搜索引擎索引之索引更新策略
本文节选自《这就是搜索引擎:核心技术详解》第三章
动态索引通过在内存中维护临时索引,可以实现对动态文档和实时搜索的支持。但是服务器内存总是有限的,随着新加入系统的文档越来越多,临时索引消耗的内存也会随之增加。当最初分配的内存将被使用完时,要考虑将临时索引的内容更新到磁盘索引中,以释放内存空间来容纳后续的新进文档,此时要考虑合理有效的索引更新策略。
常用的索引更新策略有四种:完全重建策略,再合并策略,就地更新策略以及混合策略。
3.6.1完全重建策略(Complete Re-Build)
完全重建策略是一个相当直观的方法,当新增文档达到一定数量,将新增文档和原先的老文档进行合并,然后利用前述章节提到的建立索引的方式,对所有文档重新建立索引。新索引建立完成后,老的索引被遗弃释放,之后对用户查询的响应完全由新的索引负责。图3-16是这种策略的说明示意图。
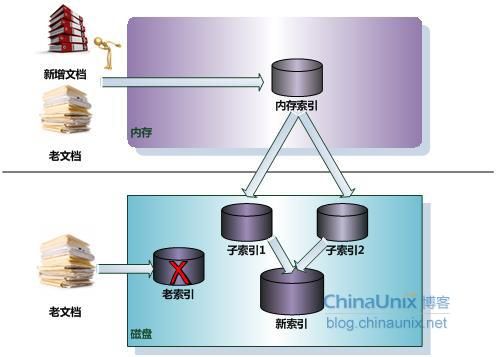
图3-16完全重建策略
因为重建索引需要较长时间,在进行索引重建的过程中,内存中仍然需要维护老的索引,来对用户的查询做出响应,只有当新索引完全建立完成后,才能释放旧的索引,将用户查询响应切换到新索引上。
这种重建策略比较适合小文档集合,因为完全重建索引的代价较高,但是目前主流商业搜索引擎一般是采用此种方式来维护索引的更新,这与互联网本身的特性有关。
3.6.2再合并策略(Re-Merge)
有新增文档进入搜索系统时,搜索系统在内存维护临时倒排索引来记录其信息,当新增文档达到一定数量,或者指定大小的内存被消耗完,则把临时索引和老文档的倒排索引进行合并,以生成新的索引。图3-17是这种策略的一种图示。
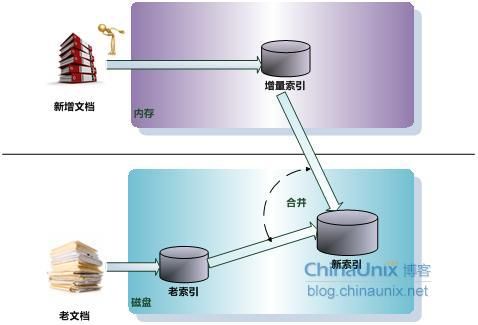
图3-17 再合并策略
在实际的搜索系统中,“再合并策略”按照以下步骤进行索引内容的更新:
当新文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排列表末尾追加倒排列表项,这个临时索引可称之为“增量索引”;
一旦“增量索引”将指定的内存消耗光,此时需要进行一次索引合并,即将“增量索引”和老的倒排索引内容进行合并。图3-18是合并过程示意图,这里需要注意的是:倒排文件里的倒排列表存放顺序,已经按照索引单词字典顺序由低到高进行了排序,增量索引在遍历词典的时候也按照字典序由低到高排列,这样对老的倒排文件只需进行一遍扫描,并可顺序读取,减少了文件操作中比较耗时的磁盘寻道时间,可以有效地增加合并效率。
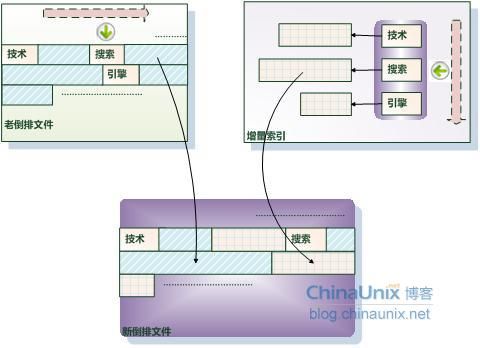
图3-18 合并增量索引与倒排索引
在合并过程中,需要依次遍历“增量索引”和老索引单词词典中包含的单词及其对应的倒排列表,可以用两个指针分别指向两套索引中目前需要合并的单词(参考图3-18中箭头所指),按照如下方式进行倒排列表的合并:
考虑“增量索引”的单词指针指向的单词,如果这个单词在词典序中小于老索引的单词指针指向的单词,说明这个单词在老索引中没有出现过,则直接将这个单词对应的倒排列表写入新索引的倒排文件中,同时“增量索引”单词指针后移指向下一个单词。
如果两个“单词指针”指向的单词相同,说明这个单词在“增量索引”和老索引中同时出现,则将老索引中这个单词对应的倒排列表写入新索引的倒排列表,然后把“增量索引”中这个单词对应的倒排列表追加到其后,这样就完成了这个单词所有倒排列表的合并。图3-18中箭头所指单词是“搜索”,说明此时合并到了该单词,因为在老的索引系统和增量索引中都包含这个单词,所以首先将老索引对应的倒排列表追加到新索引倒排文件末尾,之后将增量索引中“搜索”这个单词对应的倒排列表追加在其后,这样就完成了这个单词索引项的合并。两个索引的单词指针都移动到下一个单词继续进行合并。
如果某个单词只在老索引中出现过,即发现老索引的“单词指针”指向的单词,其词典序小于“增量索引”单词指针指向的单词,则直接将老索引中对应的倒排列表写入新索引倒排文件中。老索引的单词指针后移指向下一个单词,继续进行合并。
当两个索引的所有单词都遍历完成后,新索引建成,此时可以遗弃释放老索引,使用新索引来响应用户查询请求。
同样的,在按照这个策略进行索引合并的过程中,为了能够响应用户查询,在合并索引期间,需要使用老索引响应用户查询请求。
“再合并策略”是效率非常高的一种索引更新策略,主要原因在于:在对老的倒排索引进行遍历时,因为已经按照索引单词的词典序由低到高排好顺序,所以可以顺序读取文件内容,减少了磁盘寻道时间,这是其高效的根本原因。但是这种方法也有其缺点,因为要生成新的倒排索引文件,所以对于老索引中的很多单词来说,尽管其倒排列表并未发生任何变化,但是也需要将其从老索引中读取出来并写入新索引中,这种对磁盘输入输出的消耗是没有太大必要且非常耗时的。
3.6.3原地更新策略(In-Place)
原地更新策略的基本出发点,可以认为是试图改进“再合并策略”的缺点。就是说,在索引更新过程中,如果老索引的倒排列表没有变化,可以不需要读取这些信息,而只对那些倒排列表变化的单词进行处理。甚至希望能更进一步:即使老索引的倒排列表发生变化,是否可以只在其末尾进行追加操作,而不需要读取原先的倒排列表并重写到磁盘另外一个位置? 如果能够达到这个目标,明显可以大量减少磁盘读写操作,提升系统执行效率。
为了达到上述目标,原地更新策略在索引合并时,并不生成新的索引文件,而是直接在原先老的索引文件里进行追加操作(参考图3-19),将增量索引里单词的倒排列表项追加到老索引相应位置的末尾,这样就可达到上述目标,即只更新增量索引里出现的单词相关信息,其它单词相关信息不做变动。

图3-19 原地更新策略
但是这里存在一个问题:对于倒排文件中的两个相邻单词,为了在查询时加快读取速度,其倒排列表一般是顺序序列存储的,这导致没有空余位置用来追加新信息。为了能够支持追加操作,“原地更新策略”在初始建立的索引中,会在每个单词的倒排列表末尾预留出一定的磁盘空间,这样,在进行索引合并时,可以将增量索引追加到预留空间中。
图3-20是这种合并策略的一个说明。在图中,老索引中每个单词的倒排列表末尾都预留出空余磁盘空间,以作为信息追加时的存储区域。在对“新增索引”进行合并时,按照词典序,依次遍历“新增索引”中包含的单词,并对新增倒排列表的大小和老索引中相应预留空间大小进行比较,如果预留空间足够大,则将新增列表追加到老索引即可,如果预留空间不足以容纳新增倒排列表,那么此时需要在磁盘中找到一块完整的连续存储区,这个存储区足以容纳这个单词的倒排列表,之后将老索引中的倒排列表读出并写入新的磁盘位置,并将“增量索引”对应的倒排列表追加到其之后,这样就完成了一次倒排列表的“迁移”工作。

图3-20原地更新策略索引合并
在图3-20所示的例子中,可以看出,单词“技术”和“引擎”在老索引中的预留空间足够大,所以对“增量索引”只需做追加写入即可,但是对于单词“搜索”来说,其预留空间不足以容纳新增倒排列表,所以这个单词的倒排列表需要迁移到磁盘另外一个连续存储区中。
“原地更新策略”的出发点很好,但是实验数据证明其索引更新效率比“再合并策略”要低,主要是出于以下两个原因:
在这种方法中,对倒排列表进行“迁移”是比较常见的操作,为了能够进行快速迁移,需要找到足够大的磁盘连续存储区,所以这个策略需要对磁盘可用空间进行维护和管理,而这种维护和查找成本非常高,这成为该方法效率的一个瓶颈。
对于倒排文件中的相邻索引单词,其倒排列表顺序一般是按照相邻单词的词典序存储的,但是由于“原地更新策略”对单词的倒排列表做数据迁移,某些单词及其对应倒排列表会从老索引中移出,这样就破坏了这种单词连续性,导致在进行索引合并时不能顺序进行读取,必须维护一个单词到其倒排文件相应位置的映射表,而这样做,一方面降低了磁盘读取速度,另外一方面需要大量的内存来存储这种映射信息。
3.6.4混合策略(Hybrid)
混合策略的出发点是能够结合不同索引更新策略的长处,将不同的索引更新策略混合,以形成更高效的方法。
混合策略一般会将单词根据其不同性质进行分类,不同类别的单词,对其索引采取不同的索引更新策略。常见的做法是根据单词的倒排列表长度进行区分,因为有些单词经常在不同文档中出现,所以其对应的倒排列表较长,而有些单词很少见,则其倒排列表就较短。根据这一性质将单词划分为“长倒排列表单词”和“短倒排列表单词”。“长倒排列表单词”采取“原地更新策略”,而“短倒排列表单词”则采取“再合并策略”。
之所以这样做,是由于“原地更新策略”更适合“长倒排列表单词”,因为这种策略能够节省磁盘读写次数,而“长倒排列表单词”的读写开销明显要比“短倒排列表单词”大很多,所以如果采用“原地更新策略”,效果体现得比较显著。而大量“短倒排列表单词”读写开销相对而言不算太大,所以利用“再合并策略”来处理,则其顺序读写优势也能被充分利用。
原文地址:http://blog.chinaunix.net/uid-26800897-id-3143024.html