kmeans算法
算法的基本内容和计算方法引自百度,本文重点介绍KMeans在python数据分析的实现,快速掌握利用sklearn实现聚类分析的操作方法,先会用在应用中进一步理解内涵也是一种学习途径。
Kmeans算法
k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为c个类别,算法描述如下:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
算法流程
首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
具体流程
输入:k, data[n];
(1) 选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 对于data[0]….data[n], 分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i]={ 所有标记为i的data[j]之和}/标记为i的个数;
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值。
Python中kmeans算法实现
l 输入数据为两列数据x,y,保存在txt文本中
l KMeans().fit(data)里的data为矩阵数据,矩阵为(数据点)x(数据类型)的规格这里为nx2,聚类根据两个类型数据的n个观测值来进行聚类
l center=kmeans.cluster_centers_得到聚类后的聚类中心,同样为4x2的矩阵(center),4类各自的中心对应的x,y值
l labels=kmeans.labels_得到聚类后每一组数据对应的类型标签,数据为一个列表labels[1,2,3,1]对应每一组数据的类别
l 理解上述输入和输出参数即可快速利用sklearn.cluster.KMeans来实现聚类。
#----------SklearnKMeans-----------
#---------- 5_kong-----------------
#---------- http://blog.csdn.net/playgoon2---------
#-------------start--------------------
from sklearn.cluster import KMeans
import pandas as pd
import matplotlib.pyplot as plt
#读取文本数据到DataFrame中,将数据转换为matrix,保存在dataSet中
df = pd.read_table('d:/22.txt')
dataSet = df.as_matrix(columns=None)
#n_clusters=4,参数设置需要的分类这里设置成4类
kmeans = KMeans(n_clusters=4, random_state=0).fit(dataSet)
#center为各类的聚类中心,保存在df_center的DataFrame中给数据加上标签
center=kmeans.cluster_centers_
df_center = pd.DataFrame(center,columns=['x','y'])
#标注每个点的聚类结果
labels=kmeans.labels_
#将原始数据中的索引设置成得到的数据类别,根据索引提取各类数据并保存
df = pd.DataFrame(dataSet,index=labels,columns=['x','y'])
df1 = df[df.index==0]
df2 = df[df.index==1]
df3 = df[df.index==2]
df4 = df[df.index==3]
#绘图
plt.figure(figsize=(10,8), dpi=80)
axes = plt.subplot()
#s表示点大小,c表示color,marker表示点类型,DataFrame数据列引用参考博客其他文章
type1 = axes.scatter(df1.loc[:,['x']], df1.loc[:,['y']], s=50, c='red',marker='d')
type2 = axes.scatter(df2.loc[:,['x']],df2.loc[:,['y']], s=50, c='green',marker='*')
type3 = axes.scatter(df3.loc[:,['x']],df3.loc[:,['y']], s=50, c='brown',marker='p')
type4 = axes.scatter(df4.loc[:,['x']],df4.loc[:,['y']], s=50, c='black')
#显示聚类中心数据点
type_center = axes.scatter(df_center.loc[:,'x'], df_center.loc[:,'y'], s=40, c='blue')
plt.xlabel('x',fontsize=16)
plt.ylabel('y',fontsize=16)
#显示图例(loc设置图例位置)
axes.legend((type1, type2, type3,type4,type_center), ('0','1','2','3','center'),loc=1)
plt.show()
#-------------------END----------------------------
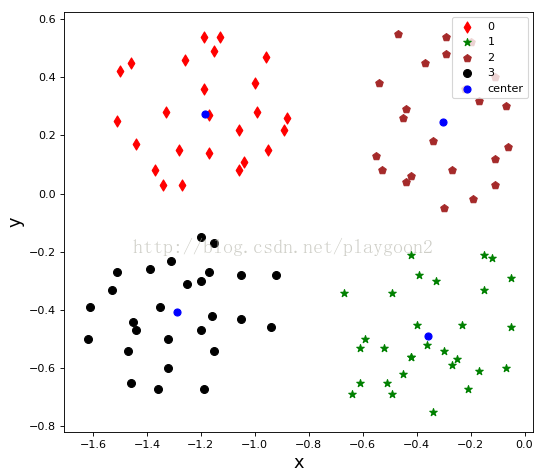
程序运行结果: