HTTP & HTTPS详解
HTTP是应用层协议,用于客户端和服务端间的通信,来总结一下HTTP协议的具体内容以及细节。
HTTP协议的请求和响应体解析
首先看一下HTTP请求的一个例子,用whistle抓包,打开"https://baidu.com/",以下是得到的Request请求体:
请求体Request:
GET / HTTP/1.1 /** 表示当前是GET请求; / 表示URL路径,URL路径以/开头,后面没有带具体路径,即表示访问百度首页,若访问子页面,后面会带上具体的参数例如:/xx/xxx...;使用HTTP/1.1版本 **/
/** 下面是请求的头部 **/
Host: baidu.com //表示请求的域名,如果一个服务器有多个网站,那么就需要根据域名来区分访问的是哪个网站
Connection: keep-alive //表示需要保持连接,不要立刻断开
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36 //浏览器的ua,告知服务器当前请求数据的操作系统版本、CPU类型、浏览器版等等相关设备信息
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3 //告知服务器浏览器可以接收的数据类型
Accept-Encoding: gzip //编码类型
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 //语言
//cookie:服务器存储在浏览器的加密数据,服务器以cookie来辨别浏览器身份
Cookie: BAIDUID=3B41CACCAE992539BA484D0ED729C8F9:FG=1; BIDUPSID=3B41CACCAE992539BA484D0ED729C8F9; PSTM=1522674362; BDUSS=1uZ2pqcWxodGlBT0ZtRmwteXEzSmlTMkVVLXhSMUdUMzYwRTdTempYZWs0MXRiQVFBQUFBJCQAAAAAAAAAAAEAAABookUsy8nB1tTGuqMxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKRWNFukVjRbd2; H_PS_PSSID=1455_21086_28770_28720_28557_28697_28585_28638_26350_28518_28625_22157;....
服务端响应Response:
HTTP/1.1 200 OK // 服务器响应,分别是:HTTP版本 响应码,200表示请求成功,不同的响应码意义不一样 响应信息
Cache-Control: private //cache-control不同的取值,主要作用当重新浏览服务器时,如何去访问服务器
Connection: Keep-Alive //不要立刻断开连接
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Tue, 16 Apr 2019 11:53:58 GMT
Expires: Tue, 16 Apr 2019 11:53:58 GMT //指定缓存的实效日期
Server: BWS/1.1
...... //返回百度首页的html数据,由浏览器去解析并展示
关键字含义
keep-alive
由于http是应用层协议,http需要和服务端通信,首先先要建立TCP连接,之后才能进行通信,而这个建立连接是相对耗费资源的,浏览器又需要频繁的去访问服务器,如果每次请求完数据之后,服务器就主动断开连接,那么下一次访问,再建立连接,那么这个时间花费必然很大,尤其是一个页面中通常有多个请求,频繁的断开重练对于服务器和浏览器来说都是巨大的资源损耗。
所以可以通过设置keep-alive,让服务器等待一段时间,如果还是没有数据请求,才关闭连接,有的话可以复用tcp连接。HTTP/1.1之后默认开启Keep-Alive, 在HTTP的头域中增加Connection选项。当设置为Connection:keep-alive表示开启,设置为Connection:close表示关闭。
Cookie
cookie是服务器给浏览器返回的一小段文本文件,包含了浏览器的一些身份信息,浏览器将其存储起来,下次再访问服务器的时候携带该cookie,服务器根据这个cookie信息判断该用户是否是合法用户,或者是否需要重新登陆,服务器从cookie中读取信息,然后可以简化用户的登录手续等等,是服务器用来维护和客户端之间的会话状态的一个东西。
例如:
例如我访问了一次某购物网站,浏览了一些我喜欢的商品,可能该购物网站就会收集到我的一些喜好,然后以cookie的形式返回给我的浏览器,下次我再去访问该购物网站时,浏览器就会携带该cookie,然后该购物网站就可以根据我的喜好给我推荐一些我可能喜欢的商品,当然这个cookie也可以在浏览器中设置禁止使用。
更广泛的一种情况时,当我登录了一个网站,该网站会将我的用户名、密码等相关信息加密存储起来,然后以cookie的形式返回给我,下次浏览器再访问该网站时携带该cookie,网站将该cookie和数据库的进行对比,若通过,则不需要再输入用户名密码了,当然这样也可能造成用户信息泄漏,例如我在多个浏览器登录了某一个网站,但是没有清除cookie信息,那么就可能导致信息泄漏。
Session机制
Session不同于cookie,是保存在服务器的,客户端访问服务器的时候,服务器把客户端的信息以某种形式记录在服务器上,这就是session。客户端再次访问时只要从该session中查找该客户端的状态就可以了。
Cache-Control
从上面的例子可以看到,服务器的响应头会带有一个Cache-Control字段,顾名思义,就是用于缓存控制的,浏览器向服务器请求数据,服务器会告知浏览器这些数据是否可以缓存或者缓存的时间间隔,免得浏览器每次都向服务器请求新的数据,让它不堪重负,它有几个取值:
- private(默认值)
- no-cache
- max-age(单位为s)
- must-revalidate
每个取值和打开浏览器的方式有关:
| Cache-Control | 打开一个新的浏览器窗口 | 原窗口单击回车键 | 刷新 | 单击返回按钮 |
|---|---|---|---|---|
| private | 重新发送请求 | 第一次,浏览器重新发送请求,后面就显示缓存页面 | 重新发送请求 | 显示缓存页面 |
| no-cache | 重新发送请求 | 重新发送请求 | 重新发送请求 | 重新发送请求 |
| max-age | 在xxx秒后,重新发送请求 | 在xxx秒后,重新发送请求 | 重新发送请求 | 在xxx秒后,重新发送请求 |
| must-revalidate | 重新发送请求 | 第一次,浏览器重新发送请求,后面就显示缓存页面 | 重新发送请求 | 显示缓存页面 |
Expired
响应失效日期,当超过该日期,响应就认为是失效的,失效的响应不会被缓存。会被cache-control:max-age覆盖。
HTTP请求响应的步骤
-
浏览器地址栏输入访问地址,浏览器向DNS服务器请求解析该IP地址,并以该IP地址和80端口发起TCP连接;
-
TCP三次握手过程,并在最后一次握手时发送请求报文;
-
服务器接受到请求后,获取指定资源,将资源写入TCP流中,让浏览器读取;
-
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,不同服务器保持时间可能不一样,在该时间内可以继续接收请求;
-
浏览器获取到HTML超文本后,解析并显示在页面上
HTTP/1.0 和 HTTP/2.0 的区别
参考了解
Http2.0优势:
1.连接共享 keep-alive
2.header压缩
3.压缩算法
4.流量控制
5.更安全的SSL,禁用不安全的加密算法。
HTTPS
协议
可以理解为http + SSL/TLS,即HTTP下加入SSL层,作为安全基础层。
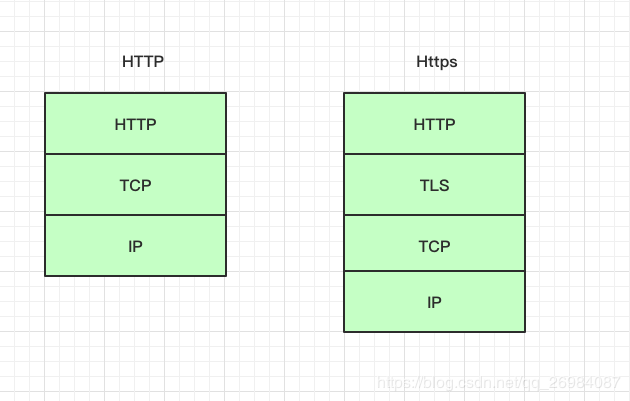
SSL:Secure Socket Layer,安全套接字层,为数据通信提供安全支持;
TLS:Transport Layer Security,传输层安全,前身是SSL。
学习HTTPS之前,先了解一下以下一些相关的加密算法以及证书、签名等相关内容。
加密算法
对称加密
加解密使用同一个密钥,例如:DES、AES
非对称加密
加解密使用不同的密钥,性能较低,但安全性强,能加密的数据长度有限,例如:RSA、DSA
非对称加密的过程:
-
甲方生成两个密钥,公钥和私钥,然后私钥自己保存,不会公开,将公钥发给已方(“这个发送过程就可能被别人截获,公钥也可能被黑客获取”)
-
已方收到公钥之后,然后将要发送给甲方的数据用公钥进行加密,再将加密后数据发给甲方
-
甲方收到了乙方的加密数据,用自己的私钥进行解密(“由于任何人都不知道甲方的私钥,所以乙方发送的数据即使被截获了,也无法解密,所以只要私钥不公开,那么这个通信就是安全的”)
因此,可见这里会遗留一个问题,发送公钥的过程可能被黑客获取,替换成自己的公钥,那么乙方加密的数据被黑客获取,就可以用黑客自己的私钥进行解密,这个问题会用到后面介绍的证书来解决。
哈希算法
将任意长度的信息转换成较短的固定长度的值,通常长度比信息小很多,而且算法不可逆,例如:MD5、SHA-1,SHA-2,SHA-256等。
数字证书
因为公钥在传输过程中可能被篡改,得到的是黑客公钥而不是服务器的公钥,注意这里,公钥是任何人都可以知道的,不用担心泄漏的问题,要担心的是被篡改的问题,所以这里要做的是如何防止公钥被篡改。数字证书就是解决这个问题的。所以出现了一些第三方的权威机构例如CA,当我们要发送公钥给另一方时,首先请求CA将自己的公钥进行加密,CA用自己的私钥对我们的公钥进行加密,然后返回给我们,这个就是带有CA的数字证书。
数字签名
CA除了对服务器的公钥进行加密外,另外需要将服务器以及自己的一些相关信息进行hash,然后用自己的私钥进行签名,得到数字签名。再将数字证书和签名返回给服务器,服务器用CA的公钥对证书进行解密,CA的公钥是公开的,只要被篡改了任何人都可以知道,若果能够解密,说明的确是CA返回的,然后再对报文进行hash,对比返回的数字签名,如果一致,说明内容没有被篡改。
数字证书其实就是用CA私钥加密后的服务器公钥,如果黑客截获了证书,用CA公钥解出来,并篡改,再用自己的私钥加密回去,接收方用CA公钥解密肯定就失败了,所以可以防止服务器公钥被篡改问题。
数字签名就是CA将自己和服务器的信息进行一轮哈希,并且进行加密,让接收方确保服务器的信息没有被篡改。
证书生成步骤:
-
服务器将自己的公钥和一些网站信息发给权威机构,例如CA,CA用自己的私钥进行签名生成数字证书,然后打包返回给服务器;
-
以后服务器发送信息给客户端时,就带上这个数字证书,客户端用CA的公钥对这个证书进行解密,得到服务器的公钥,如果不能解密出来,说明这个证书不是合法的;同时如果可以解密出来,再对所有信息进行hash,对比服务器的数字签名,可以知道信息是否有被篡改。
注意两个问题:
- 第一步中服务器将自己的公钥发给权威机构,其实不是通过网络传输的,而是各大权威机构将自己的公钥内置在各大操作系统或浏览器的出厂设置中,直接使用它就行了。所以这里不存在公钥被拦截篡改的问题。
- 如何知道CA返回的证书没有被篡改,返回的证书会附带证书的hash信息,服务器对返回信息进行一轮hash,对比是不是和发过来的hash一样就知道有没有改动过了,服务器发给客户端时同样也会用公钥加密自己的信息生成数字签名,让浏览器进行对比。
https诞生的原因
如果没有对数据进行加密传输,用的http,例如获取一张图片,“GET /pic/c3/c4/ruhua.jpg HTTP/1.1” 这些数据就会出现在网络上,容易被黑客劫持,从而返回意想不到的其他信息。所以用http可能会导致如下一些问题:
- 黑客窃听信息
- 黑客截获信息
- 黑客伪造信息
因此,https应运而生,解决http明文传输,导致信息被截获的问题,那么https是如何对信息进行加密的呢?https传输信息可以分为两个步骤,第一是https握手阶段,第二是加密数据通信阶段,首先来看看https的访问过程。
https的访问过程
https是应用层协议,浏览器要和服务器通信,首先要建立TCP连接,现在来看看过程概览图:
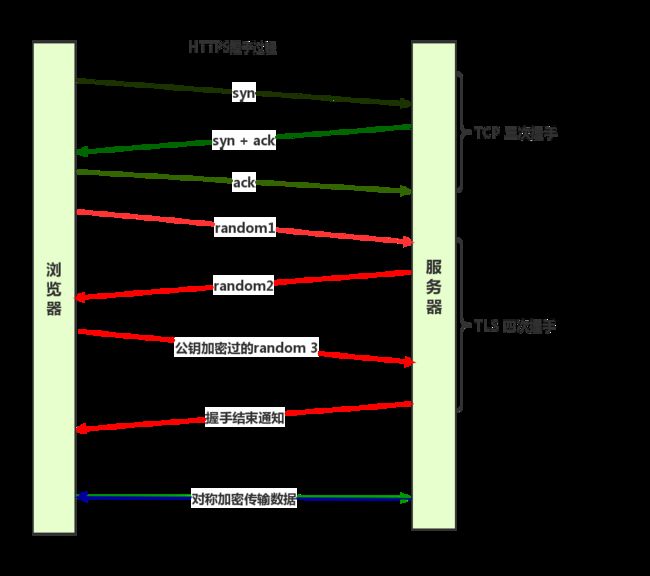
具体过程如下:
-
TCP三次握手
-
接下来是TLS四次握手,首先client向server发起请求,包含如下内容:
a. 支持的协议版本
b. 支持的加密压缩算法
c. 一个随机数random1,用于之后生成“对称密钥”
d. client hello文本信息 -
服务器响应
a. 根据客户端的协议版本和加密算法确定用哪种协议版本以及加密算法,如果浏览器版本和服务器不一致,服务器就关闭加密通信
b. 取出客户端的随机数并保存下来
c. 再产生一个服务器的随机数random2,用于之后生成“对称密钥”
d. 返回服务器证书
e. 返回server hello 文本信息
-
client 验收证书
a. 先验证证书合法性,验证域名是否是对应服务器的域名,如果合法,则用相应的CA公钥去解密证书,取出服务器的公钥,并且进行hash验证,确认无篡改。
b. 取出服务器的random2,再生成一个随机数random3,然后用上面证书中的公钥加密这个随机数random3生成preMaster key,发送给服务器
c. 同时通知服务器编码改变,表示之后的信息都用双方商定的加密方法和密钥发送
d. 客户端握手结束通知,表示客户端的握手阶段已经结束,这一项其实也是前面发送的所有内容的hash值,用作服务器校验
-
server获取preMaster key
a. server用自己的私钥解密这个preMaster key得到random3,此时客户端和服务器都持有3个随机数random1,random2,random3,双方均用这三个随机数以及约定好的加密算法来生成对称密钥,之后的数据传输 就用这个密钥来加解密
b. 服务器通知客户端编码通知,表示之后的信息都用双方商定的加密方法和密钥发送
c. 握手结束通知,表示服务器的握手阶段已经结束,这一项也是前面所有内容的hash值,用作客户端校验
-
client可以开始用约定好的加密算法以及密钥来加密数据,进行数据传输了。
注意:
用于生成对称加密密钥的随机数只有random3在传输过程是用服务器公钥加密的,而random1和random2是明文传输的,那么假设random1和random2被篡改了,那么在上面的第4步的第d项以及第5步的第c项中,验证hash的过程就会失败,从而让双方都知道有信息被篡改,从而中断连接或者重新发起连接。
总结
TLS握手所做工作其实就是生成三个随机数,用来生成对称密钥,这样就避免了对称密钥在网络上传输被截取的问题,不直接选择非对称密钥来加密传输数据是因为比较耗性能,所以用TLS握手来在各自端生成对称密钥,然后之后的数据用对称密钥来加解密。
SSL证书校验以及域名校验
https验证证书过程,如果用https去访问知名机构服务器,例如https://wikipedia,rog,如下:
URL url = new URL("https://wikipedia.org");
URLConnection conn = url.openConnection();
InputStream in = conn.getInputStream();
//接着从输入流里面读取内容
但是这个过程就是安全的,因为https会在建立连接握手时去验证Wikipedia的证书,这个CA证书是内置于Android系统的。但是如果我们的服务器没有携带知名机构的证书呢?例如我开发了一个服务器,但是没有向CA去申请证书,因为要钱,那我可以自己定义一个证书,并且内置在客户端,在进行https握手时检验服务器的证书是否和客户端本地的证书一致。
证书SSL验证不通过
如果不安全,则会抛出“javax.net.ssl.SSLHandshakeException:java.security.cert.CertPathValidatorException:Trust anchor for certication path not found."
出现上述问题的情况有如下几种:
- 颁发服务器证书的机构未知
- 服务器证书不是由CA签署的,而是自签署
- 服务器配置缺少中间CA
未知的证书颁发机构
例如证书是Android还没有信任的新CA证书,因为Android系统会内置证书,可能该证书Android还没有信任;或者app在比较旧的版本上运行,系统还没有更新证书;另外一个原因是该证书不是公共CA,而是政府、公司或者教育机构发放的仅供自己私有使用的CA。就会抛出上述异常,但是如果还是想要信任该证书,那么可以让HttpsURLConnection去信任,实现方法如下:
从 InputStream 获取一个特定的 CA,用该 CA 创建 KeyStore,然后用后者创建和初始化 TrustManager。TrustManager 是系统用于从服务器验证证书的工具,可以使用一个或多个 CA 从 KeyStore 创建,而创建的 TrustManager 将仅信任这些 CA。如果是新的 TrustManager,此示例将初始化一个新的 SSLContext,后者可以提供一个 SSLSocketFactory,您可以通过 HttpsURLConnection 用它来替换默认的 SSLSocketFactory。这样一来,连接将使用您的 CA 验证证书。
其实就是借助一个知道自己CA的TrustManager,系统就能够沿着服务器证书是否是来自信任的颁发者。
示例:
// Load CAs from an InputStream
// (could be from a resource or ByteArrayInputStream or ...)
CertificateFactory cf = CertificateFactory.getInstance("X.509");
// From https://www.washington.edu/itconnect/security/ca/load-der.crt
InputStream caInput = new BufferedInputStream(new FileInputStream("load-der.crt"));
Certificate ca;
try {
ca = cf.generateCertificate(caInput);
System.out.println("ca=" + ((X509Certificate) ca).getSubjectDN());
} finally {
caInput.close();
}
// Create a KeyStore containing our trusted CAs
String keyStoreType = KeyStore.getDefaultType();
KeyStore keyStore = KeyStore.getInstance(keyStoreType);
keyStore.load(null, null);
keyStore.setCertificateEntry("ca", ca);
// Create a TrustManager that trusts the CAs in our KeyStore
String tmfAlgorithm = TrustManagerFactory.getDefaultAlgorithm();
TrustManagerFactory tmf = TrustManagerFactory.getInstance(tmfAlgorithm);
tmf.init(keyStore);
// Create an SSLContext that uses our TrustManager
SSLContext context = SSLContext.getInstance("TLS");
context.init(null, tmf.getTrustManagers(), null);
// Tell the URLConnection to use a SocketFactory from our SSLContext
URL url = new URL("https://certs.cac.washington.edu/CAtest/");
HttpsURLConnection urlConnection =
(HttpsURLConnection)url.openConnection();
urlConnection.setSSLSocketFactory(context.getSocketFactory());
InputStream in = urlConnection.getInputStream();
copyInputStreamToOutputStream(in, System.out);
自签署的服务器证书
导致出现 SSLHandshakeException 的第二种情况是自签署证书,表示服务器将按照自己的 CA 进行操作。这与证书颁发机构未知的情况相似,因此,您可以使用前面部分介绍的方法。
可以创建自己的 TrustManager,这样可以直接信任服务器证书。这种方法具有前面所述的将应用与证书直接关联的所有弊端,但可以安全地操作。不过要确保自签署证书具有合理的强密钥。从 2012 年开始,可以接受一个指数为 65537 的 2048 位 RSA 签名,此签名的有效期为一年。旋转密钥时,查看颁发机构(例如 NIST)针对可接受的密钥提供的建议。
缺少中间证书颁发机构
大多数公共CA不直接签署服务器证书,而是通过使用自己的CA证书(根证书)去签署中间CA,这样,根CA就可以离线存储,降低泄漏风险。但是,Android是仅信任根CA的,所以如果服务器发来一个中间机构签署的证书,那么不会被android信任,因此,服务器在SSL握手时不仅会向客户端发送自己的证书,还会发送一个证书链,包括服务器CA以及到达可信的根CA所需要的任意中间证书。
可通过openssl去查看证书链:
openssl s_client -connect mail.google.com:443
主机名验证
示例:
HostnameVerifier hostnameVerifier = new HostnameVerifier() {
@Override
public boolean verify(String hostname, SSLSession session) {
HostnameVerifier hv =
HttpsURLConnection.getDefaultHostnameVerifier();
return hv.verify("example.com", session);
}
};
// Tell the URLConnection to use our HostnameVerifier
URL url = new URL("https://example.org/");
HttpsURLConnection urlConnection =
(HttpsURLConnection)url.openConnection();
urlConnection.setHostnameVerifier(hostnameVerifier);
InputStream in = urlConnection.getInputStream();
copyInputStreamToOutputStream(in, System.out);
官方文档
问题:A向哔哩哔哩请求数据,但是优酷劫持了,如何判断这个证书是哔哩哔哩的而不是优酷的?
从https验证证书过程就可以解释:
-
首先验证域名,如果被豆瓣劫持了,那么返回的证书域名是豆瓣的,而不是知乎的,那么很明显就可以被浏览器感知;
-
如果豆瓣劫持了证书,用CA公钥解出来,替换成自己的公钥,再用CA公钥解出数字签名,用自己的相关信息进行一轮哈希,但是由于没有CA的私钥,所以它无法再进行一轮加密,即使它把所有信息都成功替换了,但是到时候浏览器会用CA的公钥进行解密,发现无法解密,说明被篡改了;
-
假设第二步,豆瓣只是修改了证书中的公钥,没有修改数字签名,那么浏览器拿到证书中的公钥,再进行一轮哈希,然后用CA公钥解出数字签名一对你,发现不一样,说明被篡改了。
上面这个步骤其实就是在https握手,服务器向浏览器返回证书的这个阶段。