萌懂系列之HashMap原理
前言
无论是在日常开发中还是企业面试中,我们经常遇到HashMap。一些小伙伴可能会说HashMap不是很简单嘛,只要搞清楚常用的put,get方法的使用,其他的不会直接百度。至于面试嘛,面试前突击背一下面试宝典,搞定!然后我想说的是,无论是刚刚接触java的萌新,还是在web开发中混迹数载的大牛,有谁敢说自己对于HashMap绝对很清楚,甚至背后延伸的线程安全啥的,以及jdk8对HashMap的优化等等。当然有大牛确实对这些基础都清楚。。。但是不免有些萌新对这块还是有所欠缺,所以这里和大家一起来学习一下HashMap。
HashMap的底层原理结构
在具体谈HashMap的结构之前,我需要了解两种比较常见的数据结构,就是数组和链表,对于数组,由于是需要连续的内存空间所以空间复杂度比高,但是对于寻址的时间复杂度比较低,所以对于元素的寻址效率比较高,但是对于元素的新增或者删除就比较差了,相反对于链表,它里面的元素寻址比较麻烦,但是对于元素的新增删除比较方便。那么有没有什么办法能够兼容这两者的优势呢,取长补短?
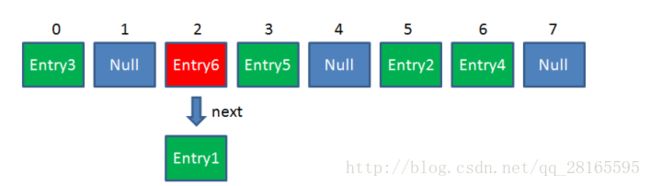
我们都知道在HashMap中都是存储key,value的键值对的集合,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。在HashMap中数组中,初始都是为null的,如下图

那么当我们向HashMap中插入一个元素时,具体是怎么操作的呢?比如调用 hashMap.put(“apple”, 0) ,插入一个Key为“apple”的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):index = Hash(“apple”)假定最后计算出的index是2,那么插入之后的结果如下

上面的插入没有任何问题,但是如果插入大量的元素的时候,这时候就可能会出现哈希冲突的情况,比如说另外一个元素的哈希值在HashMap数组索引的值也是2,这种情况改怎么处理呢?其实这时候我们就会用到上面提到的链表了,我们回去循环这个索引对应的链表,对于上面的情况,索引为2的链表中已经有一元素了,在遍历链表的时候,如果对应的key是相同的那么就直接覆盖前者,如果是不一样的,就将新加的元素插入到链表的头节点(HashMap的设计者认为,新插入的元素被get的可能性更大,索引直接插到头节点)。如下图
上面只是简单的介绍HashMap的结构,对于HashMap中的put和get方法具体是如何实现的,我们接下来再详细介绍。
HashMap中的get和put
其实对于这两个方法还是看源码比较实在,有的小伙伴可能被误导是不是说只是这两个方法重要呢,其他的方法就不需要关注,这里只是因为篇幅问题,不作深究,有兴趣的小伙伴可以自己来看看HashMap的源码。
首先是get方法
// 获取key对应的value
public V get(Object key) {
if (key == null)
return getForNullKey();
// 获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
/判断key是否相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
没找到则返回null
return null;
}
// 获取“key为null”的元素的值
// HashMap将“key为null”的元素存储在table[0]位置,但不一定是该链表的第一个位置!
private V getForNullKey() {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
} 接着是put方法
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
//将key-value添加到table[i]处
addEntry(hash, key, value, i);
return null;
} 上面的源码中都是有注释的,如果有不理解的地方欢迎加群讨论。
简单模拟哈希冲突时,元素在链表中存放过程
首先用Student类的对象作为key,在Student类中,我们重写了hashcode()和equals()方法,方便展示效果,在日常开发中需要根据自己的业务逻辑来进行重写,具体Student类代码如下
/**
* @ClassName: Student
* @Description:插入到HashMap中的key类
* @author 爱琴孩
*/
public class Student {
private String name;
private int age;
public Student(){}
public Student(String name,int age){
this.name=name;
this.age=age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
//这里重写逻辑是为了模拟哈希冲突
int result = 1;
if(name.length()%2==0){
result=50;
}else{
result=12;
}
return result;
}
@Override
public boolean equals(Object obj) {
Student s=(Student)obj;
if(name.equals(s.name)){
return true;
}else{
return false;
}
}
}测试类如下
/**
* @ClassName: Client
* @Description: TODO(测试客户端)
* @author 爱琴孩
*/
public class Client {
public static void main(String[] args) {
Student s1=new Student("爱琴孩",21);
System.out.println("s1的hashcode是"+s1.hashCode());
Student s2=new Student("爱琴孩同事",20);
System.out.println("s2的hashcode是"+s2.hashCode());
Map hashMap=new HashMap();
hashMap.put(s1, 1);
hashMap.put(s2, 2);
System.out.println("s1.hashCode()==s2.hashCode()---------"+(s1.hashCode()==s2.hashCode()));
System.out.println("s1.equals(s2)------------"+s1.equals(s2));
//日常开发逻辑中,我们应该认为s1,s2是同一个元素,应该s2会覆盖s1,所以hashMap的size应该是1
System.out.println("hashMap的size是"+hashMap.size());
}
} 我们可以在测试类中put完s1,s2之后打个断点看看这时候的HashMap中的元素情况具体如下图
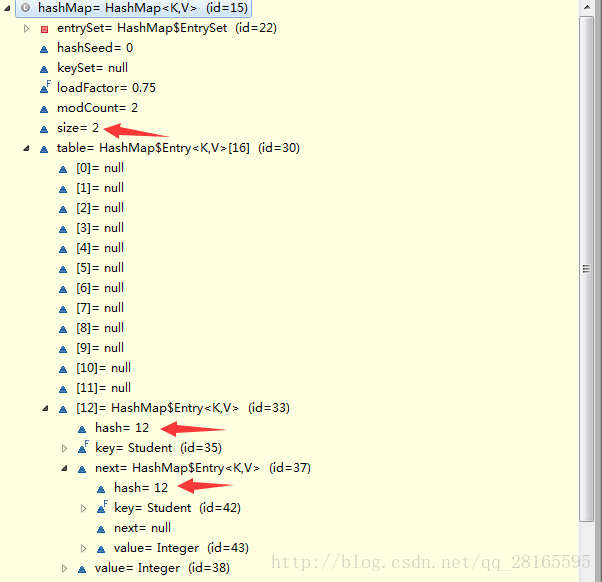
在上图中,我们可以看到这两个元素确实是被放在数组中索引为12的位置上,后插入的元素没有将前者进行覆盖。
HashMap数组的初始长度为16理由何在
在日常面试的时候,经常会有面试官可能会问,HashMap中的数组初始长度是多少,为什么在扩容的时候都需要扩充至2的多少次方?
其实对于这个问题,我们需要知道HashMap怎么根据K生成的哈希值来得到对应数组的索引值的。在源码中具体实现如下
static int indexFor(int h, int length) {
return h & (length-1);
} 这个我们要重点说下,我们一般对哈希表的散列很自然地会想到用hash值对length取模(即除法散列法),Hashtable中也是这样实现的,这种方法基本能保证元素在哈希表中散列的比较均匀,但取模会用到除法运算,效率很低,HashMap中则通过h&(length-1)的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是HashMap对Hashtable的一个改进。
接下来,我们分析下为什么哈希表的容量一定要是2的整数次幂。首先,length为2的整数次幂的话,h&(length-1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率;其次,length为2的整数次幂的话,为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h&(length-1)的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间,因此,length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。