H264中的sps pps
iOS仿微信小视频功能开发优化记录
【如何快速的开发一个完整的iOS直播app】(原理篇)
iOS动手做一个直播(原理篇)
iOS RTMP 视频直播开发笔记(3)- 了解 H.264 编码
视频方向问题处理
http://stackoverflow.com/questions/26932794/square-cropping-and-fixing-the-video-orientation-in-ios
https://github.com/rs/SDAVAssetExportSession
">"
- "-" + "空格"xulie
- 1 dfsf
高亮语法为"高亮"
[添加超链接](http://jianshu.io)
 == 插入图片
音频录制#
背景知识###
录音功能生成的目标音频格式是PCM格式,对于PCM的定义,维基百科上是这么写到的:"Pulse-code modulation (PCM) is a method used to digitally represent sampled analog signals. It is the standard form of digital audio in computers, Compact Discs, digital telephony and other digital audio applications. In a PCM stream, the amplitude of the analog signal is sampled regularly at uniform intervals, and each sample is quantized to the nearest value within a range of digital steps.",大致意思是PCM是用来采样模拟信号的一种方法,是现在数字音频应用中数字音频的标准格式,而PCM采样的原理,是均匀间隔的将模拟信号的振幅量化成指定数据范围内最贴近的数值。
PCM文件存储的数据是不经压缩的纯音频数据,当然只是这么说可能有些抽象,我们拉上大家熟知的MP3文件进行对比,MP3文件存储的是压缩后的音频,PCM与MP3两者之间的关系简单说就是:PCM文件经过MP3压缩算法处理后生成的文件就是MP3文件。我们简单比较一下双方存储所消耗的空间,1分钟的每采样点16位的双声道的44.1kHz采样率PCM文件大小为:16016/8244100/1024=10335.9375KB,约为10MB,而对应的128kps的MP3文件大小仅为1MB左右,既然PCM文件占用存储空间这么大,我们是不是应该放弃使用PCM格式存储录音,恰恰相反,注意第一句话:"PCM文件存储的数据是不经压缩的纯音频数据",这意味只有PCM格式的音频数据是可以用来直接进行声音处理,例如进行音量调节,声音滤镜等操作,相对的其他的音频编码格式都是必须解码后才能进行处理(PCM编码的WAV文件也得先读取文件头),当然这不代表PCM文件就好用,因为没有文件头,所以进行处理或者播放之前我们必须事先知道PCM文件的声道数,采样点字节数,采样率,编码大小端,这在大多数情况下都是不可能的,事实上就我所知没有播放器是直接支持PCM文件的播放。不过现在录音的各项系数都是我们定义的,所以我们就不用担心这个问题
源自:详解如何使用代码进行音频合成
MP3格式中的码率(BitRate)代表了MP3数据的压缩质量,现在常用的码率有128kbit/s、160kbit/s、320kbit/s等等,这个值越高声音质量也就越高。MP3编码方式常用的有两种固定码率(Constant bitrate,CBR)和可变码率(Variable bitrate,VBR)。
MP3格式中的数据通常由两部分组成,一部分为ID3用来存储歌名、演唱者、专辑、音轨数等信息,另一部分为音频数据。音频数据部分以帧(frame)为单位存储,每个音频都有自己的帧头,如图所示就是一个MP3文件帧结构图(图片同样来自互联网)。MP3中的每一个帧都有自己的帧头,其中存储了采样率等解码必须的信息,所以每一个帧都可以独立于文件存在和播放,这个特性加上高压缩比使得MP3文件成为了音频流播放的主流格式。帧头之后存储着音频数据,这些音频数据是若干个PCM数据帧经过压缩算法压缩得到的,对CBR的MP3数据来说每个帧中包含的PCM数据帧是固定的,而VBR是可变的。

AAC简介###
采样率Sample Rate指单位时间内对媒体对象的采样次数,单位Hz(这句话好像和原来不太一样,郁闷)。
帧率(Frame per second,fps),单位时间内媒体帧的个数。
这两个概念都描述了媒体的“连续”性,二者的区别在于一个Frame可能包含多个Sample。一般每个视频帧中只包含一个视频采样,而音频帧中会包含多个音频采样。如1个AAC帧中包含1024个采样。所以,帧率常用在视频方面,采样率常用于音频方面。采样率(帧率)越高,媒体越流畅,当然人的感受就越过瘾。但是,由于人的视/听器官分辨能力的局限,往往这些数值达到末各程度就可以满足人对“连续”性的需求了。比如,对采样率高于44.1kHz的声音,人很难听出区别了。对帧率高于30的视频,人很难看出帧率的区别。
比特率(bps或kbps),与前面两个概念不同,它描述了单位时间长度的媒体内容需要空间。当然该值越高,每个采样的信息量就越大,对这个采样的描述就越精确。
对于人的感受来说,当然上述数值越大越好,但是这总是会受到网络带宽和处理设备能力的限制。所以,媒体工程师会取一个折中的数值来制作媒体内容,在符合能力的范围内,提供最佳的体验。
例子:一张CD,双声道,采样率44.1kHz每个采样13bit,时长74分钟(4440秒),则CD的容量为13244100*4440约等于640MB
在AAC媒体文件中,以Sampling Frequency Index的方式记录AAC的采样率,下面的数组为对应表:AAC_Sampling_Frequency_Table[16] = {96000, 88200, 64000, 48000, 44100, 32000, 24000, 22050, 16000, 12000, 11025, 8000, 7350, 0, 0, 0}
AAC媒体文件的时长难为了我不少时间,现在终于明白了如何计算。
首先要明确一点,AAC的每帧采样个数为1024,即每个AAC帧中包含1024个采样。
这样Frame_duration(s/f)=1024(Sample/f)/Sampling_Rate(Sample/s),File_duration(s)=Frame_duration(s/f)*Frame_count(f)。
例子,某个AAC媒体,采样率16000Hz,938帧,时长=(1024/16000)*938约为60秒。
AAC-Advanced Audio Coding高级音频编码,目前渐成主流的音频编码,是有损音频压缩格式。已被MPEG4标准的文件容器格式采用,估计MP3后的音频霸主就是它了。
AAC帧首部7个字节:
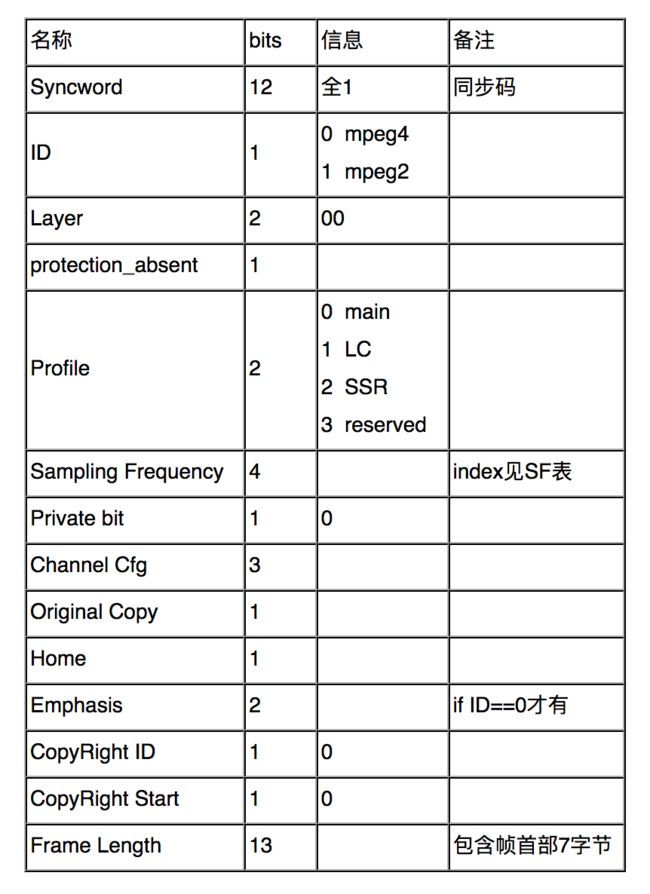
AAC与MPEG4封装AAC媒体帧的方式存在相当的区别,尽管记录的信息相似。
在AAC文件中,帧播放的配置信息存储于帧首部(7-8个字节,ID=0时为7,否则为8)。而在MPEG4中,由于他采用box的一对象的方式封装媒体,故其AAC音频播放信息也被封装于box中。仅使用2个字节。AAC帧首部参看过去的文章,AAC decoder config layout如下:
@struct AudioStreamBasicDescription
@abstract This structure encapsulates all the information for describing the basic
format properties of a stream of audio data.(这个结构体将所有描述基本格式属性的音频数据流信息装入内部)
@discussion This structure is sufficient to describe any constant bit rate format that has
channels that are the same size.(这种结构能充分描述任何恒定比特率格式,那些有声轨,大小一样) Extensions are required for variable bit rate
data and for constant bit rate data where the channels have unequal sizes.(在那些音轨大小不相等的地方,可变比特率和恒定比特率的扩展是被需要的)
However, where applicable, the appropriate fields will be filled out correctly
for these kinds of formats (the extra data is provided via separate properties).(然而,在适用情况下,适当的字段将被以这些格式正确填写)
In all fields, a value of 0 indicates that the field is either unknown, not
applicable or otherwise is inapproprate for the format and should be ignored.
Note that 0 is still a valid value for most formats in the mFormatFlags field.
In audio data a frame is one sample across all channels. In non-interleaved
audio, the per frame fields identify one channel. In interleaved audio, the per
frame fields identify the set of n channels. In uncompressed audio, a Packet is
one frame, (mFramesPerPacket == 1). In compressed audio, a Packet is an
indivisible chunk of compressed data, for example an AAC packet will contain
1024 sample frames.
@field mSampleRate
The number of sample frames per second of the data in the stream.(每秒对原始数据的取样数,即采样率单位Hz)
@field mFormatID
The AudioFormatID indicating the general kind of data in the stream.(表明数据类型)
@field mFormatFlags
The AudioFormatFlags for the format indicated by mFormatID.(AudioFormatFlags的格式被mFormatID定义)
@field mBytesPerPacket
The number of bytes in a packet of data.(一个数据包多少字节)
@field mFramesPerPacket
The number of sample frames in each packet of data.(每个数据包里多少个取样帧)
@field mBytesPerFrame
The number of bytes in a single sample frame of data.(一个取样帧有多少字节)
@field mChannelsPerFrame
The number of channels in each frame of data.(每一帧的声道数,1为单声道)
@field mBitsPerChannel
The number of bits of sample data for each channel in a frame of data.(一帧数据的一个声道采样数据的位数8为,16位或32位)
@field mReserved
Pads the structure out to force an even 8 byte alignment.(猜测:不满8为补足八位)
- 对于音频数据的所有声道来说一帧(frame)就是一次采样数据(sample)。在非交错封包模式的音频数据中,一个声道的音频数据存在在一个平面内,在交错封包模式中,以立体声为例就是声道1、声道2、声道1、声道2,循环。在未压缩的音频数据中,一个数据包(packet)就是一帧(frame)。在压缩过的音频数据中,一个数据包(packet)是不可分割的一块压缩数据,比如一个AAC(一种音频压缩格式)数据包将会包含有1024分采样帧。
struct AudioStreamBasicDescription
{
Float64 mSampleRate;
AudioFormatID mFormatID;
AudioFormatFlags mFormatFlags;
UInt32 mBytesPerPacket;
UInt32 mFramesPerPacket;
UInt32 mBytesPerFrame;
UInt32 mChannelsPerFrame;
UInt32 mBitsPerChannel;
UInt32 mReserved;
};
//视频格式对于linear PCM,仅支持interleaved格式;支持压缩格式
const AudioStreamBasicDescription *inFormat,
//视频队列的一块缓冲区填满的回调函数
AudioQueueInputCallback inCallbackProc,
//A value or pointer to data that you specify to be passed to the callback function.
void * __nullable inUserData,
CFRunLoopRef __nullable inCallbackRunLoop,
CFStringRef __nullable inCallbackRunLoopMode,
UInt32 inFlags,
AudioQueueRef __nullable * __nonnull outAQ)
定义一个回调函数的指针,当录制音频的队列填满一个视频缓冲区时会被调用
typedef void (*AudioQueueInputCallback)(
void * __nullable inUserData,
AudioQueueRef inAQ,
AudioQueueBufferRef inBuffer,
const AudioTimeStamp * inStartTime,
UInt32 inNumberPacketDescriptions,
const AudioStreamPacketDescription * __nullable inPacketDescs);
inUserData:
inStartTime:指向音频时间戳结构体的一个指针,之歌时间戳对应着缓冲区第一个样本
inNumberPacketDescriptions:提供给回调函数的数据内包含的packet数
inPacketDescs:packet descriptions
片、场、帧、片的概念###
H264结构中,一个视频图像编码后的数据叫做一帧,一帧由一个片(slice)或多个片组成,一个片由一个或多个宏块(MB)组成,一个宏块由16×16的yuv数据组成。宏块作为H264编码的基本单位。
1帧 = n个片
1片 = n个宏块
1宏块 = 16x16yuv数据
场和帧:视频的一场或一帧可用来产生一个编码图像。在电视中,为减少大面积闪烁现象,把一帧分成两个隔行的场。
宏块:一个编码图像通常划分成若干宏块组成,一个宏块由一个16×16亮度像素和附加的一个8×8 Cb和一个8×8 Cr彩色像素块组成。
片:每个图象中,若干宏块被排列成片的形式。片分为I片、B片、P片和其他一些片。
- I片只包含I宏块,P片可包含P和I宏块,而B片可包含B和I宏块。
- I宏块利用从当前片中已解码的像素作为参考进行帧内预测。
- P宏块利用前面已编码图象作为参考图象进行帧内预测。
- B宏块则利用双向的参考图象(前一帧和后一帧)进行帧内预测。
详情参考:iOS RTMP 视频直播开发笔记(3)- 了解 H.264 编码