NLP最新进展之ELMo
文章目录
- 词向量发展
- NNLM
- word2vec、LSA和Glove
- ELMo
- ELMo原理
- ELMo模型
- word embedding 和 word_char_embedding
- highway Network
- ELMo源码
- ELMo应用
说是NLP最新进展,其实已经是2018年的论文了。提出ELMo的论文《Deep contextualized word representations》获得NAACL 2018的best paper,并且有效的提升了state-of-art模型在不同评测中的效果。
18年NLP届最新最耀眼的进展包括ELMo、GPT、GPT-2和号称史上最强NLP模型BERT、中文任务领域全面超越BERT的ERNIE(百度,集成在PaddlePaddle中)等,提出的这些模型在诸多评测中大放异彩,并且也被业界应用到不同的实际场景中。本系列的博客将对ELMo、GPT、GPT-2和BERT进行介绍,争取在毕业前写完。
词向量发展
自词向量提出之后,利用distributed representation将每个词映射到向量空间再进行下游的task specific传统模型或者深度学习模型处理逐渐成为了NLP中标准流程,传统的WordNet或以One-hot representation为代表的Discrete representation由于存在各种缺陷无法有效的表达词意,因此以word2vec一经提出就成为了最常用的distributed representation方式。
但是word2vec的表现也没有想象中那么惊艳,其大部分原因在于word2vec难以处理多义词问题,即静态词向量无法满足不同上下文的动态变化,而ELMo的Contextual有效的解决了这个问题,The representation for each word depends on the entire context in which it is used。
NNLM
由于预训练即词向量的训练都是基于语言模型的,因此需要从语言模型讲起,但统计语言模型,n-gram模型由于网上资料太多就按下不表了。
神经网络语言模型早在2003年就在Bengio的论文《A neural probabilistic lagnguage model》中提出,但是直到14年深度学习在NLP领域大展身手之后使得词向量有了用武之地才引起大家越来越多的关注。
在神经网络语言模型(NNLM)中,目标是生成语言模型,而词向量只是一个副产品。通过将one-hot编码映射到look-up table中随机初始化矩阵得到m维词向量,接着将m维向量拼接再通过softmax后利用最大似然估计预测下一个单词,由于随机初始化的V * m矩阵系数作为参数更新,因此得到的矩阵就成了词向量表。
word2vec、LSA和Glove
关于word2vec的资料网上实在是不要太多,这里也不做太多介绍,各位也可以参考这篇博客中有关word2vec内容的介绍。
word2vec的问题:
同样的词对(word pair),在同一个窗口中只计算一次并更新词向量(This captures co-occurrence of words one at a time),当下次再遇到相同的词对时,需要对此词对再做相同的处理,而没有统计此词对在整个语料中出现的次数信息。通常这种词对出现次数的统计信息可以通过co-occurrence matrix(共现矩阵) X,采用长度为1的时间窗口表达。
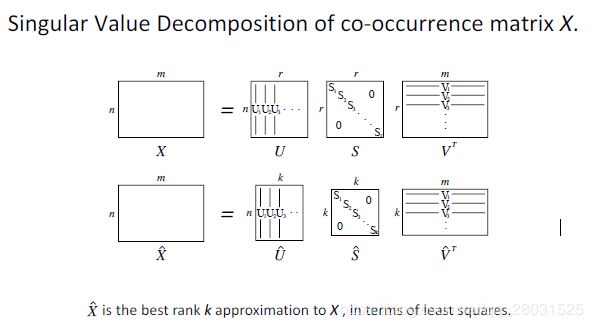
但是对于co-occurrence矩阵,由于采用长度为1的窗口,整个矩阵有较大的稀疏性。因此在这种矩阵的基础上,可以利用SVD减少向量维度。

Dimension Reduction on X: (SVD)
当然SVD也存在很多问题,对词和文档而言,共现矩阵X需要很大的存储空间和计算量,此外常用词比如the,a会大量的出现。
下图是对SVD代表的统计次数为代表的方法和Skip-Gram代表的直接预测的方法的比较。
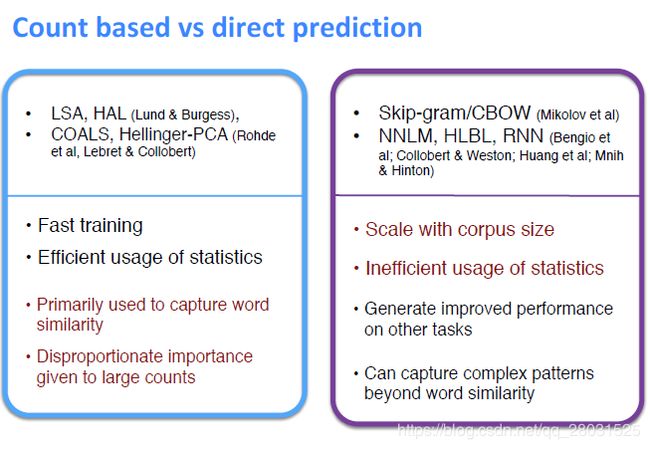
在以SVD代表的统计方法中,共现矩阵统计了词对出现的频率,但是在统计中,对于词对缺乏不一致性(即缺乏对常用词和非常用词,常用词比如the or and能表达的语义信息很少)的考虑,此外在词类比任务(word analogy task)中表现较差,也即得到的语义向量难以把握词与词之间的线性关系(类似于queen,king,man,woman这类关系)。These methods utilize low-rank approximations to decompose large matrices that captures statistics information about a corpus.对于co-occurrence matrix,SVD仅仅只是做了一个矩阵分解,对于全局信息的利用还是比较低级的分析。
而局部上下文窗口(以Skip-gram为例)方法,只利用了局部的上下文信息,而没有考虑整个语料库中出现的词频信息,缺乏全局统计信息(lack of global co-occurrence counts),比如:相同的词对(word1,word2),出现在当前位置时需要计算并更新词向量,在下一个位置再次组成词对时,又需要再次计算词向量。Unlike the matrix factorization methods,the shallow window-based methods suffer from the disadvantage that they do not operate directly on the co-occurrence statistic of the corpus,and they fail to take advantage of the vast amount of repetition in the data.
考虑到上述问题,在论文《Glove: Global Vectors for Word Representation》中提出Glove。The result is a new log-bilinear regression model that combines the advantages of the two major model families in the literature:global matrix factorization and local context window methods. Our model efficiently leverages statistical information by training only on the nonzero elements in a word-word co-occurrence matrix,rather than on the entire sparse matrix or on individual context windows in a large corpus.

在GloVe中,the matrix X denoted by a matrix of word-word co-occurrence counts, while the entries X(ij) tabulate the number of times word i occur in the context of word j. 其中, 为了减弱那些常用词的权值(The performance can be increased by filtering the data so as to reduce the effective value of the weighting factor for frequent words)
此时,计算的复杂度集中体现在矩阵X的元素个数上,因此在GloVe中,只是用那些非零的实体。

如Skip-Gram一样,The model generates two sets of word vectors,W and W’,when X is symmetric, W and W’ are equivalent and differ only as a result of their random initialization. To make it robust and reduce over-fitting,we choose the sum W+W’ as our word vectors.将W+W’作为词向量。
在很多任务上,不管是采用intrinsic estimation 还是extrinsic estimation,GloVe的表现都比其他两者要好。We construct a model that utilizes the main benefit of count data while simultaneously capturing the meaningful linear substructure prevalent in recent log-bilinear prediction-based methods like word2vec.
ELMo
当然,除了word2vec没有利用统计信息之外,导致word2vec的效果没有那么惊艳的主要原因恐怕是其难以处理多义词问题。在word2vec对多义词编码时,无法区分不同词义,尽管多义词在不同的上下文情景中可能会有不同的含义,但是在语言模型中,无论什么上下文经过同一个词时,预测的还是同一个词而且同一个单词位于同一行的参数空间,导致不同的上下文信息都会编码到相同的word embedding空间中,因此其无法区分同一个词的不同含义。
因此在论文《Deep contextualized word representations》中提出ELMo,其核心想法就是词向量根据上下文而随时变化,也即动态词向量。
ELMo原理
这里对ELMo模型以及ELMo的源码中的比较重要的点进行分析,如word_char_embedding的使用,highway network,以及现阶段ELMo在中文领域的应用进行介绍。
ELMo模型
ELMo的深度上下文向量(deep contextualized)特性带来的优势体现在两个方面:
- Deep,采用Bi-LSTM学习单词的复杂特性,体现在LSTM语言模型的不同隐层代表的句法特征和语义特征;
- Contextualized,将不同隐层和原始embedding根据不同上下文线性结合学习单词的一词多义。
Bidirectional language models
对于 N N N个单词的序列 ( t 1 , t 2 , . . . , t N ) (t_{1},t_{2},...,t_{N}) (t1,t2,...,tN),其前向语言模型为:
p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , . . . , t k − 1 ) p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{1},...,t_{k-1}) p(t1,t2,...,tN)=k=1∏Np(tk∣t1,...,tk−1)
目前state-of-art的神经网络语言模型(本文采用类似的语言模型),首先利用word embedding或者基于CNN的char_embedding计算单词的上下文无关representation(在下一节介绍),接着通过L层的前向LSTM,在最后一层的LSTM中,利用Softmax层预测下一个单词。
后向语言模型为: p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , . . . , t N ) p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{k+1},...,t_{N}) p(t1,t2,...,tN)=k=1∏Np(tk∣tk+1,...,tN)
论文中采用的是双向LSTM语言模型,将前后向语言模型结合起来,并最大化前后向语言模型的联合对数似然损失函数: ∑ k = 1 N ( l o g p ( t k ∣ t 1 , . . . , t k − 1 ; Θ x , Θ → L S T M ; Θ S ) + l o g p ( t k ∣ t k + 1 , . . . , t N ; Θ x , Θ ← L S T M ; Θ S ) ) \sum_{k=1}^{N}(log p(t_{k}|t_{1},...,t_{k-1};\Theta _{x},\overrightarrow{\Theta}_{LSTM};\Theta _{S})+log p(t_{k}|t_{k+1},...,t_{N};\Theta _{x},\overleftarrow{\Theta}_{LSTM};\Theta _{S})) k=1∑N(logp(tk∣t1,...,tk−1;Θx,ΘLSTM;ΘS)+logp(tk∣tk+1,...,tN;Θx,ΘLSTM;ΘS))
其中, Θ x \Theta _{x} Θx表示单词的representation, Θ S \Theta _{S} ΘS表示Softmax层参数。
ELMo
ELMo的预训练是一个Bi-LSTM的语言模型。对于单词 t k t_{k} tk,一个 L L L层的双向LSTM会产生 2 L + 1 2L+1 2L+1向量表达: R k = ( x k L M , h → k , j L M , h ← k , j L M ∣ j = 1 , . . L ) = ( h k , j L M ∣ j = 0 , . . L ) R_{k}=(x_{k}^{LM},\overrightarrow{h}_{k,j}^{LM},\overleftarrow{h}_{k,j}^{LM}|j=1,..L)=({h}_{k,j}^{LM}|j=0,..L) Rk=(xkLM,hk,jLM,hk,jLM∣j=1,..L)=(hk,jLM∣j=0,..L)
其中, j = 0 j=0 j=0表示单词的embedding,而 j = 1 , . . L j=1,..L j=1,..L表示双向LSTM的隐层状态。在下游的task specific中,ELMo将会把所有层的 R R R通过线性组合表达成一维向量, E L M o k t a s k = E ( R k ; Θ t a s k ) = γ t a s k ∑ j = 0 L s j t a s k h k , j L M ELMo_{k}^{task}=E(R_{k};\Theta ^{task})=\gamma ^{task}\sum_{j=0}^{L}s_{j}^{task}h_{k,j}^{LM} ELMoktask=E(Rk;Θtask)=γtaskj=0∑Lsjtaskhk,jLM
其中, s j t a s k s_{j}^{task} sjtask归一化权重,而 γ t a s k \gamma ^{task} γtask用来平衡不同层的向量,在后序的实验中,可以发现该参数对结果的影响十分明显。
EMLo在实际的应用中分为两个阶段,一是利用语言模型进行预训练,首先使用biLSTM语言模型在大规模的语料中训练单词的word embedding并且记录下LSTM在每一层的向量表达;当预训练完BiLSTM后,也可以在任务语料中进行fine tuning,这会降低语言模型的困惑度同时提高下游任务的效果,这种方式也可以看作是domain transfer;二是在下游的有监督学习任务中,将任务语料输入BiLSTM的输入端,通过学习从底层到高层的权重参数线性组合不同层次的向量表达,并将其作为新的特征补充到下游任务中,此时不同的上下文通过不同的组合参数进行调整,也就达到了“动态调整”的效果。
word embedding 和 word_char_embedding
//TODO
highway Network
//TODO
ELMo源码
//TODO
ELMo应用
//TODO