Tensorflow 解决 overfitting
Overfitting 也被称为过度学习,过度拟合。 它是机器学习中常见的问题
举个Classification(分类)的例子。看下图
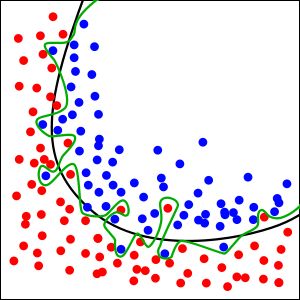
图中黑色曲线是正常模型,绿色曲线就是overfitting模型。尽管绿色曲线很精确的区分了所有的训练数据,但是并没有描述数据的整体特征,对新测试数据的适应性较差
看下图

TensorFlow提供了强大的dropout方法来解决overfitting问题
看下图例子,在这个tensorboard图中还没有加上dropout
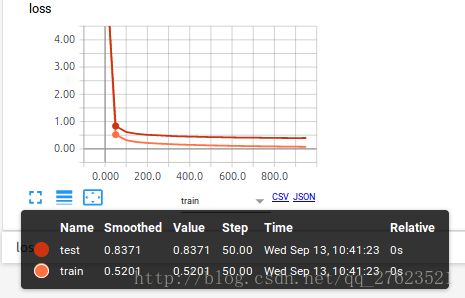
就可以暴露出overfitting问题,test 曲线和train曲线的差距还是比较大的
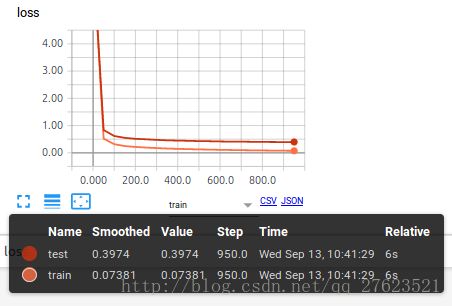
这个时间我们加上dropout试试效果。
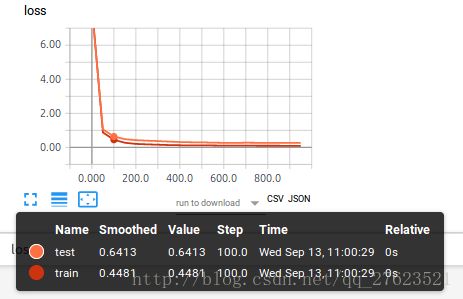
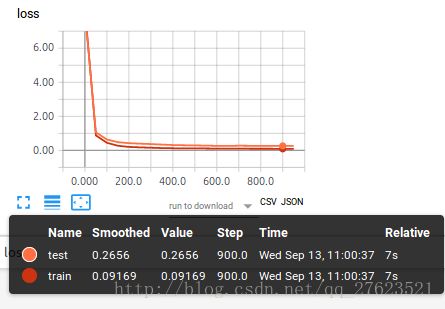
从上面两张图看,两条数据的差距变小了很多,可以说,使用dropout有效的解决了overfitting的问题,那么这是怎么实现的呢。下面展示关键代码就好了 因为使用的主题代码还是之前篇博客的主要代码。
这次使用的数据是sklearn 数据库当中的数据。所以,首先导入模块
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
准备数据
digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=.3)
添加保留率变量
keep_prob = tf.placeholder(tf.float32)#保留概率,即我们要保留的结果所占比例
keep_prob作为一个placeholder,在run时传入, 当keep_prob=1的时候,相当于100%保留,也就是dropout没有起作用。
在层里进行dropout
Wx_plus_b = tf.matmul(inputs, Weights) + biases
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
run时传入
for step in range(1000):
sess.run(train_step, feed_dict={xs: X_train, ys: Y_train,keep_prob: 0.5})
if step%50 == 0:
#记录损失
train_result = sess.run(merged,feed_dict = {xs:X_train,ys: Y_train,keep_prob: 1})
test_result = sess.run(merged,feed_dict ={xs:X_test,ys :Y_test,keep_prob: 1})
记录时就要全部保存,就不用在进行的dropout了
可视化
这次主要可视化loss的变化 在add_layer中就可视化一下结果就好了
tf.summary.histogram(layer_name+"/outputs",outputs)
接着给loss添加啊
#计算损失
loss = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),reduction_indices=[1]))#二者差的平方求和再取平均
#tensorboard
tf.summary.scalar("loss",loss)
添加两条对比线
merged = tf.summary.merge_all()
#两条线对比
train_writer = tf.summary.FileWriter("logs/train",sess.graph)
test_writer = tf.summary.FileWriter("logs/test",sess.graph)
然后将训练的结果添写入文件
train_writer.add_summary(train_result,step)
test_writer.add_summary(test_result, step)
做完这些就差不多了,可以运行后在进行可视化观看,大致图像就是上面的图片了。