CS224n-08 Recurrent Neural Networks and Language Models
08 Recurrent Neural Networks and Language Models
内容提要:
1、传统的语言模型
2、RNNs
3、RNN语言模型
4、重要的训练问题和技巧
(1)梯度消失问题的一个例子
(2)梯度消失和爆炸
5、其他序列任务中的RNNS
6、双向和深度RNNs
语言模型:
语言模型就是用来计算句子中单词序列出现的概率:
 ,在机器翻译中是有用处的。
,在机器翻译中是有用处的。
1、词序(Word ordering):p(the cat is small) > p(small the is cat)
2、词汇选择(Word choice):p(walking home after school) > p(walking house after school)
传统的机器翻译:
1、在窗口(上下文中)计算n个词的条件概率。
2、一个不恰当但是正确的马尔科夫假设。
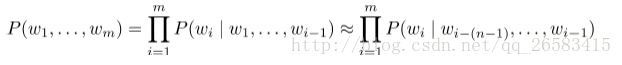
3、为单个或者两个词计算概率(条件是在以前的一个或者两个词上)(根据前面的词计算后面的概率)。
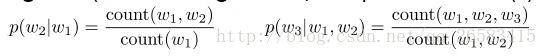
4、性能的提升是由于保持更高的n-grams计数和做一些平滑处理,所以叫做补偿(e.g. if 4-gram not found, try 3-gram, etc))。
5、更多的n-grams带来了更多的内存需求。
循环神经网络(RNN,Recurrent Neural Networks!):
1、RNN在每个时间步例共享权重。
2、之前所有的单词都是影响神经网络的条件。
3、
内存只与词表大小成正比,不取决于序列长度。

RNN语言模型
给定一系列词向量:
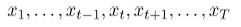 。
。
在一个时间步上:
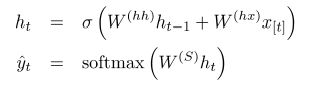 ,
,

,
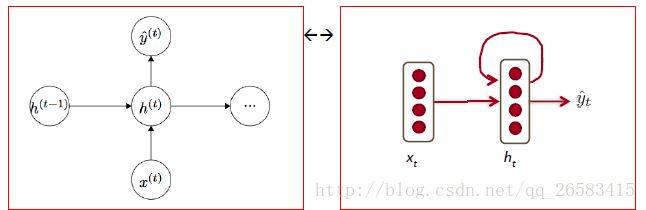
输出的softmax值可以判断每一个时间步上词汇表中的词,在这个地方的出现的条件概率。
核心思想:使用相同的权重W在每一个时间步中。

相同的交叉熵损失,但是用预测词来代替类别:

为了计算方便(很多细节处理在吴恩达的深度学习可中详细说明)变为:
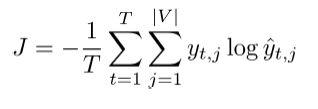
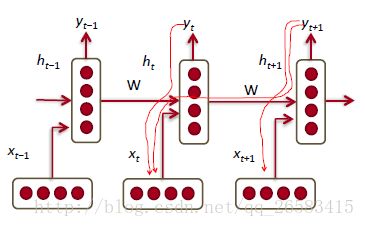
训练一个RNNs模型很困难:
1、前向传播的时候每一个时间步都具有相同的矩阵。

2、从过去了很多时间步的输入来改变输出y是理性情况。(长序列预测问题)
3、梯度(损失求导),出现梯度消失和爆炸问题。
梯度消失和爆炸问题:
1、反向传播的时候每一个时间步都具有相同的矩阵。
梯度消失细节:
1、相同的更简单的RNN公式:
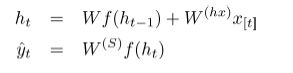
2、总误差是每个时间步上误差之和:
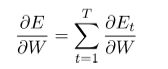
3、链式规则的应用:
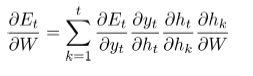
4、反向传播中相同的但是更有效的公式:
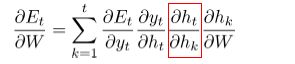
5、记住:
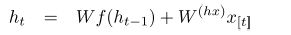
6、更多的链式规则:
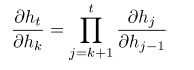
7、雅克比矩阵的每个部分:

梯度为什么会消失?
在反向传播的时候理想上每一步的误差才能告诉以前的时间步去改变。
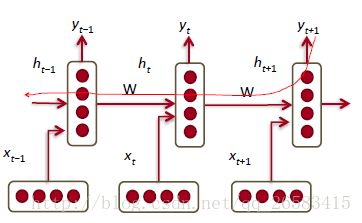
语言模型中的梯度消失:
在语言建模或问答问题的情况下,当训练预测下一个单词时,没有考虑到很远的距离。

IPython Notebook中的梯度消失例子:
1、简单清晰地神经网络实现。
2、比较sigmoid和ReLu激活函数。
3、梯度消失问题。
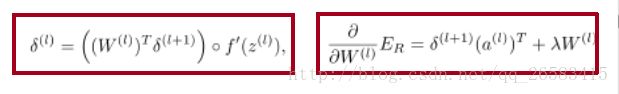
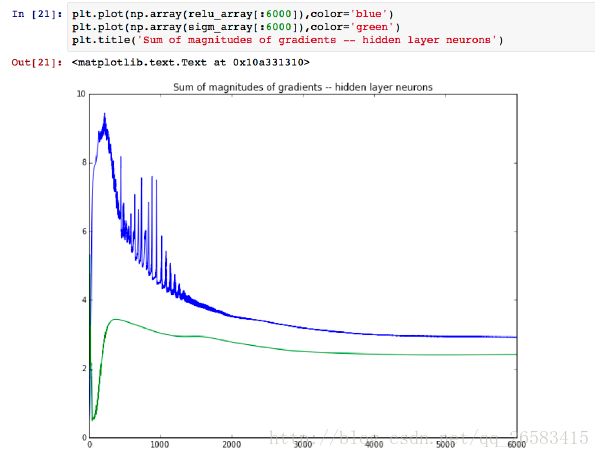
比较sigmoid和ReLu两个激活函数的梯度变化。
梯度爆炸的改善技巧:裁剪
1、这个方法是由Mikolov提出来的,是为了裁剪暴涨的梯度。

2、这种方法在RNN中这样是大不一样的。
一种暴力的方法是,当梯度的长度大于某个阈值的时候,将其缩放到某个阈值。虽然在数学上非常丑陋,但实践效果挺好。
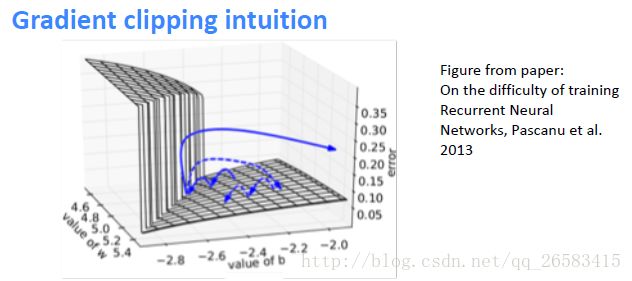
(1)一个简单的RNN隐层误差表面图。
(2)高曲率
(3)实线是标准的梯度下降轨迹线。
(4)短虚线是梯度调整之后的线。
梯度消失解决方法:初始化+ReLus
1、将随机初始化参数改为初始化为一个单位矩阵(W)。
2、用ReLus代替sigmod激活函数
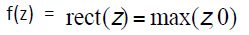
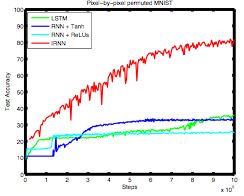

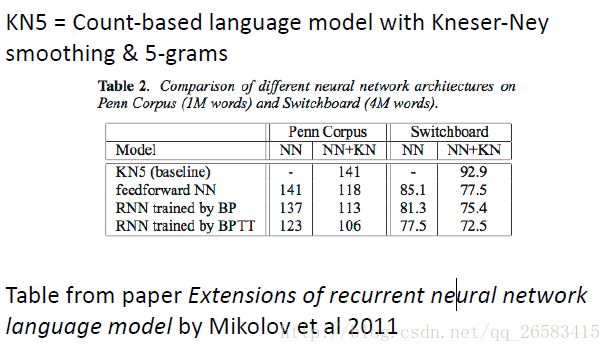
困惑度结果(Perplexity Results):
相较于传统的NGram,RNN的困惑度要小一些。
问题:softmax很大很慢
技巧:基于类别的词预测(类别分的越多越细困惑度越好,但是计算速度越慢)
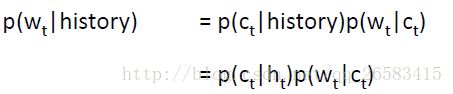
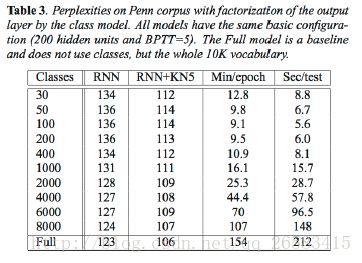
一个最后实现的技巧:你只需要经历一次反向传播,并且累加每一个时间步t的误差。
序列模型完成其他任务:
分类每一个词:
NER(命名实体识别)
Entity level sentiment in context(实体层面的情感分析)
opinionated expressions(意见表达)

用深度RNN进行观点挖掘:
目标:分类每一个词
直接的主观表达(DSEs,direct subjective expressions)
间接地主观表达(ESEs,expressive subjective expressions)
标注例子(经典的BIO方法):

方法:循环神经网络
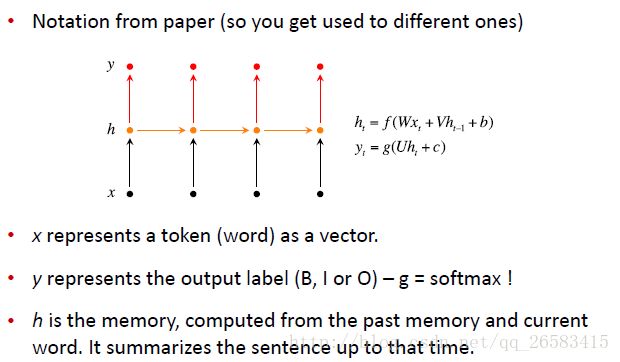
但是这个网络无法利用当前词语的下文辅助分类决策,解决方法是使用一些更复杂的RNN变种。
双向RNN:
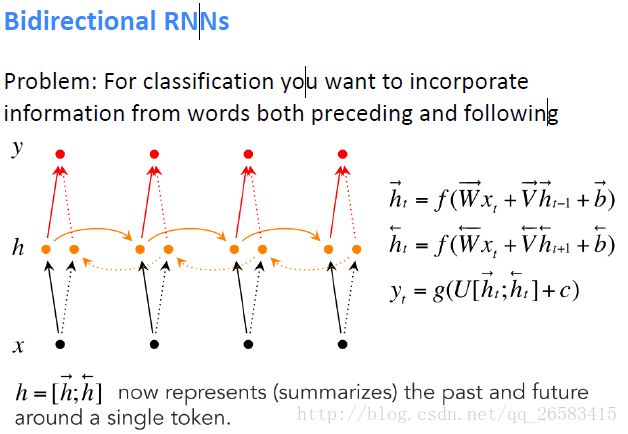
深度BIRNN:
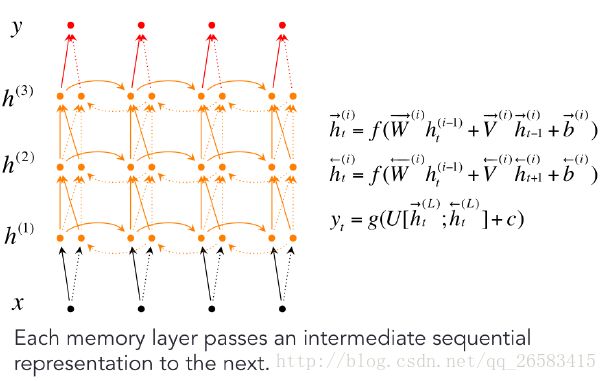

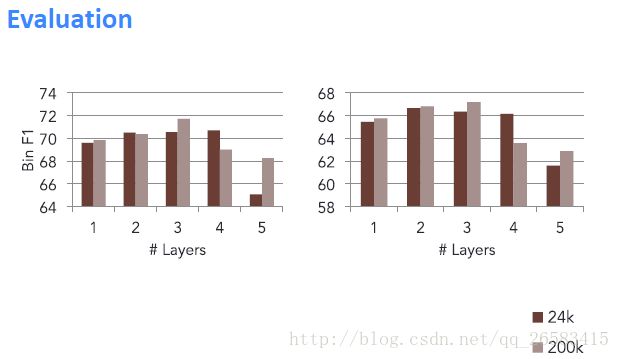
层数不是越多越好
总结:
1、循环神经网络是很好的深度NLP模型之一。
2、训练会出现梯度消失和爆炸问题。
3、RNN模型可以被用于很多方面,通过一些技巧提高性能。
4、下一次:介绍更强大的LSTM和GRU。
softmax问题:No Zero Shot Word Predictions
1、只有在训练过程中,以及在softmax的一部分中,才能预测出答案。
2、但是在积极的对话中学习新单词是很自然的,系统应该能够把它们接起来。
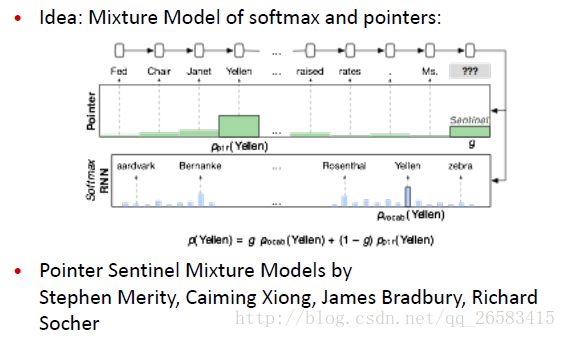
通过预测看不见的未来词来解决障碍(Tackling Obstacle by Predicting Unseen Words):
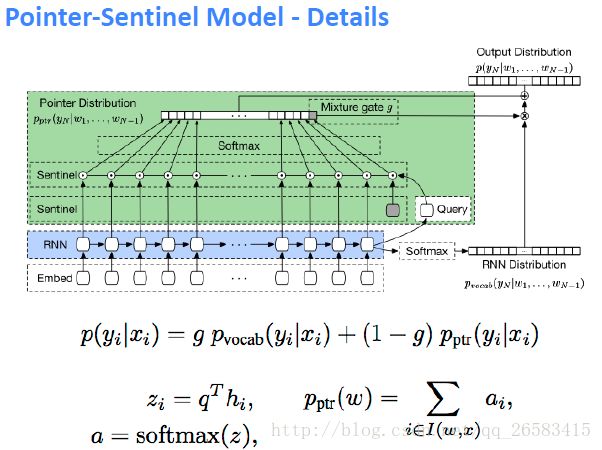
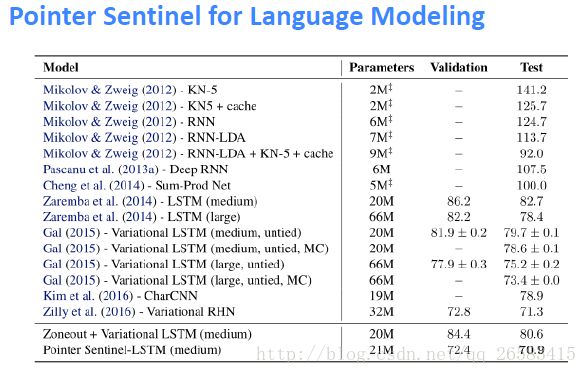
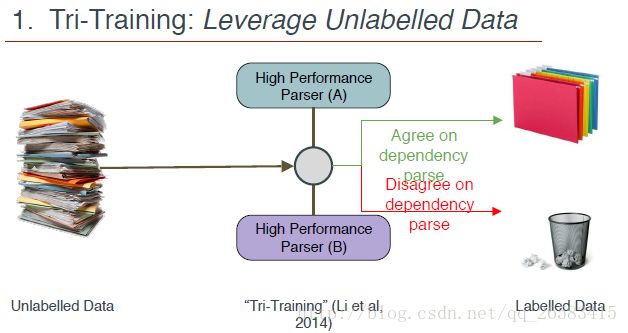
神经网络基于转换解析的结构化训练(Structured Training for Neural Network Transition-Based Parsing):




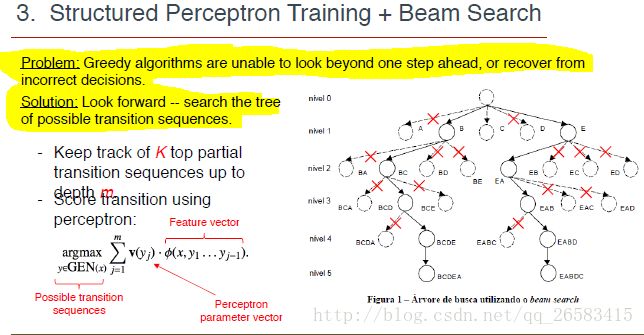
贪婪搜索:每个词进行,可能整体句子并不是最好的。
定向搜索:针对一小段句子序列进行搜索。

参考:
http://web.stanford.edu/class/cs224n/
http://www.hankcs.com/nlp/word-vector-representations-word2vec.html