BPR:个性化排名推荐系统
BPR 推荐模型基于贝叶斯理论在先验知识下极大化后验概率,实现从一个用户-项目矩阵训练出多个矩阵,且一个矩阵表示一个用户的项目偏好情况来获得用户多个项目的偏序关系下来进行排名的推荐系统。
目前比较主流的推荐系统模型
k近邻的协同过滤:传统的相似矩阵的计算会根据启发式的计算方法,比如皮尔逊相关系数,但是近些年研究,相似矩阵作为模型参数并且根据大量数据训练得出。矩阵分解:矩阵分解在显式反馈和隐式反馈中都是推荐系统中很热门的方法。在近些年研究中,奇异值分解(svd)作为获得特征矩阵的重要方法。但是svd分解存在模型过拟合的问题,正则项的提出解决了模型过拟合的问题。潜在语义模型也在推荐系统中得到应用,Schemdit-Thieme提出把推荐看作是多分类问题,用一些二元分类器来解决。

BPR 推荐模型的特点
*基于item-item推导出个性化i偏好排名。相对于一般的ranking,BPR强调个性化推荐。
*推导用于评估个性化推荐ranking的优化条件即后验概率,并用Roc曲线来类比证实BPR-OPT的可行性。
*为极大化BPR-OPT,提出了BPR-OPT的学习算法。基于随机梯度下降的learnBPR。
*一般的推荐算法是强调用户对项目的打分,只存在用户和单个项目的关系,不去考虑两个项目对用户的影响力。而BPR则从u,i,j出发来求解u,i的大小。
BPR 推荐模型
一般的ranking 可能通过对item进行打分高低来排名用户对item的喜欢程度,但是BPR不同,BPR对每一个u都重建一个>u的偏序关系。一般情况下,我们可以获得从大量的数据中制作一个下面这样的矩阵来作为训练集Ds,训练的数据集为三元组即[u,i,j]。
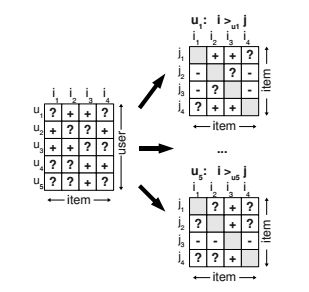
?表示的是用户无签到数据(比如用户和商品,这里的签到可以广义的理解为没有发生浏览行为或者是购买行为),有两种情况,第一种是可能本身就是negative value,也就是说用户对item是不感兴趣的。第二种情况则是缺失值,可能发生了浏览或者是购买行为但是却丢失了,当我们在上图中从左图转换为右图时,遇到0值时并不能确定究竟是上面所描述的哪一种情况。
+表示u相对于项目j更倾向于项目i,-表示u相对于周围
BPR推荐系统会考虑positive value 和negative value,也就说所有item都会被个性化ranking,即使用户对某个item缺失值这个item也能够被ranking,而不是仅仅用negative value代替缺失值。
策略:
*用户u对i是positive value,对j是negative value,那么就有
![]() 说明用户相对于项目j更喜欢项目i
说明用户相对于项目j更喜欢项目i
*用户u对i是negative value,对j是negative value,那么是无法评估用户更喜欢项目i还是项目j的。
*用户u对i是positive value,对j是positive value,那么也是无法判断用户更喜欢项目i还是项目j的。
数据假设:
同一用户对不同项目的偏序关系是相互独立的;
不同用户之间的偏好行为是相互独立的;
BPR-OPT推导
![]()
theta 为(用户潜在特征举证P,项目潜在特征矩阵Q)
![]() 为用户u的偏序关系,即I-I矩阵
为用户u的偏序关系,即I-I矩阵
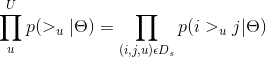
![]()
说明:
1![]()
2 ![]() 表示
表示![]() 是关于theta的实值函数。表示了用户u与项目i、项目j之间的潜在关系。
是关于theta的实值函数。表示了用户u与项目i、项目j之间的潜在关系。
可以由下面的BPR-OPT推导过程,训练过程为随机梯度下降

且有![]()
训练过程:
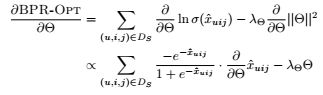

以上基本上就是BPR的训练过程,在结合MF来获得个性化排名。
MF-BPR
利用矩阵分解U-I矩阵![]() ,可以用
,可以用![]()
矩阵P为M*K,M为用户个数,K为用户特征的维度,行向量表示用户u的潜在特征向量。
矩阵Q为N*K,N为项目个数,K为项目特征的维度,行向量表示项目i的潜在特征向量。
而![]() 为两个向量的内积形式来表示用户u对项目i的偏好程度。
为两个向量的内积形式来表示用户u对项目i的偏好程度。
而在BPR中是[u,i,j]三元组即![]() 的形式,是关于theta的函数,我们训练模型的参数即为theta,而theta主要包括P矩阵和Q矩阵,迭代训练。具体的训练过程为随机梯度下降:
的形式,是关于theta的函数,我们训练模型的参数即为theta,而theta主要包括P矩阵和Q矩阵,迭代训练。具体的训练过程为随机梯度下降:

我们要想在进行BPR,首先要获得三元组,建立训练集Ds。
![]()
预先的数据集是M*N的,我们处理成M个N*N的数据来作为数据集。
初始化P,Q矩阵
利用pu,qi向量内积来计算xu,i,在计算的xu,i,j然后再根据训练过程的计算公式更新Theta,从而获得更新了的pu,qi,这样迭代训练直到Theta收敛。