Hadoop安装配置、运行第一个WordCount示例程序
操作系统ubuntu。本篇目的是在单机模式下运行成功WordCount示例程序。
本篇小结安装步骤,遇到的问题和解决办法。
疑惑点及其思考。
Hadoop是为linux而开发的,所以开发hadoop程序,包括spark最好在linux环境下。目录如下:
一:Hadoop运行环境安装:
java1.6安装配置
Hadoop用户创建
SHH安装及配置
二:安装Hadoop 2.x
下载
安装
配置
三:WordCount示例程序运行测试
创建input
拷贝文件到input目录
执行示例程序
查看输入目录output
详细过程如下:
一:Hadoop运行环境安装:
java1.6安装配置:
具体过程分为:下载Oracle JDK, 新建安装目录,解压,配置环境变量,让环境变量生效,检验java安装结果。
下载:到官网下载linux版本的oracle JDK
新建目录:命令mkdir
解压文件:命令tar -zxvf解压文件到新建目录
配置环境变量:命令vim ~/.bashrc或者gedit ~/.bashrc修改配置文件。添加安装路径JAVA_HOME等。
让环境变量生效:命令source ~/.bashrc
检验安装结果:命令java -version.能出现安装java的版本信息,则表示成功。
注意事项:linux系统默认安装了openJDK,为了性能,个人还是建议删除openJDK.到官网下载oracle JDK并安装。
Hadoop用户创建
创建Hadoop用户:命令sudo useradd -m hadoop -s /bin/bash. 创建hadoop用户,并使用bash作为shell.
设置密码:命令sudo passwd hadoop.
添加hadoop用户管理员权限:命令sudo adduser hadoop su.
网上另一种方法是:命令sudo gedit /etc/sudoers.在打开的文件中在root All=(All:All)All下一行添加hadoop All=(All:All)All.
注销当前用户,并用hadoop用户登陆。
SSH安装及配置
用hadoop登陆后,更新apt.命令sudo apt-get update.
安装SSH:命令sudo apt-get install openssh-server. 默认的openssh-client已经安装。
启动服务:命令sudo /etc/init.d/ssh start
查看服务是否启动:ps -e | grep ssh
登陆ssh:命令ssh localhost。输入hadoop用户密码即可登陆。这样每次登陆都必须输入密码,比较费劲,所以需要设置免密码登陆。
生成密钥并加入授权:命令ssh-keygen
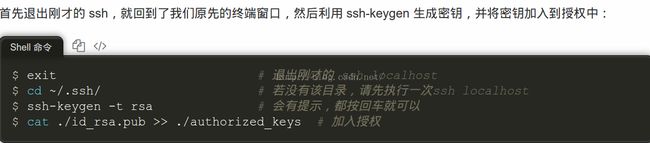
无密码登陆ssh:命令ssh localhost就能无密码登陆了。
二:安装Hadoop 2.x
下载:
到官网下载最新且最稳定(stable)的版本,格式为.tar.gz,为已编译好版本。src是hadoop源代码,需要重新编译才可用。
md5文件用于校验下载文件是否完整。一般不用。
安装:
解压:tar -zxvf命令解压到 /usr/local目录下
改名:mv命令改名为hadoop
修改文件权限:
方法一:sudo chmod 774 /usr/local/hadoop
方法二:sudo chown -R hadoop ./hadoop
配置:
配置~/.bashrc文件:用gedit打开,文件末尾添加如下:
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
配置文件/usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改这一行为:export JAVA_HOME=/usr/lib/jvm/java
测试haoop是否安装成功,见下图:
三:WordCount示例程序运行测试
创建input
命令mkdir input, 创建input目录。
拷贝文件到input目录
命令cp README.txt input, 拷贝文件到input目录,作为输入。
执行示例程序
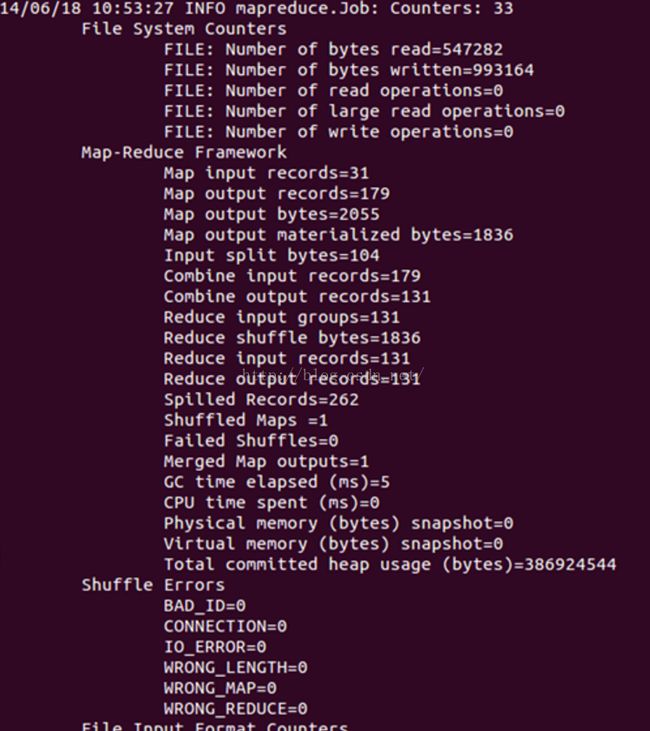
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output。
见下图:
执行结果如下:
查看输入目录output
命令 cat output/*,结果如下:参考文章:
1.http://www.powerxing.com/install-hadoop/
2.http://www.cnblogs.com/kinglau/p/3794433.html
3.http://wenku.baidu.com/link?url=nlVL80JkbQkGD9T8lZqlrxSqTHCmm2A5z4EYcfvoHYe4CZIyh0VseZxIJ5fpJbGXRruHv7UCB-e-bTh_8NvLGplQSpcVyQ_iMuSowhZm6ty