基于BiLinear的VGG16+ResNet50,用于细粒度图像分类
细粒度视觉识别之双线性CNN模型
[1] Lin T Y, RoyChowdhury A, Maji S. Bilinear cnn models for fine-grained visual recognition[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 1449-1457.
[2] Lin T Y, RoyChowdhury A, Maji S. Bilinear CNNs for Fine-grained Visual Recognition//arXiv. 2017.
摘要
- 定义:双线性CNN模型:包含两个特征提取器,其输出经过外积(外积WiKi)相乘、池化后获得图像描述子。
- 优点:
- 该架构能够以平移不变的方式,对局部的对级(pairwise)特征交互进行建模,适用于细粒度分类。
- 能够泛化多种顺序无关的特征描述子,如Fisher 向量,VLAD及O2P。实验中使用使用卷积神经网络的作为特征提取器的双线性模型。
- 双线性形式简化了梯度计算,能够对两个网络在只有图像标签的情况下进行端到端训练。
- 实验结果:
- 对ImageNet数据集上训练的网络进行特定领域的微调,该模型在CUB200-2011数据集上,训练时达到了84.1%的准确率。
- 作者进行了实验及可视化以分析微调的效果,并在考虑模型速度和精确度的情况下选择了两路网络。
- 结果显示,该架构在大多数细粒度数据集上都可以与先前算法相媲美,并且更加简洁、易于训练。更重要的是,准确率最高的模型可以在NVIDIA Tesla K40 GPU上以8 f/s的速度高效运行。代码链接:http://vis-www.cs.umass.edu/bcnn
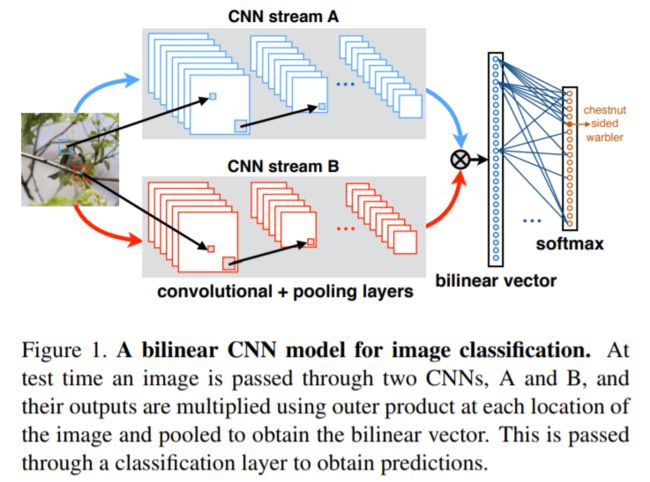
介绍
-
细粒度识别
对同属一个子类的物体进行分类,通常需要对高度局部化、且与图像中姿态及位置无关的特征进行识别。例如,“加利福尼亚海鸥”与“环状海鸥”的区分就要求对其身体颜色纹理,或羽毛颜色的微细差异进行识别。
通常的技术分为两种:- 局部模型:先对局部定位,之后提取其特征,获得图像特征描述。缺陷:外观通常会随着位置、姿态及视角的改变的改变。
- 整体模型:直接构造整幅图像的特征表示。包括经典的图像表示方式,如Bag-of-Visual-Words,及其适用于纹理分析的多种变种。
基于CNN的局部模型要求对训练图像局部标注,代价昂贵,并且某些类没有明确定义的局部特征,如纹理及场景。
-
作者思路
- 局部模型高效性的原因:本文中,作者声称局部推理的高效性在于其与物体的位置及姿态无关。纹理表示通过将图像特征进行无序组合的设计,而获得平移无关性。
- 纹理表征性能不佳的思考:基于SIFT及CNN的纹理表征已经在细粒度物体识别上显示出高效性,但其性能还亚于基于局部模型的方法。其可能原因就是纹理表示的重要特征并没有通过端到端训练获得,因此在识别任务中没有达到最佳效果。
- 洞察点:某些广泛使用的纹理表征模型都可以写作将两个合适的特征提取器的输出,外积之后,经池化得到。
- 首先,(图像)先经过CNNs单元提取特征,之后经过双线性层及池化层,其输出是固定长度的高维特征表示,其可以结合全连接层预测类标签。最简单的双线性层就是将两个独立的特征用外积结合。这与图像语义分割中的二阶池化类似。
-
实验结果:作者在鸟类、飞机、汽车等细粒度识别数据集上对模型性能进行测试。表明B-CNN性能在大多细粒度识别的数据集上,都优于当前模型,甚至是基于局部监督学习的模型,并且相当高效。
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 18 00:28:01 2018
@author: Administrator
"""
import matplotlib.pyplot as plt
from keras.applications.inception_v3 import InceptionV3
from keras.applications.resnet50 import ResNet50
from keras.applications.vgg16 import VGG16
from keras.models import Sequential
from keras.models import Model
from keras.utils import np_utils
from keras.layers import Convolution2D,Activation,MaxPooling2D,Flatten,Dense,Dropout,Input,Reshape,Lambda
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
from keras import backend as K
from keras.utils import plot_model
import numpy as np
from keras.callbacks import ModelCheckpoint,EarlyStopping,LearningRateScheduler,ReduceLROnPlateau
def sign_sqrt(x):
return K.sign(x) * K.sqrt(K.abs(x) + 1e-10)
def l2_norm(x):
return K.l2_normalize(x, axis=-1)
def batch_dot(cnn_ab):
return K.batch_dot(cnn_ab[0], cnn_ab[1], axes=[1, 1])
def bilinearnet():
input_tensor = Input(shape=(384,512,3))
vgg16 = VGG16(weights='imagenet', include_top=False,input_tensor=input_tensor)
# conv2048 = Convolution2D(filters=2048,kernel_size=(3,3),)
# vgg16_add_conv_to_2048 = Model(inputs=input_tensor,outputs=)
resnet50 = ResNet50(weights='imagenet', include_top=False,input_tensor=input_tensor)
model_vgg16 = Model(inputs=input_tensor,outputs=vgg16.output)
model_resnet50 = Model(inputs=input_tensor,outputs=resnet50.output)
model_vgg16.compile(loss='categorical_crossentropy',optimizer='adam')
model_resnet50.compile(loss='categorical_crossentropy',optimizer='adam')
resnet50_x = Reshape([model_resnet50.layers[-6].output_shape[1]*model_resnet50.layers[-6].output_shape[2],model_resnet50.layers[-6].output_shape[3]])(model_resnet50.layers[-6].output)
vgg16_x = Reshape([model_vgg16.layers[-1].output_shape[1]*model_vgg16.layers[-1].output_shape[2],model_vgg16.layers[-1].output_shape[3]])(model_vgg16.layers[-1].output)
cnn_dot_out = Lambda(batch_dot)([vgg16_x,resnet50_x])
sign_sqrt_out = Lambda(sign_sqrt)(cnn_dot_out)
l2_norm_out = Lambda(l2_norm)(sign_sqrt_out)
flatten = Flatten()(l2_norm_out)
dropout = Dropout(0.5)(flatten)
output = Dense(12, activation='softmax')(dropout)
model = Model(input_tensor, output)
model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9, decay=1e-6),
metrics=['accuracy'])
print(model.summary())
plot_model(model,to_file='vgg_resnet_bilinear_model.png')
return model
# print(vgg16_x.shape)
# print(resnet50_x.shape)
# print(cnn_dot_out.shape)
# print(model_vgg16.summary())
'''
vgg16
block5_conv1 (Conv2D) (None, 24, 32, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 24, 32, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 24, 32, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 12, 16, 512) 0
resnet50
bn5c_branch2c (BatchNormalizati (None, 12, 16, 2048) 8192 res5c_branch2c[0][0]
__________________________________________________________________________________________________
add_112 (Add) (None, 12, 16, 2048) 0 bn5c_branch2c[0][0]
activation_340[0][0]
__________________________________________________________________________________________________
activation_343 (Activation) (None, 12, 16, 2048) 0 add_112[0][0]
__________________________________________________________________________________________________
'''
# print(model_resnet50.summary())
# vgg16.layers[]
#
#def categorical_crossentropy(y_true, y_pred):
# return K.categorical_crossentropy(y_true, y_pred)
#
#
#model = VGG16(weights='imagenet', include_top=False,input_shape=(384, 512,3))
##print('youdianmeng')
#top_model = Sequential()
#top_model.add(Flatten(input_shape=model.output_shape[1:])) # model.output_shape[1:])
#top_model.add(Dropout(0.5))
#top_model.add(Dense(12, activation='softmax'))
## 载入上一模型的权重
#
#ftvggmodel = Model(inputs=model.input, outputs=top_model(model.output))
##for layer in ftvggmodel.layers[:25]:
## layer.trainable=True
#
#ftvggmodel.compile(loss=categorical_crossentropy,
# optimizer=optimizers.SGD(lr=1e-4, momentum=0.90,decay=1e-5),metrics=['accuracy'])
##
train_data_gen = ImageDataGenerator(rescale=1/255.,
samplewise_center=True,
samplewise_std_normalization=True,
# zca_whitening=True,
# zca_epsilon=1e-6,
width_shift_range=0.05,
height_shift_range=0.05,
fill_mode='reflect',
horizontal_flip=True,
vertical_flip=True)
test_data_gen = ImageDataGenerator(rescale=1/255.)
#
train_gen = train_data_gen.flow_from_directory(directory='D:\\xkkAI\\ZZN\\guangdong\\train',
target_size=(384, 512), color_mode='rgb',
class_mode='categorical',
batch_size=5, shuffle=True, seed=222
)
val_gen = test_data_gen.flow_from_directory(directory='D:\\xkkAI\\ZZN\\guangdong\\val',
target_size=(384, 512), color_mode='rgb',
class_mode='categorical',
batch_size=5, shuffle=True, seed=222
)
test_gen = test_data_gen.flow_from_directory(directory='D:\\xkkAI\\ZZN\\guangdong\\test',
target_size=(384, 512), color_mode='rgb',
class_mode='categorical',
batch_size=5
)
cp = ModelCheckpoint('guangdong_best_vgg16.h5', monitor='val_loss', verbose=1,
save_best_only=True, save_weights_only=False,
mode='auto', period=1)
es = EarlyStopping(monitor='val_loss',
patience=8, verbose=1, mode='auto')
lr_reduce = ReduceLROnPlateau(monitor='val_loss', factor=0.1, epsilon=1e-5, patience=2, verbose=1, min_lr = 0.00000001)
callbackslist = [cp,es,lr_reduce]
ftvggmodel = bilinearnet()
ftvggmodel.fit_generator(train_gen,
epochs=1111,
verbose=1,
callbacks=callbackslist,
validation_data=val_gen,
shuffle=True)
#ftvggmodel.load_weights('guangdong_best_vgg16.h5')
pred = ftvggmodel.predict_generator(test_gen)
defectlist=['norm','defect1','defect2','defect3','defect4','defect5','defect6','defect7','defect8','defect9','defect10','defect11']
import csv
with open('lvcai_result.csv','w') as f:
w = csv.writer(f)
for i in range(len(pred)):
w.writerow([str(i)+'.jpg',defectlist[np.argmax(pred[i])]])
