Python MPI多核编程入门
1. 下载并安装MPI
windows下:
- mpich下载地址:https://msdn.microsoft.com/en-us/library/bb524831(v=vs.85).aspx?f=255&MSPPError=-2147217396

- 点进download之后包含两个文件:msmpisdk.msi和MSMpiSetup.exe
- 分别下载并安装
- 添加BIN目录到系统路经
- 命令行安装mpi4py:pip install mpi4py
2. MPI与mpi4py
MPI是Message Passing Interface的简称,也就是消息传递。消息传递指的是并行执行的各个进程具有自己独立的堆栈和代码段,作为互不相关的多个程序独立执行,进程之间的信息交互完全通过显示地调用通信函数来完成。
Mpi4py是构建在mpi之上的python库,使得python的数据结构可以在进程(或者多个cpu)之间进行传递。
2.1.简单的工作方式
很简单,就是你启动了一组MPI进程,每个进程都是执行同样的代码!然后每个进程都有一个ID,也就是rank来标记我是谁。
from mpi4py import MPI
print("my rank is: %d" %MPI.COMM_WORLD.Get_rank())
注意:
在IDE中运行是一个进程,如果要实现多个进程的效果,可以将代码保存为py文件,然后在命令行中运行
如果使用的pycharm,直接在terminal里运行
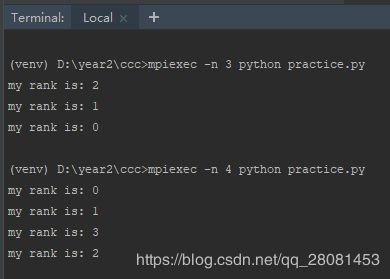
-n 4 指定启动4个mpi进程来执行后面的程序。相当于对脚本拷贝了4份,每个进程运行一份,互不干扰。在运行的时候代码里面唯一的不同,就是各自的rank也就是ID不一样。
2.2.点对点的通信
点对点通信(Point-to-PointCommunication)的能力是信息传递系统最基本的要求。意思就是让两个进程直接可以传输数据,也就是一个发送数据,另一个接收数据。接口就两个,send和recv,来个例子:
from mpi4py import MPI
comm = MPI.COMM_WORLD # 表示进程所在的通信组
comm_rank = comm.Get_rank()
comm_size = comm.Get_size() # mpi的进程个数
# 点对点通信
data_send = comm_rank
comm.send(data_send, dest=(comm_rank + 1) % comm_size)
# 如果comm_rank-1<0,会自动加comm_size变为正数再求余
data_recv = comm.recv(source=(comm_rank - 1) % comm_size)
print("my rank is %d, I received : %s" % (comm_rank, data_recv))

可以看到,每个进程都把它当前的rank值传递给下一个进程,最后的那个进程传递给第一个进程。
但这里面有个需要注意的问题,如果我们要发送的数据比较小的话还好,但是,如果要发送的数据很大,那么进程就是挂起等待,直到接收进程执行了recv指令接收了这个数据,进程才继续往下执行。因为所有的进程都会卡在发送这条指令,等待下一个进程发起接收的这个指令,但是进程是执行完发送的指令才能执行接收的指令,这就和死锁差不多了。所以一般,我们将其修改成以下的方式:
from mpi4py import MPI
comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size()
data_send = comm_rank
if comm_rank == 0:
comm.send(data_send, dest=(comm_rank + 1) % comm_size)
data_recv = comm.recv(source=(comm_rank - 1) % comm_size)
if comm_rank > 0:
data_recv = comm.recv(source=(comm_rank - 1) % comm_size)
comm.send(data_send, dest=(comm_rank + 1) % comm_size)
print("my rank is %d, I received: %s" % (comm_rank, data_recv))
第一个进程一开始就发送数据,其他进程一开始都是在等待接收数据,这时候进程1接收了进程0的数据,然后发送进程1的数据,进程2接收了,再发送进程2的数据……知道最后进程0接收最后一个进程的数据,从而避免了上述问题。其实也就是进程0来控制整个数据处理流程。
2.3.群体通信
点对点通信是一对一,群体通信是一对多。但是,群体通信是以更有效的方式工作的。它的原则就一个:尽量把所有的进程在所有的时刻都使用上!
群体通信还是发送和接收两类,一个是一次性把数据发给所有人,另一个是一次性从所有人那里回收结果。
2.3.1.广播bcast
将一份数据发送给所有的进程。例如我有200份数据,有10个进程,那么每个进程都会得到这200份数据。
from mpi4py import MPI
comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size()
if comm_rank == 0:
data = [i for i in range(comm_size)]
data = comm.bcast(data if comm_rank == 0 else None, root=0)
print("rank %d, got : %s" % (comm_rank, data))

Root进程(进程0)自己建了一个列表,然后广播给所有的进程。这样所有的进程都拥有了这个列表。然后爱干嘛就干嘛了。
需要注意的是,MPI的工作方式是每个进程都会执行所有的代码,所以每个进程都会执行bcast这个指令,但只有root执行它的时候,它才兼备发送者和接收者的身份(root也会得到广播的数据),对于其他进程来说,他们都只是接收者而已。
2.3.2.散播scatter
将一份数据平分给所有的进程。例如我有200份数据,有10个进程,那么每个进程会分别得到20份数据。
from mpi4py import MPI
comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size()
if comm_rank == 0:
data = range(comm_size)
print(data)
else:
data = None
local_data = comm.scatter(data, root=0)
print('rank %d, got: %d' % (comm_rank, local_data))
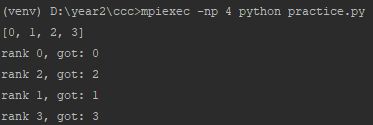
这里root进程创建了一个list,然后将它散播给所有的进程,相当于对这个list做了划分,每个进程获得等分的数据,这里就是list的每一个数。(主要根据list的索引来划分,list索引为第i份的数据就发送给第i个进程)。如果是矩阵,那么就等分的划分行,每个进程获得相同的行数进行处理。
跟广播一样,只有root执行它的时候,它才兼备发送者和接收者的身份(root也会得到属于自己的数据),对于其他进程来说,他们都只是接收者而已。
2.3.3.收集gather
那有发送,就有一起回收的函数。Gather是将所有进程的数据收集回来,合并成一个列表。下面联合scatter和gather组成一个完成的分发和收回过程:
from mpi4py import MPI
comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size()
if comm_rank == 0:
data = [i for i in range(comm_size)]
print(data)
else:
data = None
local_data = comm.scatter(data, root=0)
local_data = local_data * 2
print('rank %d, got: %d' % (comm_rank, local_data))
combine_data = comm.gather(local_data,root=0)
if comm_rank == 0:
print(combine_data)

Root进程将数据通过scatter等分发给所有的进程,等待所有的进程都处理完后(这里只是简单的乘以2),root进程再通过gather回收他们的结果,和分发的原则一样,组成一个list。
Gather还有一个变体就是allgather,可以理解为它在gather的基础上将gather的结果再bcast了一次。意思就是root进程将所有进程的结果都回收统计完后,再把整个统计结果告诉大家。这样,不仅root可以访问combine_data,所有的进程都可以访问combine_data了。
2.3.4.规约reduce
规约是指不但将所有的数据收集回来,收集回来的过程中还进行了简单的计算,例如求和,求最大值等等。为什么要有这个呢?我们不是可以直接用gather全部收集回来了,再对列表求个sum或者max就可以了吗?这样不是累死组长(root进程)吗?为什么不充分使用每个工人呢?
规约实际上是使用规约树来实现的。例如求max,可以让工人两两pk后返回最大值,然后再对第二层的最大值两两pk,直到返回一个最终的max给组长。组长就非常聪明的将工作分配下工人高效的完成,复杂度也下降了。
from mpi4py import MPI
comm = MPI.COMM_WORLD
comm_rank = comm.Get_rank()
comm_size = comm.Get_size()
if comm_rank == 0:
data = [i for i in range(comm_size)]
print(data)
else:
data = None
local_data = comm.scatter(data, root=0)
local_data = local_data * 2
print('rank %d, got: %d' % (comm_rank, local_data))
all_sum = comm.reduce(local_data, root=0, op=MPI.SUM)
if comm_rank == 0:
print('sum is:%d' % all_sum)
(venv) D:\year2\ccc>mpiexec -np 4 python practice.py
rank 3, got: 6
rank 2, got: 4
rank 1, got: 2
[0, 1, 2, 3]
rank 0, got: 0
sum is:12
可以看到,最后可以得到一个sum值。