TextCNN 与 FastText 文本分类实战【Embedding|Word2Vec】
具体的理论知识,可以看看前面几篇文章,有详细介绍,这里直接po代码了
# -*- coding: utf-8 -*-
"""
@Author: xkk
@Date: 2018-09-07 12:42:37
@Last Modified by: xkk
@Last Modified time: 2018-09-07 12:42:37
"""
import jieba
import pandas as pd
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.models import Model
from keras.layers import Input
from keras.layers import Embedding
from keras.layers import Dense
from keras.layers import Dropout,Conv1D,MaxPooling1D,Flatten
from keras.layers import GlobalAveragePooling1D
from keras.layers import SpatialDropout1D
from keras.layers import concatenate
from sklearn.model_selection import train_test_split
from keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau, LearningRateScheduler
def build_fasttext(args):
inputs = Input(shape=(args['MAX_LENTH'],), dtype='int32')
embedder = Embedding(args['VOCAB_SIZE']+1, args['EMB_DIM'])
embedded = embedder(inputs)
embedded = SpatialDropout1D(0.25)(embedded)
mean_pool = GlobalAveragePooling1D()(embedded)
outputs = Dense(21, activation='softmax')(mean_pool)
model = Model(inputs, outputs)
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['acc'])
return model
def text_cnn(args):
seq = Input(shape=[args['MAX_LENTH']])
embed = Embedding(args['VOCAB_SIZE'],args['EMB_DIM'])(seq)
conv_cat=[]
filter_sizes = [2,3,4,5]
for fil in filter_sizes:
conv = Conv1D(filters=100,kernel_size=fil,activation='relu')(embed)
pool = MaxPooling1D(args['MAX_LENTH']-fil+1)(conv)
fla = Flatten()(pool)
conv_cat.append(fla)
merge = concatenate(conv_cat,axis=1)
drop_1 = Dropout(0.5)(merge)
dens = Dense(1024,activation='relu')(drop_1)
drop_2 = Dropout(0.5)(dens)
out= Dense(21,activation='relu')(drop_2)
model =Model([seq],out)
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['acc'])
return model
if __name__ == '__main__':
args = {
'MAX_LENTH': 1000,
'VOCAB_SIZE': 400000,
'EMB_DIM': 300
}
'''
df = pd.read_csv('./data/train_data.txt', sep='\t', encoding='utf-8')
tr_y = df['label'].values-1
texts = df['jd'].astype('str').tolist()
tokenizer = Tokenizer(num_words=400000)
tokenizer.fit_on_texts(texts)
tr_x = tokenizer.texts_to_sequences(texts)
del texts
tr_x = pad_sequences(tr_x, args['MAX_LENTH'], dtype='int32')
np.save('./data/tr_x', tr_x)
np.save('./data/tr_y', tr_y)
'''
tr_x=np.load('./data/tr_x.npy')
tr_y=np.load('./data/tr_y.npy')
X_train, X_test, y_train, y_test = train_test_split(
tr_x, tr_y, test_size=0.2, random_state=2018, shuffle=True)
filepath = 'best_textcnn.model'
checkpoint = ModelCheckpoint(
filepath, monitor='val_acc', verbose=1, save_weights_only=True, save_best_only=True, mode='max')
early_stop = EarlyStopping(monitor='val_acc', patience=5, mode='max')
call_backs = [checkpoint, early_stop]
# model = build_fasttext(args)
# y_train = to_categorical(y_train, 21)
# y_test = to_categorical(y_test, 21)
# model.fit(X_train, y_train, validation_data=[
# X_test, y_test], epochs=3000, callbacks=call_backs, shuffle=True,batch_size=128)
model = text_cnn(args)
y_train = to_categorical(y_train, 21)
y_test = to_categorical(y_test, 21)
model.fit(X_train, y_train, validation_data=[
X_test, y_test], epochs=3000, callbacks=call_backs, shuffle=True,batch_size=128)
有个地方要注意哈,concatenat要用keras包里的,不能用np的,因为keras是先预编译模型,再执行,而np直接就执行了,会报错。
关于embedding层的参数解释:
Embedding层只能作为模型的第一层
参数
input_dim:大或等于0的整数,字典长度,即输入数据最大下标+1
output_dim:大于0的整数,代表全连接嵌入的维度
embeddings_initializer: 嵌入矩阵的初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
embeddings_regularizer: 嵌入矩阵的正则项,为Regularizer对象
embeddings_constraint: 嵌入矩阵的约束项,为Constraints对象
mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常。如果该值为True,则下标0在字典中不可用,input_dim应设置为|vocabulary| + 2。
input_length:当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
输入shape
形如(samples,sequence_length)的2D张量
输出shape
形如(samples, sequence_length, output_dim)的3D张量
单词表大小为400000,词向量的维度为300,所以Embedding的参数 input_dim=400000,output_dim=300
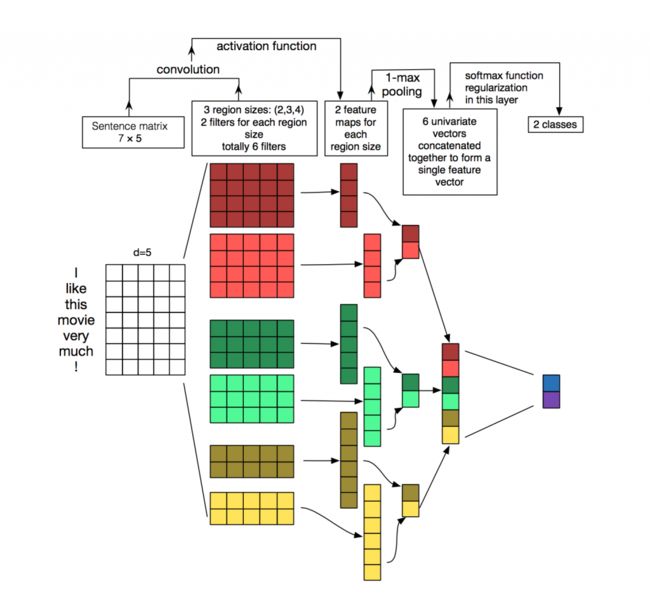
再放一个经典的网络图:【这里我们用了100个filters,意味着 对于每种高度的卷积核,我们都引入了100个随机核】