JAVA集合框架8---PriorityQueue源码解析
PriorityQueue是一个优先队列,它实现了Queue接口,前面几篇文章我们分析过LinkedList与ArrayDeque的源码,它们也都实现了Queue接口,PriorityQueue与它们的不同之处在于PriorityQueue里面保存的元素有优先级的概念,每一个元素都有一个优先级,队头元素的优先级最高的,如果从队头元素依次出队列,得到的将是一个有序的输出。PriorityQueue的内部是用堆来实现的,堆是一棵完全二叉树,学过数据结构的同学应该都清楚二叉树结点的表示:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}上面就是一棵二叉树的结点经典表示了,结点里面的left与right结点分别指向其左孩子与右孩子。但是由于堆是一棵完全二叉树,我们有更方便的方法求出一个结点的双亲结点与左右孩子结点,我们给一棵完全二叉树按层序,从左到右编号1,2,3...可得到如下图一张完全二叉树:
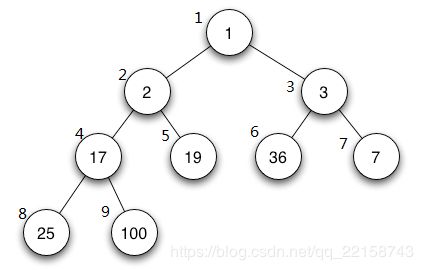
我们可以发现,如果一个结点的编号是 i,那么它的双亲结点的编号为 i/2 .左孩子结点为 2 * i ,右孩子结点为 2 * i + 1。如果将编号1,2,3...看做是数组的索引,那么我们就可以很方便的使用数组来求储存这棵完全二叉树了。

堆可以分为最小堆与最大堆,最小堆的性质是:每个结点都不小于其父节点;最大堆:每个结点都不大于其父节点。上面的例子是一个最小堆,首元素就是队首元素,优先级最高。
在堆中插入一个元素:
1、添加元素到最后的位置。
2、与父节点比较,如果小于等于父节点,则满足堆的性质,结束。否则与父节点进行交换,然后在与父节点比较交换,直到父节点为空或者大于等于父节点。
如果我们在队列中插入6,首先将6添加到队尾。
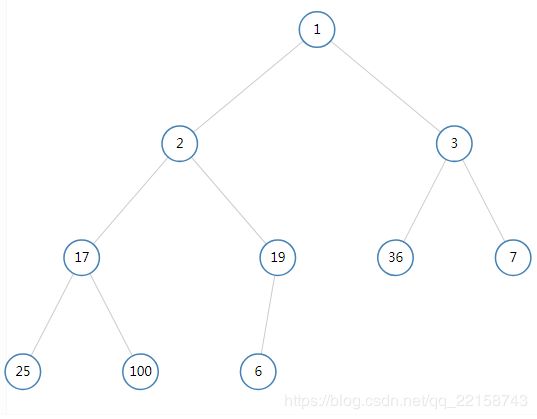
比较6(编号为10)与其父节点(编号为10/2=5)之间的大小,发现6比19小,与父节点交换。
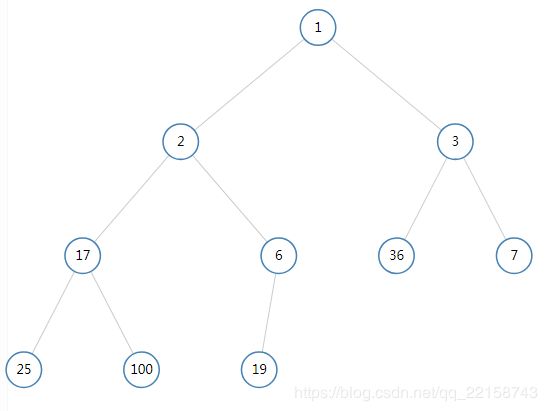
比较6(现在编号为5)与其父节点(编号为5/2=2)之间的大小,发现6比2大,满足最小堆的性质,插入结束。
在堆中删除元素:
1、用最后一个结点替换待删除的元素,并删掉最后一个元素;
2、如果替换后的结点小于其父节点,则与父节点交换,直到满足最小堆的条件;如果替换后的结点大于某个孩子结点,则与较小的孩子结点交换,直到满足最小堆的条件。
如果我们删除上面最小堆中的3,首先用最后一个结点19,替换3,并删除19。

发现19(编号3)比其右孩子(编号 2 * 3 + 1 = 7)7 大,交换 7与19。
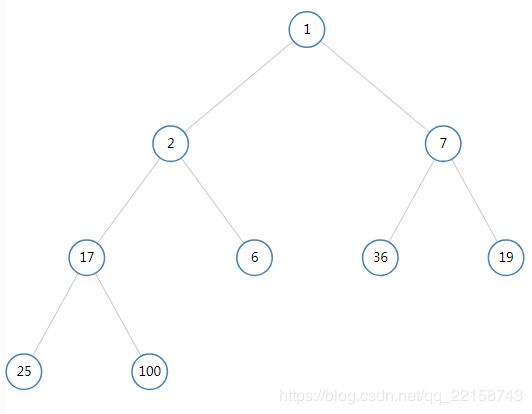
现在19是叶子结点了,没有孩子结点了,删除结束。
注意:队尾元素与待删除元素交换后,不可能即小于其父节点又大于孩子结点。
了解了这些我们就可以开始看PriorityQueue的源码了:
public class PriorityQueue extends AbstractQueue implements java.io.Serializable {
private static final long serialVersionUID = -7720805057305804111L;
private static final int DEFAULT_INITIAL_CAPACITY = 11; // 默认队列大小为11
transient Object[] queue; // 底层储存堆的数组
private int size = 0; // 队列的大小
private final Comparator comparator; // 元素之间的比较器
transient int modCount = 0; // 记录修改次数
// 无参构造函数,使用默认大小,元素之间的大小使用自然排序
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
// 初始化队列大小为指定值
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
// 使用传入的比较器
public PriorityQueue(Comparator comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
// 初始化队列为指定大小,使用传入的比较器
public PriorityQueue(int initialCapacity,
Comparator comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
// 使用集合来初始化队列
@SuppressWarnings("unchecked")
public PriorityQueue(Collection c) {
if (c instanceof SortedSet) { // 如果c是有序集合的子类
SortedSet ss = (SortedSet) c;
this.comparator = (Comparator) ss.comparator(); // 取得比较器
initElementsFromCollection(ss); // 初始化
}
else if (c instanceof PriorityQueue) { // 如果c是PriorityQueue的子类
PriorityQueue pq = (PriorityQueue) c;
this.comparator = (Comparator) pq.comparator();// 取得比较器
initFromPriorityQueue(pq); // 初始化
}
else {
this.comparator = null;
initFromCollection(c); // 那么此时集合是一个无序集合
}
}
@SuppressWarnings("unchecked")
public PriorityQueue(PriorityQueue c) {
this.comparator = (Comparator) c.comparator();
initFromPriorityQueue(c);
}
@SuppressWarnings("unchecked")
public PriorityQueue(SortedSet c) {
this.comparator = (Comparator) c.comparator();
initElementsFromCollection(c);
}
// 用另一个PriorityQueue来初始化PriorityQueue,之间将对于成员变量复制过来即可
private void initFromPriorityQueue(PriorityQueue c) {
if (c.getClass() == PriorityQueue.class) {
this.queue = c.toArray();
this.size = c.size();
} else {
initFromCollection(c);
}
}
// 当c是SortedSet的子类时,toArray返回的是一个有序集合
private void initElementsFromCollection(Collection c) {
Object[] a = c.toArray();
// If c.toArray incorrectly doesn't return Object[], copy it.
if (a.getClass() != Object[].class)
a = Arrays.copyOf(a, a.length, Object[].class);
int len = a.length;
if (len == 1 || this.comparator != null)
for (int i = 0; i < len; i++)
if (a[i] == null)
throw new NullPointerException();
this.queue = a;
this.size = a.length;
}
// 当c是一个无需集合时调用
private void initFromCollection(Collection c) {
initElementsFromCollection(c);
heapify(); // 初始化堆
}
@SuppressWarnings("unchecked")
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--)
siftDown(i, (E) queue[i]);
}
} PriorityQueue继承自AbstractQueue,AbstractQueue继承自AbstractCollection并实现了Queue接口。最后我们来解析一下上面的最后一个函数heapify。heapify函数是将一个无需数组初始化为一个最小堆,基本思路是:从最后一个非叶子结点开始,一直往前直到根,执行向下调整(shiftdown)就是我们上面说的,如果父节点大于其孩子结点则将父节点与较小的孩子结点交换,直到满足最小的的要求。换句话说,是自底向上,先使每个最小子树为堆,然后每对左右子树和其父节点合并,调整为最大的堆。因为每个子树已经为堆,所以调整就是对父节点执行向下调整,这样一直合并到根。 (size >>> 1) - 1 就是最后一个非叶子结点。
PriorityQueue的整个构造函数比起我们前面分析的其他的集合类(ArrayList,LinkedList,ArrayDeque)来说还是比较多,但是思路还是比较清晰的。无非使用其他集合来初始化PriorityQueue时,判断了一下传入集合的类型,如果传入的集合时有序数组,那么使用集合的toArray函数返回的就是一个有序数组,也就是一个最小堆了,如果传入的是一个无序集合那么我们就要使用heapify函数来将其转换为一个最小堆,这个转换过程使用了siftDown函数,该函数的思想我们在上面已经说过了。
接下来让我继续阅读源码:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 扩容函数,与ArrayList和ArrayDeque几乎是一样的,当容量较小时(小于64)扩容一倍,否则增加成原来的0.5倍
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ? (oldCapacity + 2) :(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
// 增加元素到末尾
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++; // 记录集合修改次数
int i = size;
if (i >= queue.length)
grow(i + 1); // 扩容
size = i + 1;
if (i == 0) // 如果原队列为空,直接插入队头就完了
queue[0] = e;
else
siftUp(i, e); // 向上调整,就是不断与父节点比较,小于父节点就与父节点交换,直到满足最小堆要求,i为插入的位置,就是队尾。
return true;
}
// 返回队头元素,不修改队列
@SuppressWarnings("unchecked")
public E peek() {
return (size == 0) ? null : (E) queue[0];
}
// 查找对象对应的索引,找不到或者o为null返回-1
private int indexOf(Object o) {
if (o != null) {
for (int i = 0; i < size; i++)
if (o.equals(queue[i]))
return i;
}
return -1;
}
// 删除某个对象,使用equal判断对象是否相等
public boolean remove(Object o) {
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
@SuppressWarnings("unchecked")
private E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
int s = --size;
if (s == i) // 删除的元素是队尾元素
queue[i] = null;
else {
E moved = (E) queue[s]; // moved为队尾元素,删除算法我们在前面已经介绍了
queue[s] = null;
siftDown(i, moved); // 向上调整
if (queue[i] == moved) { // 向上调整没有改变队列
siftUp(i, moved); // 向下调整
if (queue[i] != moved)
return moved;
}
}
return null;
}
public boolean contains(Object o) {
return indexOf(o) != -1;
}
public Object[] toArray() {
return Arrays.copyOf(queue, size);
}
@SuppressWarnings("unchecked")
public T[] toArray(T[] a) {
final int size = this.size;
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(queue, size, a.getClass());
System.arraycopy(queue, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
public int size() {
return size;
}
public Comparator comparator() {
return comparator;
}
public void clear() {
modCount++;
for (int i = 0; i < size; i++)
queue[i] = null;
size = 0;
}
// 返回队头元素
@SuppressWarnings("unchecked")
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
private void siftUp(int k, E x) {
if (comparator != null) // 是否自定义了比较器
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
@SuppressWarnings("unchecked")
private void siftUpComparable(int k, E x) {
Comparable key = (Comparable) x;
while (k > 0) {
int parent = (k - 1) >>> 1; // 双亲结点索引
Object e = queue[parent];
if (key.compareTo((E) e) >= 0) // x比双亲结点大,满足最小堆条件
break;
queue[k] = e; // 交换父子结点
k = parent;
}
queue[k] = key;
}
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0) // 使用自定义的比较器比较
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
private void siftDown(int k, E x) {
if (comparator != null) // 与siftUp一样,判断是否含有自定义比较器
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
@SuppressWarnings("unchecked")
private void siftDownComparable(int k, E x) {
Comparable key = (Comparable)x;
int half = size >>> 1; // 自有当结点有孩子结点时才向下调整
while (k < half) {
int child = (k << 1) + 1; // 左孩子结点索引
Object c = queue[child];
int right = child + 1; // 右孩子结点索引
if (right < size &&
((Comparable) c).compareTo((E) queue[right]) > 0) // 左孩子比右孩子大
c = queue[child = right];
if (key.compareTo((E) c) <= 0) // 父节点比较小的孩子结点小,满足最小堆的要求
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
@SuppressWarnings("unchecked")
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0) // 使用自定义的比较器比较大小
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = x;
}