笔试 | 平安银行笔试题
平安银行网申部分题
- 1 前言
- 2 笔试题
- 2.1 混淆矩阵是什么,准确率、精准率、召回率的定义
- 2.2 交叉熵是什么,在二分类问题中为什么引入交叉熵作为Loss function而不是直接优化准确率
- 2.3 Early Stopping是什么
- 参考
1 前言
最近有同学参加了平安银行在线笔试的题目,记录一下做一波~
2 笔试题
2.1 混淆矩阵是什么,准确率、精准率、召回率的定义
在分类问题中,会有混淆矩阵的概念。具体的可以参见之前的3篇博客:
- 机器学习 | 混淆矩阵和两类错误的关系
- 机器学习 | 评价指标
- 分类问题 | 评价指标
截图见下:

评价指标解释见下图:

2.2 交叉熵是什么,在二分类问题中为什么引入交叉熵作为Loss function而不是直接优化准确率
首先回答什么是交叉熵。
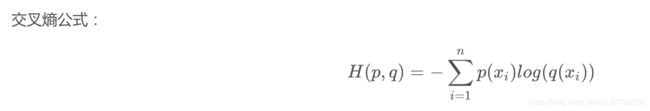
上面公式的p和q是什么呢?在机器学习中,往往用p(x) 用来描述真实分布,q(x) 用来描述模型预测的分布。
为什么有这个公式呢?什么是熵呢?具体概念总结起来有下面几个:
1、 信息熵
定义:信息熵是消除不确定性所需信息量的度量。
公式:
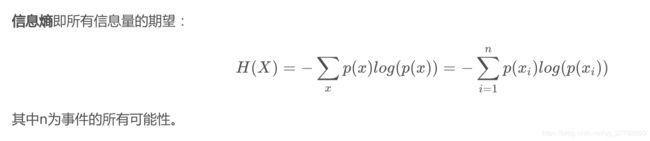
具体的细节可以参见:https://blog.csdn.net/huwenxing0801/article/details/82791879#commentBox 有点太细了。
2、 相对熵(KL散度)
公式:

即相对熵可以用来衡量两个分布的差异!
3、 交叉熵
公式:
4、上述三个熵之间的关系
相对熵 = 交叉熵 - 信息熵,具体推导见下图:

由于信息熵描述的是消除 p (即真实分布) 的不确定性所需信息量的度量,所以其值应该是最小的、固定的。那么:优化减小相对熵也就是优化交叉熵,所以在机器学习中使用交叉熵就可以了。
5、问题:为什么要引入交叉熵作为损失函数,而不是均方误差 作为损失函数?
首先,分类问题中,引入交叉熵作为损失函数的形式为:
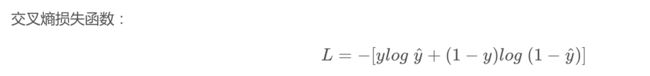
问题来了,为什么要使用上面这个损失函数的形式而不是均方误差?
这个问题再往前推一步就是,为什么我们要有损失函数呢?目的是将其作为目标函数,然后不断地优化(减小)我们的目标函数,也就是让我们预测的越来越准!那如何去优化呢?可以看到公式中我们能改变的就是预测值!而预测值又与我们的权重和常数项有关,所以现在重点来了:我们需要不断调整权重w和常数项b,然后让我们的损失函数不断地减小!而这个过程就被称为梯度下降法!
那我们下面分别来看下交叉熵损失函数和平方损失函数实现梯度下降的过程!
数据和原始公式准备:
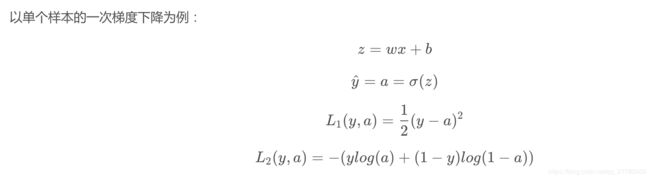
梯度下降过程:

-
L为交叉熵损失函数L2时:
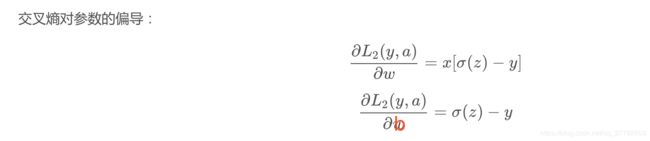
-
L为平方损失函数L1时:

上述两者的区别在哪呢? -
可以看到L1时公式中有激活函数(这里我们认为是sigmoid函数)的导数,在x越大或越小的时候导数为0,学习速度太慢了,几乎不更新了。
-
L2的时候则不涉及sigmoid激活函数的导数问题,不存在上述问题!
-
上述两点也就是为什么使用交叉熵而不是均方误差作为损失函数的原因!
关于为什么sigmoid导数在x越大或越小的时候为0,可以参见下图:左边是sigmoid函数,右边是其导数图像!

2.3 Early Stopping是什么
首先要回答的问题就是:什么是Early Stopping?为什么要进行Early Stopping?啥时候stop呢?也就是when?
为了获得性能良好的神经网络,网络定型过程中需要进行许多关于所用设置(超参数)的决策。超参数之一是定型周期(epoch)的数量:亦即应当完整遍历数据集多少次(一次为一个epoch)?
- 如果epoch数量太少,网络有可能发生欠拟合(即对于定型数据的学习不够充分);
- 如果epoch数量太多,则有可能发生过拟合(即网络对定型数据中的“噪声”而非信号拟合)。
早停法(Early Stopping)旨在解决epoch数量需要手动设置的问题。它也可以被视为一种能够避免网络发生过拟合的正则化方法(与L1/L2权重衰减和丢弃法类似)。
为什么不能一直训练下去呢?而非要提前停止?因为一直训练下去测试集上的准确率会下降!为什么会下降?可能有两个原因:
- 过拟合
- 学习率过大导致不收敛
注:关于过拟合的原因,定义,解决办法,详情见:面试 | vivo机器学习提前批面试题
ok,现在知道了什么是Early Stopping以及为啥要进行,那什么时候停止呢?
一般的做法是,在训练的过程中,记录到目前为止最好的验证集精度,当连续10次Epoch(或者更多次)没达到最佳精度时,则可以认为精度不再提高了。
参考
- https://blog.csdn.net/huwenxing0801/article/details/82791879#commentBox
- early stopping 比较学术的文章:https://www.datalearner.com/blog/1051537860479157
- 简书:https://www.jianshu.com/p/9ab695d91459