TensorFlow Object Detection API —— 制作自己的模型
在上一篇中我们已经搭建好了TensorFlow Object Detection API所需的环境,现在我们就可以构建自己的模型了,在构建自己的模型之前可以考虑需要用什么模型进行训练和之后进行预测,在这里又要祭出上一篇文章中的模型列表图了,我们可以从下图中找到自己所需要的模型下载,本文选用ssdlite_mobilenet_v2_coco进行训练,大家可以下载其它自己需要的模型进行训练。
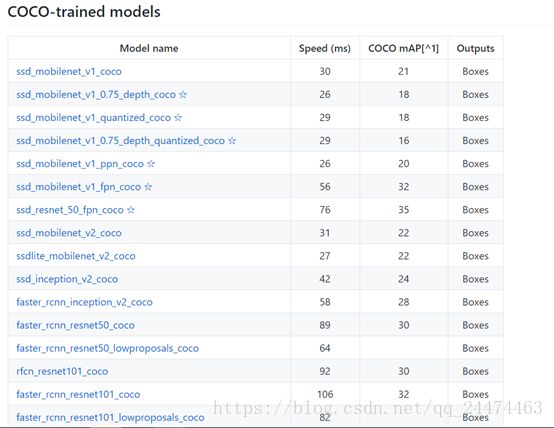
1. 构建自己的数据集
在开始训练之前我们需要构建自己的数据集,我们首先看一下官方对数据集的要求(接下来就该上图了)。

官方要求如上图,我们需要注意的是我们图片的格式需要为JPEG或者PNG,简单来说就是我们图片的后缀只能为jpg、jpeg或者是png,所以在准备图片的时候我们需要注意这些至于第二点则是对你标注的框的要求,这个我们可以不用太担心,因为我们利用工具标注出来的图片是可以满足这个要求的。
下面我们就可以开始准备自己的数据集了,小编在images2中trim目录下保存了9张wuli 颖宝的照片,在eval下保存了三张颖宝的照片,然后我们开始标注自己的数据集,首先我们下载一个LabelImg(注意哦这里是LabeLimg不是labeLLmg哦)的小工具,注意下载这个工具的路径不能有中文,如果大家去搜索的话将会是一些编译安装的一些教程在这里给出直接课运行版本的下载链接有兴趣的朋友可以进去下载使用链接如下:https://tzutalin.github.io/labelImg/
下载好后我们就开始用这个小工具给自己标注数据,打开界面如下,我们选择Open Dir打开我们保存图片的目录,然后点击选择目录,之后就可以开始标注自己的图片了我们再设置一下保存目录即Change Save Dir选择和图片所在的同一目录即可。然后我们将输入法切换为英文输入模式,按下W然后会出来一个十字架之后拖动十字架构成一个方框将要标注的目标框起来然后输入目标的名称,因为没测试过是否可以输入中文所以建议大家还是输入英文或者拼音,然后按Ctrl + S保存。

标注好数据之后我们需要将数据集转换为TensorFlow可以识别的TFRecord格式,关于这个可以参考https://blog.csdn.net/dy_guox/article/details/79111949这篇博文,在这里也是借用这篇博文中已经给出的方法来进行数据集的转换。
首先按照博文中的代码我们先将xml图片集转换为csv文件注意要将路径修改为标注的数据集所在的目录,然后将CSV文件移到object_detection下的data目录,按照博文中的CSV转TFRecord 代码(这个代码要保存在objec_detection目录下)运行一遍,类标也要修改为自己的如下图1,注意需要修改图片的路径即如下图2所示代码将图中的images可以替换成我们存储图片的目录在这里我是images2所以改成images2但是因为我们又分了trim和eval目录所以需要在那里分别添加trim和eval分两次运行,如下图3和图4所示,先按照图3修改然后打开Anaconda Prompt(虚拟环境则为Anaconda Prompt(tensorflow))运行,如图5所示运行一遍,然后按照图4修改按照如图6所示运行一遍,这样就不会遇到如7示错误,成功后就可以进行下一步了。

图1

图2
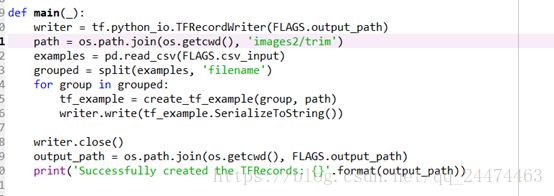
图3

图4
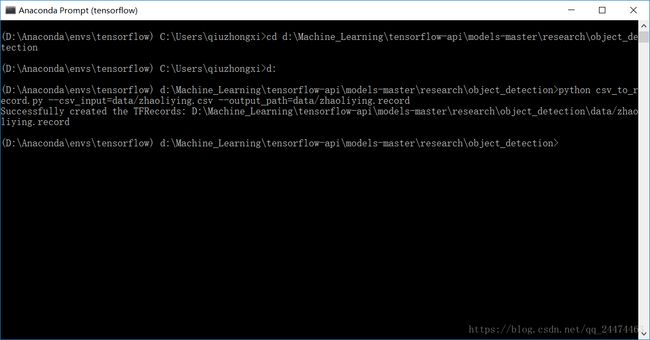
图5
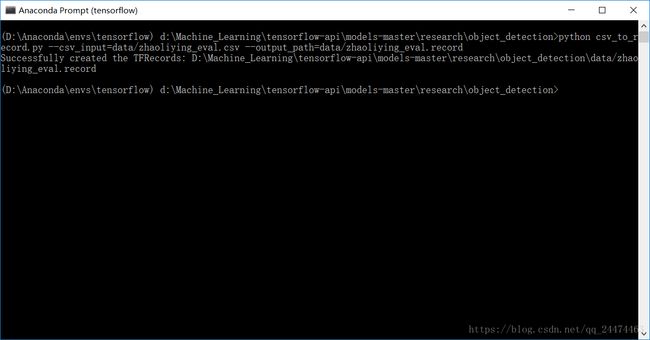
图6
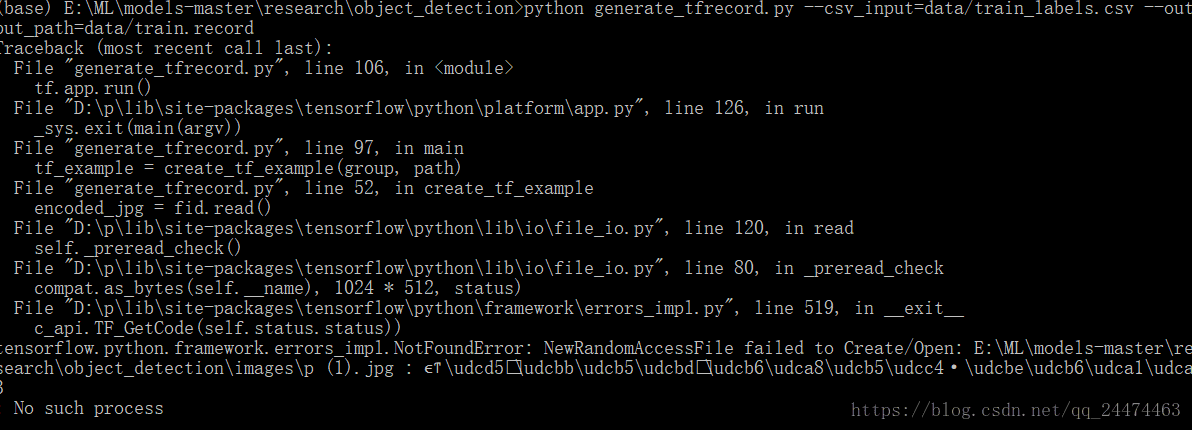
图7
2. 准备自己的配置文件
在我们下载的models-master/object_detection 下找到samples文件夹打里面的那个configs文件夹如下图所示,找到我们需要的模型的名称的文件然后打开,可以用记事本打开,比如说我们这里是ssdlite_mobilenet_v2_coco,我将这个模型下载到了object_detection的training2文件夹下,建议最好是复制一份去其它目录,在这里我将其复制到了training2这个文件夹下。
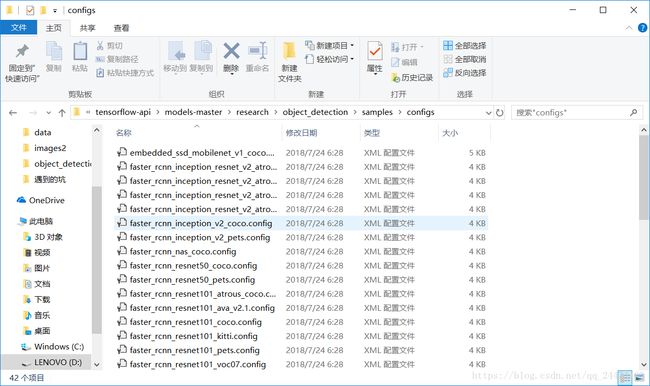
下面对我们需要的地方进行修改,下面是我们需要修改的地方
- num_classes 在这里修改为我们需要识别的目标也就是类标的数量,在这里我们是1个
- fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt" 在这里修改为模型下载解压后的目录,比如我是training2/ssdlite_mobilenet_v2_coco_2018_05_09
- train_config下的batch_size根据自己的情况来一般改为1就好用大一点的batch_size可以更快的收敛但是对GPU要求比较高所以改为1就好,如果有大型计算平台可以保持原来的不动。
- 然后就是 train_input_reader和 eval_input_reader下的input路径这里需要注意的是train_input_reader是训练的tfrecord比如我这里是zhaoliying.record,eval_input_reader是评估用的tfrecord路径在我这里是zhaoliying_eval.record
- 就是之前说的那两个中的label_map_path 我们需要创建一个自己的pbtxt文件这个是一个类标对应的文件,可以参照data文件夹下的pbtxt文件,在这里我创建了一个zhaoliying.pbtxt文件
以下为我的配置文件,仅供参考
# SSDLite with Mobilenet v2 configuration for MSCOCO Dataset.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
num_classes: 1
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 3
use_depthwise: true
box_code_size: 4
apply_sigmoid_to_scores: false
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v2'
min_depth: 16
depth_multiplier: 1.0
use_depthwise: true
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid {
}
}
localization_loss {
weighted_smooth_l1 {
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 3
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 24
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
fine_tune_checkpoint: "training2/ssdlite_mobilenet_v2_coco_2018_05_09/model.ckpt"
fine_tune_checkpoint_type: "detection"
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 200000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "data/zhaoliying.record"
}
label_map_path: "data/zhaoliying.pbtxt"
}
eval_config: {
num_examples: 8000
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "data/zhaoliying_eval.record"
}
label_map_path: "data/zhaoliying.pbtxt"
shuffle: false
num_readers: 1
}
以下是我的zhaoliying.pbtxt的格式
item {
name: "yingbao"
id: 1
}
3. 开始训练我们自己的模型
经过上面的一番周折我们现在已经可以开始训练自己的数据集了,不过还有一个小东西我们需要进行,那就是下载和安装pycocotools,有Visual Studio的童鞋请大胆的安装以下命令安装,如果遇到LINK : fatal error LNK1158: 无法运行“rc.exe”错误可以按照这个博客中的方法解决:https://blog.csdn.net/jacke121/article/details/78359820
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI如果不想安装也可以用另外一个方法绕过,不过不建议这么做,这个方法会在稍后介绍,感谢朋友水木莲花提供的对这个问题的解决方法,如果按照此方法此处需要进行的代码修改可以不用进行。在进行训练之前如果是使用python3则需要进行以下修改,需要注意的是如果读者是使用Python2进行训练那么恭喜你,你对代码不需要做任何的修改就可以完美的运行,所以可以跳过这一段修改直接进入训练过程,附上一句笔者在自己的win10上用python3这么修改后出现了梯度爆炸的错误没有训练成功但是有朋友这么训练是没问题的,根据朋友的提示将bathsize改大之后这个错误就消失了,所以大家可以尝试,因而在这里将这个方法放上,那么我们就更改object_detection下的utils\object_detection_evaluation.py 这个文件的第842行开始,改成如下图所示即可

还需要更改object_detection下的model_lib.py的第282行改成如下图1所示,第391行改成如下图2所示,第381行改为如下图3所示。
![]()
图1
![]()
图2

图3
修改object_detection/metrics下的coco_tools.py的第118行为下图所示
![]()
修改object_detection/utils下的learning_schedules.py的第172行为下图所示
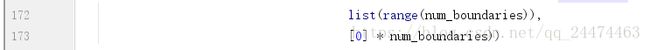
如果安装了Pycocotools并且为python2.7或者python3已经按照上述进行了修改的的童鞋请按照下面的命令开始训练:
此图为我进行训练使用的命令,可参照
- 打开Anaconda Prompt(tensorflow)
- 定位到object_detection目录
- 运行以下命令, 其中的config路径请参照自己的来,训练步长(nums_train_steps)和评估步长(nums_eval_steps)按照自己的需求来,model_dir是自己希望保存模型的目录,可以参照我下图中的来。
python model_main.py \ --pipeline_config_path=training2/ssdlite_mobilenet_v2_coco.config \ --model_dir=training2 \ --num_train_steps=50000 \ --num_eval_steps=2000 \ --alsologtostderr
下面介绍第二种方法,这种方法就可以不用修改任何代码,且可以在Windows下进行训练,但是这里修改训练步数就需要在配置文件中即ssdlite_mobilenet_v2_coco.config进行修改将其中的num_steps修改为2000,num_examples修改为200,大家可以修改为自己需要的步数,batch_size可以修改为1或者自己想要的在这里我修改为了12,如果机器性能好batch_size可以不做修改。然后打开Anaconda Prompt输入以下命令,其中的train_dir就是模型保存的目录,pipeline_config_path即训练配置的目录,可以修改为自己的。
python ./legacy/train.py --logtostderr --train_dir=training2/ --pipeline_config_path=training2/ssdlite_mobilenet_v2_coco.config如果出现如下图所示界面则进入了训练过程,我们等待它慢慢训练完毕就行。

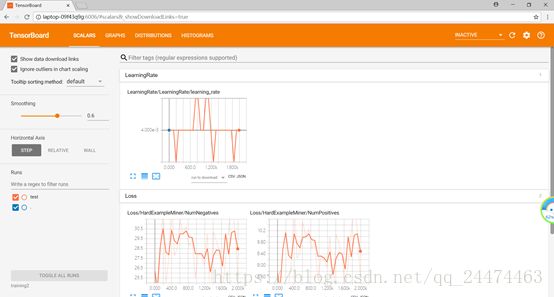
我们可以用tensorboard来查看我们的训练过程,打开另一个Anaconda Prompt(tensorflow) 窗口定位到object_detection输入下述命令,logdir用自己的训练目录替换。
tensorboard --logdir=training2然后复制出现的网址(下图中标红部分,每个人都不相同)打开浏览器,将其输入地址栏中访问就可以进入tensorboard了。
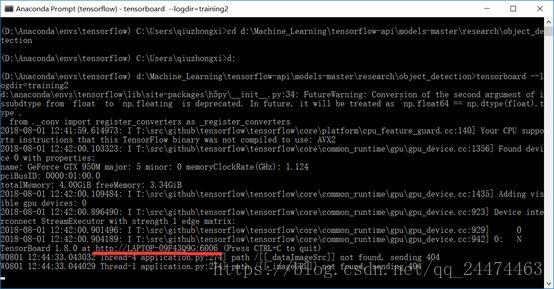
下图是我在Windows下运行的截图,这次是用CPU跑的,运行的时间较长,推荐大家使用GPU进行训练,当然机器不满足我们就用CPU来跑一下,等久一点就行了。
对模型进行评估(可选)
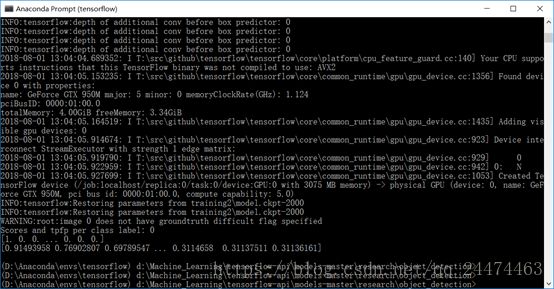
首先我在我的训练目录training2下建立了一个名为eval的文件夹,然后我们打开Anaconda Prompt(tensorflow) 定位到object_detection,输入下述命令,其中training2为之前我们训练的路径,根据自己的实际情况进行修改。
python ./legacy/eval.py --logtostderr --checkpoint_dir=training2 --pipeline_config_path=training2/ssdlite_mobilenet_v2_coco.config --eval_dir=training2/eval/下图是评测的一个结果,可以做一个简单的评估,具体怎么理解大家可以自行去搜索(注:估计这个评测结果大家都会认为不咋地,所以这个步骤大家可以省略,而且如果是用model_main.py训练那么训练过程中自动进行的eval就已经非常不错了)。
4. 生成可被调用的模型
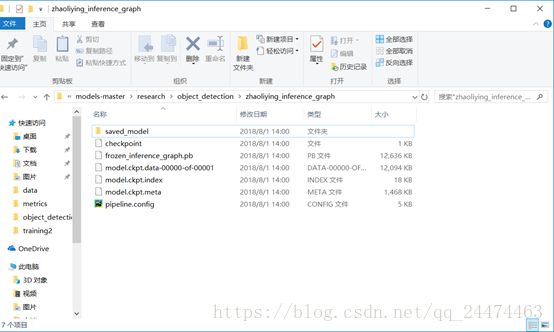
打开Anaconda Prompt定位到object_detection下执行下述命令,其中model.ckpt选择训练目录中最大的数值,然后输出目录由自己定义,注意根据实际情况进行替换。
python export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path training2/ssdlite_mobilenet_v2_coco.config \
--trained_checkpoint_ prefix training2/model.ckpt-2000 \
--output_directory zhaoliying_inference_graph
执行后在输出目录会生成下图中的一些文件
5.使用自己的模型进行测试
在object_detection下建立一个名为my_model.py的文件,具体可参照之前我们用notebook打开的sample来进行修改,下面为我的代码,可以参考,参考自博客: https://blog.csdn.net/dy_guox/article/details/79111949。
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 1 14:09:11 2018
@author: qiuzhongxi
"""
#Imports
import time
start = time.time()
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
import scipy.misc
if tf.__version__ < '1.4.0':
raise ImportError('Please upgrade your tensorflow installation to v1.4.* or later!')
os.chdir('D:\\Machine_Learning\\tensorflow-api\\models-master\\research\\object_detection')
#Env setup
# This is needed to display the images.
#%matplotlib inline
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
#Object detection imports
from utils import label_map_util
from utils import visualization_utils as vis_util
#这是我们刚才训练的模型,修改为自己输出的模型目录名
MODEL_NAME = 'zhaoliying_inference_graph'
#对应的Frozen model位置
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'zhaoliying.pbtxt')
#改成自己例子中的类别数,1
NUM_CLASSES = 1
#Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
#Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
#Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
#Detection
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
#测试图片位置
PATH_TO_TEST_IMAGES_DIR = os.getcwd()+'/test_images3'
os.chdir(PATH_TO_TEST_IMAGES_DIR)
TEST_IMAGE_PATHS = os.listdir(PATH_TO_TEST_IMAGES_DIR)
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
#修改为自己的目录,必须存在该文件夹
output_path = ('D:\\Machine_Learning\\tensorflow-api\\models-master\\research\\object_detection\\zhaoliying\\')
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
#保存文件
im=scipy.misc.toimage(image_np, cmin=0.0, cmax=...)
im.save(output_path+image_path.split('\\')[-1])
end = time.time()
print("Execution Time: ", end - start)
用python执行上述代码,最后输出的两张图片如下,可见模型的效果还有待提高,这个和我的数据集的大小有比较大的关系,增加训练步数也可也提高模型的质量,才刚开始写文,如有错误请海涵,欢迎大家一起交流。

