Kafka结合Spark-streaming 的两种连接方式(AWL与直连)
kafka结合spark-streaming的用法及说明之前博客有些,这里就不赘述了。
这篇文章说下他们结合使用的两种连接方式。(AWL与直连)
先看一张图:
这是kafka与streaming结合的基本方式,如图spark集群中的 worker节点中 exeutor线程里的 receiver接口会一直消费kafka中的数据,那么问题来了,假如我们定义5秒消费一次,如果spark集群定义了每个worker使用的cpu资源不足以消费完了这5秒的数据,那么就会出现数据的丢失,消费不了的那些数据就没了,并且streaming一经启动会一直循环消费拉取资源,如果出现上述问题,分配的cpu不足以消费5秒拉取的数据,那么丢失的数据便会越积越多,这在程序里是严重的bug。
现在处理这种情况有两种方式,write ahead logs (AWL) 方式与直连方式。
上面那种图说的就是awl方式,这种方式是以前常用的方式,我们在程序里对streamingContext初始化后,得到她的对象进行checkpoint("hdfs://xxxx/xx") 即可,这样程序会默认把日志偏移量存到hdfs上面做备份,防止数据丢失,但是这样会影响性能。
另外一种方式也是公司常用的方式就是 直连方式,如图:
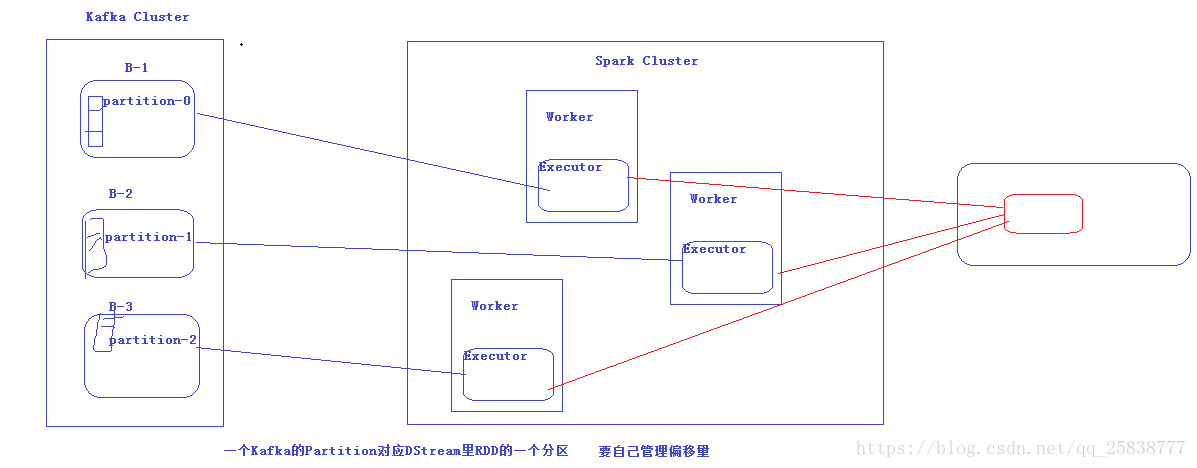
直连方式就是使用executor直接连接kakfa节点,我们自定义偏移量的使用大小及存储备份方法。
1.直连方式从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,实现零数据丢失,保证不重复消费,比createStream更高效;
2.创建的DStream的rdd的partition做到了和Kafka中topic的partition一一对应。
1.3版本可以直接通过低阶API从kafka的topic消费消息,并且不再向zookeeper中更新consumer offsets,使得基于zookeeper的consumer offsets的监控工具都会失效。所以更新zookeeper中的consumer offsets还需要自己去实现,并且官方提供的两个createDirectStream重载并不能很好的满足我的需求,需要进一步封装。
因此,在采用直连的方式消费kafka中的数据的时候,大体思路是首先获取保存在zookeeper中的偏移量信息,根据偏移量信息去创建stream,消费数据后再把当前的偏移量写入zk中。
下面是在网上搜的并亲测可用的直连方式的工具代码,大家有需要可以参考下。(wordcount求和程序)
package cn.itcast.spark.day5
import kafka.serializer.StringDecoder
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.kafka.{KafkaManager, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectKafkaWordCount {
/* def dealLine(line: String): String = {
val list = line.split(',').toList
// val list = AnalysisUtil.dealString(line, ',', '"')// 把dealString函数当做split即可
list.get(0).substring(0, 10) + "-" + list.get(26)
}*/
def processRdd(rdd: RDD[(String, String)]): Unit = {
val lines = rdd.map(_._2)
val words = lines.map(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.foreach(println)
}
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println(
s"""
|Usage: DirectKafkaWordCount
| is a list of one or more Kafka brokers
| is a list of one or more kafka topics to consume from
| is a consume group
|
""".stripMargin)
System.exit(1)
}
Logger.getLogger("org").setLevel(Level.WARN)
val Array(brokers, topics, groupId) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
sparkConf.setMaster("local[*]")//最大cpu核数
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "5") //每秒拉取5条
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val ssc = new StreamingContext(sparkConf, Seconds(2)) //两秒一次
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers, //直接连接 brokers,不用通过zk连接管理元数据了
"group.id" -> groupId,
"auto.offset.reset" -> "smallest"
)
val km = new KafkaManager(kafkaParams)
val messages = km.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
messages.foreachRDD(rdd => {
if (!rdd.isEmpty()) {
// 先处理消息
processRdd(rdd)
// 再更新offsets
km.updateZKOffsets(rdd)
}
})
ssc.start()
ssc.awaitTermination()
}
}
package org.apache.spark.streaming.kafka
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.Decoder
import org.apache.spark.SparkException
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaCluster.LeaderOffset
import scala.reflect.ClassTag
/**
* 自己管理offset
*/
class KafkaManager(val kafkaParams: Map[String, String]) extends Serializable {
private val kc = new KafkaCluster(kafkaParams)
/**
* 创建数据流
*/
def createDirectStream[K: ClassTag, V: ClassTag, KD <: Decoder[K]: ClassTag, VD <: Decoder[V]: ClassTag](
ssc: StreamingContext, kafkaParams: Map[String, String], topics: Set[String]): InputDStream[(K, V)] = {
val groupId = kafkaParams.get("group.id").get
// 在zookeeper上读取offsets前先根据实际情况更新offsets
setOrUpdateOffsets(topics, groupId)
//从zookeeper上读取offset开始消费message
val messages = {
val partitionsE = kc.getPartitions(topics)
if (partitionsE.isLeft)
throw new SparkException(s"get kafka partition failed: ${partitionsE.left.get}")
val partitions = partitionsE.right.get
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if (consumerOffsetsE.isLeft)
throw new SparkException(s"get kafka consumer offsets failed: ${consumerOffsetsE.left.get}")
val consumerOffsets = consumerOffsetsE.right.get
KafkaUtils.createDirectStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, consumerOffsets, (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message))
}
messages
}
/**
* 创建数据流前,根据实际消费情况更新消费offsets
* @param topics
* @param groupId
*/
private def setOrUpdateOffsets(topics: Set[String], groupId: String): Unit = {
topics.foreach(topic => {
var hasConsumed = true
val partitionsE = kc.getPartitions(Set(topic))
if (partitionsE.isLeft)
throw new SparkException(s"get kafka partition failed: ${partitionsE.left.get}")
val partitions = partitionsE.right.get
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if (consumerOffsetsE.isLeft) hasConsumed = false
if (hasConsumed) {// 消费过
/**
* 如果streaming程序执行的时候出现kafka.common.OffsetOutOfRangeException,
* 说明zk上保存的offsets已经过时了,即kafka的定时清理策略已经将包含该offsets的文件删除。
* 针对这种情况,只要判断一下zk上的consumerOffsets和earliestLeaderOffsets的大小,
* 如果consumerOffsets比earliestLeaderOffsets还小的话,说明consumerOffsets已过时,
* 这时把consumerOffsets更新为earliestLeaderOffsets
*/
val earliestLeaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)
if (earliestLeaderOffsetsE.isLeft)
throw new SparkException(s"get earliest leader offsets failed: ${earliestLeaderOffsetsE.left.get}")
val earliestLeaderOffsets = earliestLeaderOffsetsE.right.get
val consumerOffsets = consumerOffsetsE.right.get
// 可能只是存在部分分区consumerOffsets过时,所以只更新过时分区的consumerOffsets为earliestLeaderOffsets
var offsets: Map[TopicAndPartition, Long] = Map()
consumerOffsets.foreach({ case(tp, n) =>
val earliestLeaderOffset = earliestLeaderOffsets(tp).offset
if (n < earliestLeaderOffset) {
println("consumer group:" + groupId + ",topic:" + tp.topic + ",partition:" + tp.partition +
" offsets已经过时,更新为" + earliestLeaderOffset)
offsets += (tp -> earliestLeaderOffset)
}
})
if (!offsets.isEmpty) {
kc.setConsumerOffsets(groupId, offsets)
}
} else {// 没有消费过
val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase)
var leaderOffsets: Map[TopicAndPartition, LeaderOffset] = null
if (reset == Some("smallest")) {
val leaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)
if (leaderOffsetsE.isLeft)
throw new SparkException(s"get earliest leader offsets failed: ${leaderOffsetsE.left.get}")
leaderOffsets = leaderOffsetsE.right.get
} else {
val leaderOffsetsE = kc.getLatestLeaderOffsets(partitions)
if (leaderOffsetsE.isLeft)
throw new SparkException(s"get latest leader offsets failed: ${leaderOffsetsE.left.get}")
leaderOffsets = leaderOffsetsE.right.get
}
val offsets = leaderOffsets.map {
case (tp, offset) => (tp, offset.offset)
}
kc.setConsumerOffsets(groupId, offsets)
}
})
}
/**
* 更新zookeeper上的消费offsets
* @param rdd
*/
def updateZKOffsets(rdd: RDD[(String, String)]) : Unit = {
val groupId = kafkaParams.get("group.id").get
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (offsets <- offsetsList) {
val topicAndPartition = TopicAndPartition(offsets.topic, offsets.partition)
val o = kc.setConsumerOffsets(groupId, Map((topicAndPartition, offsets.untilOffset)))
if (o.isLeft) {
println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
}
}
Direct 读取问题
在实际的应用中,Direct Approach方式很好地满足了我们的需要,与Receiver-based方式相比,有以下几方面的优势:
1,降低资源。Direct不需要Receivers,其申请的Executors全部参与到计算任务中;而Receiver-based则需要专门的Receivers来读取Kafka数据且不参与计算。因此相同的资源申请,Direct 能够支持更大的业务。
2,降低内存。Receiver-based的Receiver与其他Exectuor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并无需那么多的内存。而Direct 因为没有Receiver,而是在计算时读取数据,然后直接计算,所以对内存的要求很低。实际应用中我们可以把原先的10G降至现在的2-4G左右。
3,鲁棒性更好。Receiver-based方法需要Receivers来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receivers却还在持续读取数据,此种情况很容易导致计算崩溃。Direct 则没有这种顾虑,其Driver在触发batch 计算任务时,才会读取数据并计算。队列出现堆积并不会引起程序的失败。
但是也存在一些不足,具体如下:
1,提高成本。Direct需要用户采用checkpoint或者第三方存储来维护offsets,而不像Receiver-based那样,通过ZooKeeper来维护Offsets,此提高了用户的开发成本。
2,监控可视化。Receiver-based方式指定topic指定consumer的消费情况均能通过ZooKeeper来监控,而Direct则没有这种便利,如果做到监控并可视化,则需要投入人力开发。