评分和相对应的 value 值相乘,决定哪个 value 比较重要,再相加,就得到想要的注意力向量了。

transformer block
https://mp.weixin.qq.com/s?__biz=MzU3NTY3MTQzMg==&mid=2247484373&idx=1&sn=7165d95ac89f2651a8b761cb5f29df20&chksm=fd1ede32ca69572470a8f0ce917ff6ca5546fc437fd42022123eccb073a8fe3472fcbe72bfd7&mpshare=1&scene=23&srcid=0212NjRB7t6jYTBDdwlF1o9a#rd
 将6个编码器堆叠在一起,每一个解码器连接至编码器???
将6个编码器堆叠在一起,每一个解码器连接至编码器???
embedding:每个单词都嵌入到512维的向量(最长的句子长度)中。
底部的编码器接收的是词嵌入,但其他编码器接收的则是其下方的编码器的输出。
encoder
一旦定义了输出词汇,我们就可以使用相同宽度的向量来表示词汇表中的每个单词,这被称为one-hot编码。
编码器输入首先经过self-attention层:对特定单词编码时,可以帮助编码器查看输入语句中的其他单词,以确定具体的语境(Transformer用self-attention将其他相关单词的“理解“融入到目前正在处理的单词中)。
Self-attention层所输出的内容(multi-head attention:Transformer使用8个attention heads,为每个编码器/解码器设置了8组矩阵,每组都是随机初始化的。在训练之后,每组被用于将输入的词嵌入(或者低层编码器/解码器的向量)投入到不同的表示子空间。用不同的权重矩阵做8次不同的计算,最终就能得到8个不同的Z矩阵。将8个矩阵合并,然后让它们和一个额外的权重矩阵W0相乘)会被输入到前馈神经网络层。完全相同的前馈神经网络会分别应用于每个编码器中,最后输出到下一个编码器。
每个位置的单词在编码器中沿着自己的路径流动。在self-attention层中,这些路径之间存在依赖关系。由于前馈层中不存在依赖关系,因此各种路径在经过前馈层时可以并行执行。

 假设我们要计算第一个单词“Thinking”的self-attention得分。我们需要根据这个单词为输入语句中的每个词打分,这个分数决定了当我们在编码某一位置的单词时对输入语句的其他部分投入多少关注度。Softmax的结果决定了每个单词的在这一位置的权重,显然,在这个位置上的单词将获得最高的softmax得分,但有时也需要注意与当前单词相关的词汇。
假设我们要计算第一个单词“Thinking”的self-attention得分。我们需要根据这个单词为输入语句中的每个词打分,这个分数决定了当我们在编码某一位置的单词时对输入语句的其他部分投入多少关注度。Softmax的结果决定了每个单词的在这一位置的权重,显然,在这个位置上的单词将获得最高的softmax得分,但有时也需要注意与当前单词相关的词汇。
decoder
 在解码阶段,每一步都输出一个输出序列的元素(翻译后的单词)。每一步的输出都会在下一个步骤时被反馈到底层解码器,并且解码器也和编码器一样,将输出结果向更高层传递。正如我们对编码器输入所操作的那样,我们嵌入并添加位置编码到那些解码器输入中去,以表明每个单词的位置。
在解码阶段,每一步都输出一个输出序列的元素(翻译后的单词)。每一步的输出都会在下一个步骤时被反馈到底层解码器,并且解码器也和编码器一样,将输出结果向更高层传递。正如我们对编码器输入所操作的那样,我们嵌入并添加位置编码到那些解码器输入中去,以表明每个单词的位置。
在解码器中,self-attention仅被允许关注到输出序列中较前的位置,在self-attention计算的softmax步骤前通过用掩码mask遮罩序列后面的位置(将它们设置为负无穷)。
假设我们的模型通过训练数据学习到10000个不同的英文单词(即我们模型的“输出词汇”)。那么logits向量就有10000个维度,每个维度对应每个单词的分数。
然后,Softmax层将这些分数转化为概率(全都是正数,并且相加等于1)。选择概率最大的维度,并且与之关联的词汇将在这一步中输出。
loss function
假设我们的第一步是用一个简单的例子进行训练——将“merci”翻译为“thanks”。这意味着,我们希望输出的是表示单词”thanks“的概率分布。但由于这个模型没有经过充分的训练,因此这目前还不可能发生。
由于模型的参数是随机初始化的,未经训练的模型对每个单词的任意值产生概率分布。我们可以将其与实际输出进行比较(交叉熵、KL散度),然后使用反向传播调整所有模型的权重,使输出更接近所需的输出。
实际上,我们会使用一个句子而非一个单词。比如,输入“je suis étudiant”,期望输出“I am a student”。这意味着,我们想要我们的模型连续地输出概率分布,其中:每个概率分布由一个维度等于词汇表大小的向量来表示;第一个概率分布中概率最大的是与”I”相关的维度;第二格概率分布中概率最大的是与”am“相关的维度;一直重复输出,直到输出的概率分布显示的符号。

现在,因为模型每次只能产生一个输出:假设模型从概率分布中选择了最大概率的单词,并舍弃掉其他单词。这是一种方法(称为贪婪解码)。另外一种方法是选择概率第一第二大的单词(比如,“I”和“a”),然后下一步运行模型两次:第一次假设第一个输出位置的单词为“I”,第二次假设第一个输出位置的单词是“me”,哪个版本的错误更少就保留那一版本的位置1和2。继续重复操作来确定后续的位置。这一方法被称为“beam search”,在我们的例子中beam_size是2(因为我们在计算了位置1和位置2的beams之后比较了结果),top_beam也是2(因为我们保留了2个单词)。你可以对这两个超参数进行实验。
文件集合
hyperparams.py
prepro.py
data_load.py
modules.py
train.py
eval.py
关键步骤(德语-》英语)
1. 定义超参数
1.1 源语言、目标语言的训练数据和测试数据的路径
1.2 batch大小(32)、初始learning rate(0.0001,In paper, learning rate is adjusted to the global step)、日志目录
1.3 最大词长度(T=10)、min_cnt(words whose occurred less than min_cnt are encoded as )、hidden_units(C=512)、num_blocks、num_heads、num_epochs(20)、dropout(0.1)、sinusoid(If True, use sinusoid. If false, positional embedding.)
2. 预处理
目的:生成源语言和目标语言的词汇文件。
2.1 生成德语文件、英语文件
2.1.1 用“”替换掉非空白字符或latin的
2.1.2 按空字符(空格、\n、\t)分割成word
2.1.3 计数,返回字典(key:词; value:次数)
2.1.4 预处理文件保存:
①设置了四个特殊的标记符号PAD、UNK、S、/s,把他们设定为出现次数很多放在文件的最前。
②依词出现的频率将训练集中出现的词和其对应的计数保存。
3. 加载德语\英语词汇文件为字典数组
3.1 读取预处理prepro.py中生成的词汇文件进数组,去掉出现次数少于hp.min_cnt=20的词
3.2 枚举数组元素及下标,返回两个字典(word:id; id:word)
4. 构建图graph类
4.1 定义Graph类:所有图中定义的节点和操作都以这个为默认图。
4.1.1 设置使用tf默认图
4.1.2 训练:get_batch_data()得到满足最大长度的训练数据以及batch的数量。
4.1.2.1 生成句子列表:读取源、目标文件,\n分隔开每一行,选择那些那些行开头符号不是‘<’的句子(’<’:数据描述的行)、并用“”代替非空白或latin的。
4.1.2.2 双语字典生成。
4.1.2.3 用字典中id表示句子列表,生成id表示的等长句子列表,并返回合法id句子(x_list\y_list\Sources\Targets)
①若该word不在字典中则id用1代替(即UNK的id), 加表示句子末尾。
②对句子长度<=最大长度hp.maxlen合法句子:连接到x_list\y_list\Sources\Targets.
③对小于最大长度id句子pad:前补零个数,后补maxlen-len(x)个(id=0)
4.1.2.4 句子的数量//batch_size=batch的数量。
4.1.2.5 将返回的等长id句子序列转变为tensor:tf.convert_to_tensor。
4.1.2.6 从tensor列表中按顺序或者随机抽取出tensor放入队列(作为tf.train.shuffle_batch的参数):tf.train.slice_input_producer([X, Y])。
4.1.2.7 通过随机打乱tensor的顺序创建batch,读取一个文件并且加载一个张量中的batch_size行:tf.train.shuffle_batch()。
4.1.3 推断:将测试数据定义为placeholder先放着。
4.1.4 定义decode部分的输入:保持与输入同维度,最前补全为2的列。???
4.1.5 加载id对应的双语字典。
4.1.6 设置作用域encoder
4.1.6.1 作用域enc_embed中将de2id embedding(embedding后是否scale)
4.1.6.1.1 embedding隐藏层512层。???
4.1.6.2 作用域enc_pe中,使用正弦曲线作positional_encoding;不使用正弦曲线则作embedding???
4.1.6.3 dropout:tf.layers.dropout()
4.1.6.4 每个block依次调用multihead_attention以及feedforward函数
4.1.7 作用域decoder
4.1.7.1 embedding\positional encoding\dropout
4.1.7.2 每个block依次调用2个multihead_attention以及feedforward函数
4.1.8 线性变换