强化学习论文(3): One-Shot Hierarchical Imitation Learning of Compound Visuomotor Tasks
元学习(meta learning)框架下的分层模仿学习问题,这里主要关注层级策略方法,对于机器人视觉任务的细节不做深究。
关于meta learning 这里有一个不错的快速介绍:
Meta-learning(元学习)和 3D-CNN 总结
摘要
这篇文章考虑的是机器人根据人类的演示video和其他目标子任务的示例,完成多步骤视觉任务的问题。这个问题面临着一系列挑战:首先,人类的演示video没有直接的监督信息;其次,直接从图像学习需要包含大量参数的近似网络;最后,复合任务需要大量的示例数据。
这篇文章提出方法,一方面从子任务示例中学习单一行为,一方面学习如何组合这些行为去完成多步骤任务。
引言
本文考虑的问题是:能否利用符合任务内在的组合结构,学习较长时域的任务?
关键点:利用 meta-learning,首先从子任务示例中学习单一行为(图左),然后学习如何组合这些行为去完成多步骤任务(图右)

为了能够在观看视频的同时调整策略,我们建立了模型能够识别当前元动作的进度(相位),元动作的相位可以直接从元动作的样例视频中学习,使用帧的索引作为label即可,无需人工标注。我们使用了域自适应的元模仿学习来学习模仿元动作。
如下图所示,我们的方法首先使用相位预测器把测试视频分解为元动作片段,然后为每一个元动作生成一系列策略,并依次执行策略直到相位预测器判断动作结束。

这篇论文的主要贡献是自动地动态学习和组合序列策略,通过自动分解和组合技术实现这一目标。
meta-learning 方法
meta-learning方法主要用于学习元动作。这一部分介绍一下meta-learning及相关方法。
meta-learning的基本目标是使用少量的数据来学习新任务。为达成这个目标,meta-learning首先要学习很多meta-training任务,当面临一个新的meta-test任务时,就可以高效学习。meta-learning遵循假设:meta-training和meta-test任务都是从相同的分布 p ( τ ) p(\tau) p(τ)中采样而来的,因此任务中存在公共的结构,对这些结构的学习可以得到对新任务的快速学习。因此,meta-learning对应于结构学习。
MAML
MAML致力于通过学习神经网络的参数来学习任务间的共享结构,使其面对新任务时,只需少量几步的梯度下降就可以得到对新任务的良好泛化。
用 θ \theta θ表示初始模型参数, L ( θ , D ) L(\theta,D) L(θ,D)表示一个监督学习器的loss,其中 D τ D_\tau Dτ表示任务 τ \tau τ的标记数据。在meta-learning的过程中,MAML采样一个任务 τ \tau τ,从 D τ D_\tau Dτ采样数据点,随机划分为 D τ t r D_\tau^{tr} Dτtr和 D τ v a l D_\tau^{val} Dτval。假设 D τ t r D_\tau^{tr} Dτtr中有K个数据点。MAML优化模型参数 θ \theta θ使得少数几步 D τ t r D_\tau^{tr} Dτtr上的梯度下降就可以产生 D τ v a l D_\tau^{val} Dτval上的良好表现。优化目标为:
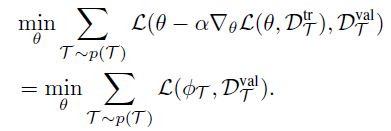
在meta-test时,从 τ t e s t \tau_{test} τtest中采样K个样本,运行梯度下降:
![]()
DAML
DAML将MAML应用到域自适应 one-shot 模仿学习中。DAML致力于从遥控示例中学习,最后能轻松完成对人类视频的学习。它把人类完成任务的视频转化为一个可执行的策略。不同于监督meta-learning,人类视频是一种弱监督,没有直接的label。优化目标为:
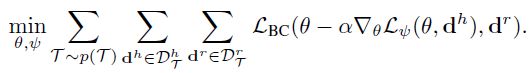
其中 d h d^h dh和 d l d^l dl分别是人类和机器人的演示视频。 L ψ L_\psi Lψ表示一个可学的critic用以评判在 L ψ L_\psi Lψ上运行梯度下降可以得到良好的适应,于是不同的任务有不同的目标集, L B C L_{BC} LBC表示两者之间的行为克隆loss。
模型
我们的目标是让机器人在观看一个人类执行任务的演示视频后,学习去执行一系列多步骤任务。在此之前,机器人需要先验知识或者经验,通过其他目标子任务的示例数据学习。经过meta-training之后,在meta-test阶段,机器人被提供给一个人类演示多步骤任务就的视频,机器人要在新的目标设定下学着去执行相同的多步骤任务。
问题设定
在meta-training阶段,对于每一元动作 P k P_k Pk,提供一组人类演示 { d i h } k \{d^h_i\}_k {dih}k和一组机器人演示 { d j r } k \{d^r_j\}_k {djr}k,其中一个人类演示 d k h d_k^h dkh是一个图像序列 o 1 h , ⋯ , o T i h o_1^h,\cdots,o_{T_i}^h o1h,⋯,oTih,一个机器人演示 d k r d^r_k dkr是一个图像动作序列 o 1 r , a 1 r , ⋯ , o T j r , a T j r o^r_1,a_1^r,\cdots,o^r_{T_j},a^r_{T_j} o1r,a1r,⋯,oTjr,aTjr。
在meta-test阶段,提供一个人类演示 d h d^h dh包含一个元动作序列,机器人首先识别出这些元动作,然后为每一个元动作生成策略,最后在把这些策略组合起来实现多步骤任务。
然而,在meta-training过程中,并没有包含如何组合元动作的信息,因此,本文训练了两个模型用来识别时间进度,即相位,可以实现元动作的划分和组合。
元动作组合
在meta-training阶段,我们训练一个人类相位预测器 ϕ h \phi_h ϕh和一个机器人相位预测器 ϕ r \phi_r ϕr,一个DAML one-shot agent π θ \pi_\theta πθ,用来从人类元动作演示 d i h d^h_i dih中生成机器人策略 π ϕ i \pi_{\phi_i} πϕi。在meta-test阶段,提供一个人类完成多步骤任务的演示 o 1 h , ⋯ , o T h o^h_1,\cdots,o^h_T o1h,⋯,oTh。
我们首先需要把这个演示分解成单个的元动作,把这个演示逐帧输入到 ϕ h \phi_h ϕh中,当 ϕ h ( o 1 : t h ) > 1 − ϵ \phi_h(o^h_{1:t})>1-\epsilon ϕh(o1:th)>1−ϵ时,表示当前元动作结束, d h = o 1 h , ⋯ , o t h d^h=o^h_1,\cdots,o^h_t dh=o1h,⋯,oth。然后,从 t + 1 t+1 t+1开始,重复上述步骤,最终得到一个元动作序列 d 1 h , d 2 h , ⋯ d^h_1,d^h_2,\cdots d1h,d2h,⋯,然后使用 π θ \pi_\theta πθ将其转换为 π ϕ 1 , π ϕ 2 , ⋯ \pi_{\phi_1},\pi_{\phi_2},\cdots πϕ1,πϕ2,⋯。在组合阶段,我们依次执行上述策略,把每一步执行后得到的图像 o t r o^r_t otr输入 ϕ r \phi_r ϕr,当 ϕ r ( o 1 : t r ) > 1 − ϵ \phi_r(o^r_{1:t})>1-\epsilon ϕr(o1:tr)>1−ϵ时,推进到下一个策略。
元相位预测器
为了将一个复合任务视频划分成元动作,以往的工作都需要多步骤任务视频的训练数据和相应的标签来指示元动作的进度。我们的方法中不需要这样的数据,大大减少了人工收集和标注工作。但是我们仍然需要:(1)划分复合任务的人类演示视频;(2)决定策略的转移。我们使用了一个简单方法来处理这些问题:预测元动作的相位。
上面提到,我们建立了一个人类相位预测器 ϕ h \phi_h ϕh和一个机器人相位预测器 ϕ r \phi_r ϕr。为了建立训练中的监督标签,我们对元动作示例视频 d d d的一部分 o 1 : t o_{1:t} o1:t,使用 t ∣ d ∣ \frac{t}{|d|} ∣d∣t作为其标签,来指示元动作完成了几分之几。使用RNN来处理变长序列,使用均方误差目标 ∑ i ∑ t = 1 T i ∣ ∣ ϕ ( d i , 1 : t ) − t ∣ d i ∣ ∣ ∣ \sum_i\sum_{t=1}^{T_i}||\phi(d_{i,1:t})-\frac{t}{|d_i|}|| ∑i∑t=1Ti∣∣ϕ(di,1:t)−∣di∣t∣∣来进行回归近似。
算法
