基于多核升级和自适应融合的改进的显著性检测(Improving Saliency Detection Via Multiple Kernel Boosting and Adaptive Fusion)
基于多核升级和自适应融合的提高的显著性检测
Xiaofei Zhou, Zhi Liu, Senior Member, IEEE, Guangling Sun, Linwei Ye, and Xiangyang Wang
【摘要】这篇文章提出了一个改进现有显着性模型的显著性检测性能的新框架,用于产生初始显著图。首先,提出了一个由区域自我信息,区域差异以及局部,全局和边界等多个特征区域对比的新型区域描述算子,用于描述多尺度的分段区域。然后,把显着性计算看作回归问题,提出了基于支持向量回归(MKB-SVR)的多内核提升方法来生成互补显著图。最后,提出了一种通过学习显著性图的质量预测模型的自适应融合方法,有效地将初始显着图与互补显著图融合,并获得最终显著性图,并提高了显著性检测性能。具有最先进的显著性模型的两个公共数据集的实验结果验证了所提出的方法持续改进了各种显著性模型的显著性检测性能。
【关键词】自适应融合,多内核提升,区域描述算子,显著性检测,支持向量回归。
1 简介
由于在许多应用中广泛使用,近年来,显著性检测受到越来越多的关注例如突出物体检测和分割[1],[2],内容感知图像/视频重定向[3] - [6],基于内容的图像/视频压缩[7],[8]等等。大多数显著性模型是自下而上的刺激驱动,即仅利用从图像提取的特征进行显著计算。例如,具有不同配方的各种特征的中心环绕方案[9]已被广泛地用于测量多个显著性模型中的显著性,例如基于区域对比度的模型[10],其同时评估全局对比度和空间相干性区域估计显著性。最近,通过层次推理[11]和显著性树[12]的层次显著性模型实现了显著性的分层表示,并提高了显著性检测性能。在[13]中,利用基于图形的歧管排序,通过结合局部分组线索和边界先验来生成显著图。
已经通过机器学习将自上而下的信息纳入显着性模型方面做了一些努力。通过使用[1]中的条件随机场(CRF)来学习显着特征的融合权重,并学习了线性支持向量机(SVM)的混合来检测[14]中的突出对象。在[15]中,联合CRF和字典学习被用于测量显着性。在[16]和[17]中,随机森林回归用于将区域辨别特征向量映射到每个区域的显着性得分,并将多个层次的显着性得分融合,以获得最终的区域显着性。对于显着性计算作为分类问题,利用基于SVM的多个内核提升的引导学习(BL)方法[18],以现有的显着性模型为基础,生成强大的显着性图。
然而,现有显着性模型的显着性检测性能在复杂图像上明显降低。因此,我们提出了一种新颖的框架,通过多核增强和自适应融合来有效提高现有显着性模型的显着性检测性能。所提出的方法的一个例子如图1所示。 我们的主要贡献在于以下三个方面:
(1)我们提出了一个新颖的区域描述算子,引入更有效的特征,在每个特征的基础上,结合局部,全局和边界来计算区域对比度,区域自我信息,区域差异和区域对比度的衔接。所提出的区域描述算子与以前的作品[16],[17]中使用的区别描述算子有很大不同,可以更好地描述该区域的显著性计算。
(2)与也使用多内核提升的BL方法[18]不同,我们将显着性计算视为回归问题,提出了一种基于支持向量回归(MKB-SVR)的新型多内核提升方法,与多内核学习一致,通过定义回归误差和样本权重的更新来充分利用多个特征。
(3)我们通过学习质量预测模型提出了一种自适应融合方法,以获得初始显着图和互补显着图的融合权重,最终使提出的方法不断提高各种显着性模型的显着性检测性能。

2 提出的方法
为了处理规模问题,通过使用简单线性迭代聚类(SLIC)方法[19],分别在区域数目分别为100,150,200和250的四个尺度上生成多尺度分割结果Sm(m = 1, . . . , 4)。
A 区域描述算子
为了全面地代表一个地区,我们引入了一个新的区域描述符,用来衡量区域性属性(区域自我信息和区域差异)以及八个特征(nF = 8)的区域对比度,如表I所示。在每个区域的基础上,我们提取RGB,HSV和Lab三个颜色空间中的颜色特征,以及两个纹理特征,包括局部二值模式(LBP)特征[20]以及梁和马利克(LM)滤波器的响应[21]。此外,提取尺度不变特征变换(SIFT)描述符[22]和定向梯度(HOG)特征[23]的直方图,以表示每个区域,包括尺度和方向以及每个区域到图像边界的测地距离(GD)的局部属性被计算为背景[24]。具体来说,我们使用[25]提取像素级的密集SIFT特征,使用GS网格算法在均匀间隔的细胞和斑块级GD的密集网格上计算斑块级HOG特征。每个像素块的HOG功能和GD分配给落入像素块的所有像素。
对于每个区域Ri ∈ Sm, 我们通过使用Ri中的所有像素,在八个特征上计算一组区域自己的信息![]() 和区域方差
和区域方差![]() ,即,
,即,
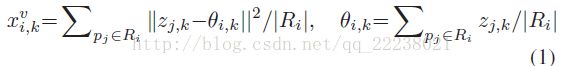
其中|Ri|表示落入区域Ri中的像素数目,zj,k表示区域中每一个像素pj的第k个特征。
通过将Ri与三个上下文中的区域进行比较来评估第k个特征上的每个区域Ri的区域对比度![]() ,并且定义如下:
,并且定义如下:

其中上标N可以分别表示本地上下文,全局上下文和边界上下文的L,G和B。对于每个区域Ri ,![]() 可以表示其N = L的本地上下文(与Ri空间相邻的区域),其N = G的全局上下文(Sm中的所有其他区域)或其N = B的边界上下文(沿图像边界的区域)。区域对比度
可以表示其N = L的本地上下文(与Ri空间相邻的区域),其N = G的全局上下文(Sm中的所有其他区域)或其N = B的边界上下文(沿图像边界的区域)。区域对比度![]() 是与上述三个上下文计算的对比度的并置,因此在表I中,每个特征的区域对比度的维数具有三个“×3”的乘法因子。为了在任何上下文N中计算
是与上述三个上下文计算的对比度的并置,因此在表I中,每个特征的区域对比度的维数具有三个“×3”的乘法因子。为了在任何上下文N中计算![]() ,λj是区域Rj的归一化面积; wij = exp( - ||ρi-ρj|| 2/2)是ρi和ρj之间的空间距离的因子,即分别为Ri和Rj的归一化质心; fi表示Ri的任何区域特征。 对于具有nD维度的一对区域特征的特征差Dk(fi,fj)可以采用三个距离度量:1)
,λj是区域Rj的归一化面积; wij = exp( - ||ρi-ρj|| 2/2)是ρi和ρj之间的空间距离的因子,即分别为Ri和Rj的归一化质心; fi表示Ri的任何区域特征。 对于具有nD维度的一对区域特征的特征差Dk(fi,fj)可以采用三个距离度量:1)![]()
2)欧氏距离d2(fi,fj)= || fi-fj ||; 和3)卡方距离χ2(fi,fj)。 详情请参阅表一。 最后,在每个特征的基础上,区域自我信息,方差和对比度被连接以形成第k个特征上的每个区域Ri的区域描述符xi,k,如下所示:
![]()
B 基于支持向量回归的多内核提升
把显着性计算看作回归问题,充分利用了多个特征,我们提出了一种新型的MKB-SVR来估计互补显着图。 我们的MKB-SVR方法包含四种具有八个特征的内核![]() (线性,径向基函数(RBF),S形和多项式,nk = 4)。
(线性,径向基函数(RBF),S形和多项式,nk = 4)。
对于训练回归器,我们选择训练集![]() 其中ns是基于初始显着度MI的样本数,可以使用图像的任何显着性模型生成。 对于第i个样本,
其中ns是基于初始显着度MI的样本数,可以使用图像的任何显着性模型生成。 对于第i个样本,![]() 是每个区域Ri的区域描述符,yi是Ri作为正或负样本的显着值。 具体而言,μ表示MI的平均显着值,μi表示MI中Ri的平均显着值。 如果μi高于1.5μ的较大阈值,则将Ri标记为正样本,将yi设置为+1,或者将其标记为负样本,如果μi低于较小阈值0.05,则将yi设置为-1。
是每个区域Ri的区域描述符,yi是Ri作为正或负样本的显着值。 具体而言,μ表示MI的平均显着值,μi表示MI中Ri的平均显着值。 如果μi高于1.5μ的较大阈值,则将Ri标记为正样本,将yi设置为+1,或者将其标记为负样本,如果μi低于较小阈值0.05,则将yi设置为-1。
按照MKB的框架[26],具有特征的单个核心SVR的回归误差,特别是第j次迭代中具有第k个特征的第m个核心被定义为:
![]()
其中当r> 0时,符号函数Ψ[r]等于1,否则为0。 ![]() 是第j次迭代时第i个训练样本的第k个特征的权重,hm,k(xi,k)是xi,k上SVR的输出。 阈值Δ定义为:
是第j次迭代时第i个训练样本的第k个特征的权重,hm,k(xi,k)是xi,k上SVR的输出。 阈值Δ定义为:
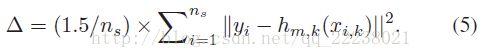
我们的MKB-SVR方法的整个过程总结在算法1中,通过自适应地集成最具辨别特征和相应的内核来获得回归F(x)。 升压迭代次数J自适应地设定为nk×nF。 然后,对于每个区域R *,使用其区域描述符作为输入,x = x *,回归器输出被分配给R *中的所有像素的估计显着值y *。 回归算法应用于所有测试样本,并且以![]() 生成四个尺度的互补显着图。 最后,输入图像的互补显着图计算为
生成四个尺度的互补显着图。 最后,输入图像的互补显着图计算为![]() 。
。

算法1
输入:训练集![]() 和内核函数
和内核函数![]()
输出:回归F(x)
1、对于每个功能的每个内核函数,通过使用整个训练集![]() ,通过第k个特征的内核Km对单核心SVR hm,k进行训练,并且生成总共nK × nF SVR以形成候选集Ω。
,通过第k个特征的内核Km对单核心SVR hm,k进行训练,并且生成总共nK × nF SVR以形成候选集Ω。
2、将样本的权重初始化为![]()
![]() 并且初始化回归为F(x)=0。
并且初始化回归为F(x)=0。
3、for j=1:J
对每一个SVR hm,k,使用公式(4)计算回归误差![]() ,选择最佳SVR为
,选择最佳SVR为![]()
![]()
,设置![]()
ifδ(j) < 0.5
对于H(j)计算权重![]()
更新回归![]()
else
break;
end if
更新每一个权重![]()
![]() ,然后对所有权重进行归一 化
,然后对所有权重进行归一 化
end for
4、获得回归![]()
C 自适应融合
提出的自适应融合方法评估显着性图的质量,以计算融合权重,以便将初始显着性图与互补显性图进行自适应融合。
我们对显着性图采用六项质量措施[27],并将其连结在一起构成质量特征。对一组样本进行线性核的“一对全”SVM [28]训练,以预测显着性图的质量,我们随机选择了Microsoft研究亚洲(MSRA)数据集[1]的nT = 3000图像来训练这个质量预测模型。 具体地,对于每个训练图像Ti(i = 1,...,nT),使用第II-A和II-B节中的过程来生成初始显着图![]() 和互补显影图
和互补显影图![]() 。分别为
。分别为![]() 和
和![]() 生成两个训练样本{q2i-1,l2i-1}和{q2i,l2i}。 这里,q2i-1表示
生成两个训练样本{q2i-1,l2i-1}和{q2i,l2i}。 这里,q2i-1表示![]() 的质量特征,l2i-1是表示
的质量特征,l2i-1是表示![]() 在其对应
在其对应![]() 上的相对质量的二进制标签。 类似的定义适用于{q2i,l2i}。 对于
上的相对质量的二进制标签。 类似的定义适用于{q2i,l2i}。 对于![]() 和
和![]() ,我们分别计算接收器工作特性(ROC)曲线(AUC),
,我们分别计算接收器工作特性(ROC)曲线(AUC),![]() 和
和![]() 下的面积,以定量测量其质量并确定二进制标签如下:
下的面积,以定量测量其质量并确定二进制标签如下:
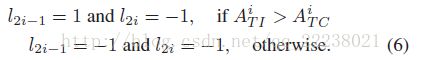
学习的质量预测模型用于预测给定显着图的质量得分。 对于测试图像的初始显着图MI和互补显着图MC,我们首先分别计算两个质量特征,即qI和qC,然后使用学习模型获得两个决策值作为其质量得分,sI和 sC。 然后将MI和MC的融合权重定义为
![]()
最终的显著图MF生成如下
![]()
3 实验结果
我们在两种基准数据集(即MSRA [1]和PASCAL-1500 [29])上评估了提出的方法的性能。 由于来自MSRA数据集的3000张图像用于训练II-C节中的质量预测模型,剩余的2000张图像用于测试。 根据[30]中使用的评估措施,我们通过将其系数β2设置为0.3,使用精确召回(PR)曲线和F度量来评估显着性检测性能。我们使用五个显着性模型,包括区分特征集成(DRFI)[17],基于图的歧管排序(GMR)[13],显着性树(ST)[12],层次显着性(HS)[11]和区域对比 (RC)[10]生成初始显着图,并使用提出的方法生成补充和最终显着图。 例如,使用DRFI模型,初始,补充和最终显着性图分别表示为DRFI-I,DRFI-C和DRFI *。
初始,补充和最终显着图之间的比较如图2(a)所示。从图2(a)可以看出,四个模型(不包括DRFI模型)的互补显着图比高准确率和高召回率区域中相应的初始显着图具有更高的性能,这对于突出物体检测至关重要,这对于突出物体检测至关重要。 DRFI模型在最先进的显着性模型中具有最高的性能[30],但DRFI-C的性能略低于DRFI-I。 尽管如此,我们的方法的最重要的特征是,在两个数据集上的所有五个显着性模型中,我们的最终显着性图在显着性检测性能上始终优于相应的初始和补充显着性图。
图2(b)显示了使用我们和Jiang的[17]区域描述符(表示为DRFI-J)生成的互补显着图之间的性能比较。使用我们的方法,我们只用江的描述符替换了我们的描述符进行比较。从图2(b)可以看出我们的描述符始终胜于江的所有的五种显著性模型。图2(c)所示的F度量表明,我们的自适应融合方法始终优于加权组合方法,在所有五个显着模型中,相同的权重被分配给初始和补充显着图,因为它们同等重要。请注意图2(b)和(c)显示了MSRA数据集的结果,同时也可以从PASCAL-1500数据集的结果中得出同样的结论。 此外,为了识别哪个特征对最终结果做出最大的贡献,我们使用一次性方案对所有八个特征中的特征进行分组。因此,每个特征集包含七个特征,总共有八个特征集被利用来使用我们的方法生成八类最终显着图。然后,我们使用PR曲线和F-measure来评估其显着性检测性能,通过消除与使用所有功能相比性能最差的性能,发现最重要的特征是GD。

图3显示了一些示例图像的显着性图。可以看出,使用我们的方法(偶数列)生成的显著图可以比初始显着图(奇数列)更好地突出显着的对象区域并抑制背景区域。我们的方法可以更好地处理一些有低对比度对象,异构对象和杂乱无章的背景的复杂的图像。虽然我们的最终显着图依赖于初始显着图的质量,但我们的方法有效地提高了显着性图的质量。
我们的方法是在具有Intel Core i7 4.0 GHz CPU和16 GB RAM的PC上使用MATLAB实现的。
训练时间约为47小时,分辨率为400×300的图像的平均测试时间为56.95秒包括生成互补显着图(分别为II-A和B分别为47.05和0.73 s)和自适应融合程序(第II-C节需要9.17秒)。
4 结论
这篇文章提出了一个新框架来改进现有显着性模型的显着性检测性能。新的区域描述符更好地描述了显着性估计的区域,MKB-SVR算法有效地整合了最具辨别力的特征和相应的内核以产生互补显性图,通过学习质量预测模型进行自适应融合,产生质量更高的最终显着图。具有五个最先进的显着性模型的两个公共数据集的实验结果表明了我们的方法在提高显着性检测性能方面的有效性和鲁棒性。
【参考文献】
[1] T. Liu et al., “Learning to detect a salient object,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 2, pp. 353–367, Feb. 2011.
[2] Z. Liu, R. Shi, L. Shen, Y. Xue, K. N. Ngan, and Z. Zhang, “Unsupervised salient object segmentation based on kernel density estimation and twophase graph cut,” IEEE Trans. Multimedia, vol. 14, no. 4, pp. 1275–1289, Aug. 2012.
[3] A. Shamir and S. Avidan, “Seam carving for media retargeting,” Comm. ACM, vol. 52, no. 1, pp. 77–85, Jan. 2009.
[4] H. Du, Z. Liu, J. Jiang, and L. Shen, “Stretchability-aware block scaling for image retargeting,” J. Vis. Commun. Image Represent., vol. 24, no. 4, pp. 499–508, May 2013.
[5] Y. Fang, Z. Chen, W. Lin, and C.-W. Lin, “Saliency detection in the compressed domain for adaptive image retargeting,” IEEE Trans. Image Process., vol. 21, no. 9, pp. 3888–3901, Sep. 2012.
[6] Y. Fang, W. Lin, B.-S. Lee, C.-T. Lau, Z. Chen, and C.-W. Lin, “Bottomup saliency detection model based on human visual sensitivity and amplitude spectrum,” IEEE Trans. Multimedia, vol. 12, no. 1, pp. 187–198, Feb. 2012.
[7] C. Guo and L. Zhang, “A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression,” IEEE Trans. Image Process., vol. 19, no. 1, pp. 185–198, Jan. 2010.
[8] L. Shen, Z. Liu, and Z. Zhang, “A novel H.264 rate control algorithm with consideration of visual attention,” Multimedia Tools Appl., vol. 63, no. 3, pp. 709–727, Apr. 2013.
[9] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 20, no. 11, pp. 1254–1259, Nov. 1998.
[10] M.-M. Cheng, G.-X. Zhang, N. J. Mitra, X. Huang, and S.-M. Hu, “Global contrast based salient region detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR’11), Jun. 2011, pp. 409–416.
[11] Q. Yan, L. Xu, J. Shi, and J. Jia, “Hierarchical saliency detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR’13), Jun. 2013, pp. 1155–1162.
[12] Z. Liu, W. Zou, and O. Le Meur, “Saliency tree: A novel saliency detection framework,” IEEE Trans. Image Process., vol. 23, No. 5, pp. 1937–1952, May 2014.
[13] C. Yang, L. Zhang, H. Lu, X. Ruan, and M.-H. Yang, “Saliency detection via graph-based manifold ranking,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR’13), Jun. 2013, pp. 3166–3173.
[14] P. Khuwuthyakorn, A. Robles-Kelly, and J. Zhou, “Object of interest detection by saliency learning,” in Proc. 11th Eur. Conf. Comput. Vis. (ECCV’10), Sep. 2010, pp. 636–649.
[15] J. Yang and M.-H. Yang, “Top-down visual saliency via joint CRF and dictionary learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR’12), Jun. 2012, pp. 2296–2303.
[16] H. Jiang, J. Wang, Z. Yuan, Y. Wu, N. Zheng, and S. Li, “Salient object detection: A discriminative regional feature integration approach,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR’13), Jun. 2013, pp. 2083–2090.
[17] H. Jiang, Z. Yuan, M.-M. Cheng, Y. Gong, N. Zheng, and J. Wang, “Salient object detection: A discriminative regional feature integration approach,” arXiv: 1410.5926 [cs. CV], Oct. 2014, http://arxiv.org/abs/1410.5926.
[18] N. Tong, H. Lu, X. Ruan, and M.-H. Yang, “Salient object detection via bootstrap learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR’15), Jun. 2015, pp. 1884–1892.
[19] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Susstrunk, “Slic superpixels compared to state-of-the-art superpixel methods,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 11, pp. 2274–2282, May 2012.
[20] M. Heikkilä, M. Pietikäinen, and C. Schmid, “Description of interest regions with local binary patterns,” Pattern Recognit., vol. 42, no. 3, pp. 425–436, Mar. 2009.
[21] T. Leung and J. Malik, “Representing and recognizing the visual appearance of materials using three-dimensional textons,” Int. J. Comput. Vis., vol. 43, no. 1, pp. 29–44, Jun. 2001.
[22] D. G. Lowe, “Object recognition from local scale-invariant features,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV’99), Sep. 1999, pp. 1150–1157.
[23] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR’05), Jun. 2005, pp. 886–893.
[24] Y.Wei, F.Wen,W. Zhu, and J. Sun, “Geodesic saliency using background priors,” in Proc. 11th Eur. Conf. Comput. Vis. (ECCV’12), Sep. 2012,pp. 29–42.
[25] A. Vedaldi and B. Fulkerson, “Vlfeat: An open and portable library of computer vision algorithms,” in Proc. 18th ACM Multimedia, Oct. 2010, pp. 1469–1472.
[26] F. Yang, H. Lu, and Y.-W. Chen, “Human tracking by multiple kernel boosting with locality affinity constraints,” in Proc. 10th Asian Conf. Comput. Vis., Nov. 2011, pp. 39–50.
[27] L. Mai and F. Liu, “Comparing salient object detection results without ground truth,” in Proc. 14th Eur. Conf. Comput. Vis. (ECCV’14), Sep. 2014, pp. 76–91.
[28] L. Bottou, C. Cortes, J. S. Denker, H. Drucker, I. Guyon, and L. Jackel, “Comparison of classifier methods: A case study in handwritten digit recognition,” in Proc. IEEE Int. Conf. Pattern Recognit. (ICPR’94), Oct. 1994, pp. 77–82.
[29] W. Zou, K. Kpalma, Z. Liu, and J. Ronsin, “Segmentation driven low rank matrix recovery for saliency detection,” in Proc. Br. Mach. Vis. Conf. (BMVC’13), Sep. 2013, pp. 1–13.
[30] A. Borji, M.-M. Cheng, H Jiang, and J. Li, “Salient object detection: A benchmark,” IEEE TraTrans. Image Process., vol. 24, no. 12, pp. 5706–5722,Dec. 2015.