从文本中提取单词生成单词本
词频统计及单词提取
对一段英文文本做词频统计,提取单词,查词,最终生成一个单词本,生成的单词本可以导入Anki中学习。
问题分析
考虑到单词的变形,分词后先做词形还原,之后再进行词频统计。去除掉较为简单的单词后,调用金山词霸API查询词义,下载发音音频,生成单词本。同时,用PyQt5做了一个简单的GUI。效果如下:
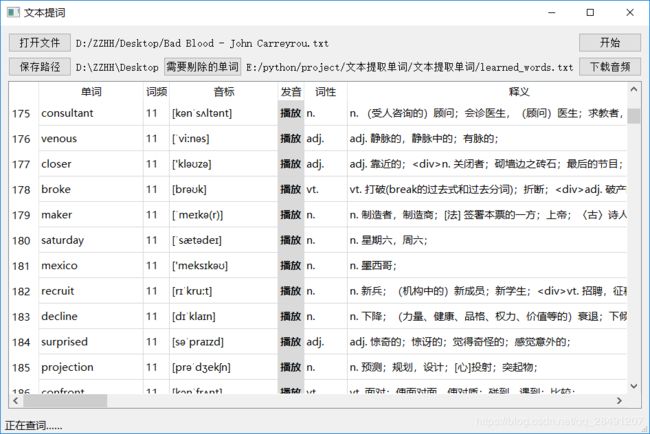
打包后生成的软件见: https://pan.baidu.com/s/1fuVdKJWqUqM97jUgTyFMrg 提取码: pstg
核心代码如下:
# -*- coding: utf-8 -*-
'''
分词,提词的主程序
先词形还原,再词频统计
去掉简单的单词后,生成单词本
'''
import requests,re,threading,traceback,os
from bs4 import BeautifulSoup
from tqdm import tqdm
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
from nltk import pos_tag
lemmatizer = WordNetLemmatizer()
Max_lookup_connections = 5
Max_download_audio_connections = 10
class vocabulary(object):
def __init__(self,file,learned_words_file = 'learned_words.txt',save_path='',download_audio=False):
'''
:param: file: 待处理的文本
:param: learned_words_file: 已学会的简单的单词本
:param: save_path: 要保存的路径,默认程序文件下
:param: download_autio:是否下载音频,默认为false
'''
#生成保存路径
self.file = file
if save_path:
if not os.path.isdir(save_path):
os.makedirs(save_path)
else:
save_path = './'
self.learned_words_file = learned_words_file
self.save_path=save_path
self.name = os.path.basename(file).split('.')[0]
self.save_filename = self.save_path + os.sep + self.name + '_vocabulary.txt'
self.download_audio_flag = download_audio
def run(self):
try:
raw_text,text = self.get_content(self.file)#获取文本,原始文本用以提供例句
words = self.lemmatizing(text)#单词变体还原,词形还原
self.word_counts = self.counts(words)#计数
words = self.remove_words(words)#去除简单的,已熟知的单词
look_up_result = self.get_look_up_result(words,raw_text)#查词
self.write_words(look_up_result)
if self.download_audio_flag:
self.download_audio(look_up_result)
return look_up_result
except:
traceback.print_exc()
return None
def get_content(self,file):
'''
获取文本内容,输入文件名,返回字符串。
'''
with open(file,'r',encoding='utf-8') as f:
raw_text = f.read()
text = raw_text.lower()
for ch in '''`~!@#$%^&*()_+-={}|[]\\:"?>”<;'“—‘’.…/,''':
text = text.replace(ch,' ')
return raw_text,text
def lemmatizing(self,text):
'''
词形还原,输入字符串,返回单词列表
'''
words = text.split()
print('words:',len(words))
lemm_words = []
with tqdm(total = len(words),desc='lemmatizing') as fbar:
for i in range(len(words)):
j = i+1
self.get_lemmed_one(words[i],lemm_words)
if j%1000==0:
fbar.update(1000)
#print('lemm_words: ',len(lemm_words))
return lemm_words
def get_lemmed_one(self,word,lemm_words):
try:
tag = pos_tag([word])#标注单词在文本中的成分
#需要用nltk.download('averaged_perceptron_tagger')下载资源
pos = self.get_pos(tag[0][1])#转为词性
if pos:
lemm_word = lemmatizer.lemmatize(word,pos)#词形还原,还原词根
lemm_words.append(lemm_word)
else:
lemm_words.append(word)
except:
print(word)
def get_pos(self,tag):
#需要用nltk.download('wordnet')下载资源
if tag.startswith('J'):
return wordnet.ADJ
if tag.startswith('V'):
return wordnet.VERB
if tag.startswith('N'):
return wordnet.NOUN
if tag.startswith('R'):
return wordnet.ADV
else:
return ''
def counts(self,words):
'''
词频统计,输入单词列表,输出词频,返回字典{单词:词频}
'''
#print(len(words))
counts = {}
for word in words:
counts[word] = counts.get(word,0) +1
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
print('set words:',len(counts))
#for i in range(20):
# word,count = items[i]
# print('{0:<10}{1:>5}'.format(word,count))
return counts
def remove_words(self,words):
learned_words=[]
try:
with open(self.learned_words_file,'r',encoding='utf-8') as f:
for line in f:
line = line.replace('\n','')
learned_words.append(line)
except:
learned_words=[]
finally:
words = list(set(words) - (set(learned_words)))
print('removed_words:',len(words))
return words
def look_up_one(self,word):
#查询单个单词,返回:key(单词),ps(音标),pron(音频url),pos(词性),acceptation(释义)
#调用金山词霸开放平台API
#http://dict-co.iciba.com/api/dictionary.php?w=moose&key=4EE27DDF668AD6501DCC2DC75B46851B
url = 'http://dict-co.iciba.com/api/dictionary.php?w={}&key=4EE27DDF668AD6501DCC2DC75B46851B'.format(word)
#print(url)
try:
resp = requests.get(url)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text,'html.parser')
key = soup.key.string
ps = '[{}]'.format(soup.ps.string)
pron = soup.pron.string
pos_list = soup.select('pos')
pos = pos_list[0].string
acceptation_list = soup.select('acceptation')
acceptation = pos_list[0].string + ' ' + acceptation_list[0].string.replace('\n','').replace('\r','')
for i in range(1,len(pos_list)):
acceptation = acceptation + '' + pos_list[i].string + ' ' + acceptation_list[i].string.replace('\n','').replace('\r','') + ''
return (key,ps,pron,pos,acceptation)
except:
#print(url)
#traceback.print_exc()
return None
def get_sen(self,word,text):
#获取原文例句:
pattern= '\\..*?{}.*?\\.'.format(word) #问题:大单词包含该小单词
match =re.search(pattern,text)
if match:
return match.group(0)[2:]
else:
return ' '
def get_look_up_result(self,words,text):
'''
查词,返回字典列表,key(单词),ps(音标),pron(音频url),pos(词性),acceptation(释义)
key: 单词,count: 词频,ps: 音标,pron: 音频url,pos:词性,sen:原文例句,
'''
data = []
threads=[]
semaphore = threading.Semaphore(Max_lookup_connections)
with tqdm(total = len(words),desc='Looking Up') as fbar:
for i in range(len(words)):
j = i+1
word = words[i]
#self.look_up(word,text,data,semaphore)
semaphore.acquire()
t = threading.Thread(target=self.look_up,args=(word,text,data,semaphore))
threads.append(t)
t.start()
if j%100==0:
fbar.update(100)
for t in threads:
t.join()
print('vocabulary:',len(data))
#print(data[:10])
return data
def look_up(self,word,text,data,semaphore):
'''
查词,返回字典列表,key(单词),ps(音标),pron(音频url),pos(词性),acceptation(释义)
key: 单词,count: 词频,ps: 音标,pron: 音频url,pos:词性,sen:原文例句,
'''
if self.look_up_one(word):
datum = {}
key,ps,pron,pos,acceptation=self.look_up_one(word)
sen = self.get_sen(word,text)
count = self.word_counts.get(key,0)
datum['key'] = key
datum['count'] = count
datum['ps'] = ps
datum['pron'] = pron
datum['pos'] = pos
datum['acceptation'] = acceptation
datum['sen'] = sen
data.append(datum)
semaphore.release()
def write_words(self,data):
with open(self.save_filename,'w',encoding='utf-8') as f:
for datum in data:
pron = '[sound:{}.mp3]'.format(datum['key'])
text = '{}\t{}\t{}\t{}\t{}\n'.format(datum['key'],datum['ps'],pron,datum['acceptation'],datum['sen'])
f.write(text)
def download_audio_one(self,key,url):
'''下载单词发音音频'''
resp = requests.get(url)
filepath = self.save_path + os.path.sep + 'audio'
if not os.path.isdir(filepath):
os.mkdir(filepath)
filename = filepath + os.sep + key + '.mp3'
if not os.path.isfile(filename):
with open(filename,'wb') as f:
f.write(resp.content)
def download_audio_one_thread(self,key,url,semaphore):
'''下载单词发音音频'''
resp = requests.get(url)
filepath = self.save_path + os.path.sep + 'audio'
filename = filepath + os.sep + key + '.mp3'
if not os.path.isfile(filename):
with open(filename,'wb') as f:
f.write(resp.content)
semaphore.release()
def download_audio(self,data):
filepath = self.save_path + os.path.sep + 'audio'
if not os.path.isdir(filepath):
os.mkdir(filepath)
threads = []
semaphore = threading.Semaphore(Max_download_audio_connections)
len_words = len(data)
with tqdm(total = len_words,desc='Downloading sudio') as fbar:
for i in range(len_words):
j = i+1
key = data[i]['key']
url = data[i]['pron']
semaphore.acquire()
t = threading.Thread(target=self.download_audio_one_thread,args=(key,url,semaphore))
threads.append(t)
t.start()
if j%100==0:
fbar.update(100)
for t in threads:
t.join()
if __name__=='__main__':
from pandas import DataFrame
file = 'Bad Blood - John Carreyrou_1.txt'
work = vocabulary(file,save_path = '')
data = work.run()
#pf = DataFrame(data)
#print(pf)
生成GUI代码为:
# -*- coding: utf-8 -*-
from PyQt5.QtWidgets import QApplication,QMainWindow,QFileDialog,QTableWidgetItem
from PyQt5.QtGui import QFont,QColor
from PyQt5.QtCore import Qt,QDir
from 文本提取单词_UI import Ui_MainWindow
from vocabulary_2 import vocabulary
from pandas import DataFrame
import traceback
import threading
import os
class MainWindow(QMainWindow,Ui_MainWindow):
def __init__(self,parent=None):
super(MainWindow,self).__init__(parent)
self.setupUi(self)
self.file = ''
self.learned_word_file = ''
self.savepath = './'
self.setWindowTitle('文本提词')
#连接信号与槽
self.pushButton_openfile.clicked.connect(self.openfile)#打开文本文件(utf-8)
self.pushButton_savepath.clicked.connect(self.change_save_path)#改变保存路径
self.pushButton_learnedfile.clicked.connect(self.openlearnedfile)#打开简单词汇文件(utf-8)
self.pushButton_start.clicked.connect(self.run)#生成单词本
self.tableWidget.cellClicked.connect(self.listen_one_new)#播放发音
self.pushButton_download_audio.clicked.connect(self.download_audio)
def openfile(self):
#打开文件
filename, _ = QFileDialog.getOpenFileName(self,'Open file','D:\\','Txt files(*.txt)')
#print(filename)
self.label_openfile.setText(filename)
self.file = filename
def change_save_path(self):
#修改保存路径
directory = QFileDialog.getExistingDirectory(self,'选取文件夹',self.savepath)
self.savepath = QDir.toNativeSeparators(directory)# 路径以windows支持的显示方式进行显示。
self.label_savepath.setText(self.savepath)
def openlearnedfile(self):
filename, _ = QFileDialog.getOpenFileName(self,'Open file','D:\\','Txt files(*.txt)')
self.label_learnedfile.setText(filename)
self.learned_word_file = filename
def run(self):
self.statusBar().showMessage('正在查词......')
self.vocabulary = vocabulary(file=self.file,learned_words_file=self.learned_word_file,save_path=self.savepath)
data = self.vocabulary.run()
if data:
self.show_tablewidget(data)
self.vocabulary.write_words(self.data)
def show_tablewidget(self, dict_data):
'''在tableWidget显示dict_data'''
tableWidget = self.tableWidget
'''排序'''
df = DataFrame(dict_data).sort_values(by='count',ascending = False)
_temp = df.to_dict('index')
dict_data = list(_temp.values())
self.data = dict_data
'''tableWidget的初始化'''
list_col = ['key','count','ps','pron','pos','acceptation','sen']
len_col = len(list_col)
len_index = len(dict_data)
tableWidget.setRowCount(len_index)#设置行数
tableWidget.setColumnCount(len_col)#设置列数
tableWidget.setHorizontalHeaderLabels(['单词', '词频', '音标','发音','词性','释义','例句']) # 设置垂直方向上的名字
tableWidget.setVerticalHeaderLabels([str(i) for i in range(1, len_index + 1)]) # 设置水平方向上的名字
'''填充数据'''
for index in range(len_index):
for col in range(len_col):
name_col = list_col[col]
if name_col == 'pron':
item = QTableWidgetItem('播放')
item.setTextAlignment(Qt.AlignCenter)
font = QFont()
font.setBold(True)
font.setWeight(75)
item.setFont(font)
item.setBackground(QColor(218, 218, 218))
item.setFlags(Qt.ItemIsUserCheckable | Qt.ItemIsEnabled)
tableWidget.setItem(index, col, item)
else:
tableWidget.setItem(index,col,QTableWidgetItem(str(dict_data[index][name_col])))
tableWidget.resizeColumnsToContents()
tableWidget.setColumnWidth(5, 500)
def listen_one_new(self,row,column):
if column == 3:
download_one = self.data[row]
listen_thread = threading.Thread(target = self.listen_one_new_thread,args=(download_one,),daemon=True)
listen_thread.start()
def listen_one_new_thread(self,download_one):
key = download_one['key']
url = download_one['pron']
self.vocabulary.download_audio_one(key,url)
filename = self.savepath + os.path.sep + 'audio' + os.sep + key + '.mp3'
print(os.path.abspath(filename))
os.system(os.path.abspath(filename))
def download_audio(self):
self.statusBar().showMessage('音频下载中...')
try:
self.vocabulary.download_audio(self.data)
self.statusBar().showMessage('音频下载成功')
except:
self.statusBar().showMessage('音频下载失败')
if __name__=='__main__':
import sys
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
UI代码为:
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file '文本提取单词.ui'
#
# Created by: PyQt5 UI code generator 5.11.3
#
# WARNING! All changes made in this file will be lost!
from PyQt5 import QtGui, QtWidgets
from PyQt5.QtCore import QRect, QMetaObject,QCoreApplication
from PyQt5.QtWidgets import QWidget,QVBoxLayout,QHBoxLayout,QPushButton,QLabel,QSpacerItem,QSizePolicy,QTableWidget,QStatusBar
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(833, 594)
self.centralwidget = QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.verticalLayout = QVBoxLayout(self.centralwidget)
self.verticalLayout.setObjectName("verticalLayout")
self.horizontalLayout = QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
self.pushButton_openfile = QPushButton(self.centralwidget)
self.pushButton_openfile.setObjectName("pushButton_openfile")
self.horizontalLayout.addWidget(self.pushButton_openfile)
self.label_openfile = QLabel(self.centralwidget)
self.label_openfile.setText("")
self.label_openfile.setObjectName("label_openfile")
self.horizontalLayout.addWidget(self.label_openfile)
spacerItem = QSpacerItem(40, 20, QSizePolicy.Expanding, QSizePolicy.Minimum)
self.horizontalLayout.addItem(spacerItem)
self.pushButton_start = QPushButton(self.centralwidget)
self.pushButton_start.setObjectName("pushButton_start")
self.horizontalLayout.addWidget(self.pushButton_start)
self.verticalLayout.addLayout(self.horizontalLayout)
self.horizontalLayout_2 = QHBoxLayout()
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.pushButton_savepath = QPushButton(self.centralwidget)
self.pushButton_savepath.setObjectName("pushButton_savepath")
self.horizontalLayout_2.addWidget(self.pushButton_savepath)
self.label_savepath = QLabel(self.centralwidget)
self.label_savepath.setText("")
self.label_savepath.setObjectName("label_savepath")
self.horizontalLayout_2.addWidget(self.label_savepath)
spacerItem1 = QSpacerItem(40, 20, QSizePolicy.Expanding, QSizePolicy.Minimum)
self.horizontalLayout_2.addItem(spacerItem1)
self.pushButton_learnedfile = QPushButton(self.centralwidget)
self.pushButton_learnedfile.setObjectName("pushButton_learnedfile")
self.horizontalLayout_2.addWidget(self.pushButton_learnedfile)
self.label_learnedfile = QLabel(self.centralwidget)
self.label_learnedfile.setText("")
self.label_learnedfile.setObjectName("label_learnedfile")
self.horizontalLayout_2.addWidget(self.label_learnedfile)
spacerItem2 = QSpacerItem(40, 20, QSizePolicy.Expanding, QSizePolicy.Minimum)
self.horizontalLayout_2.addItem(spacerItem2)
self.pushButton_download_audio = QPushButton(self.centralwidget)
self.pushButton_download_audio.setObjectName("pushButton_download_audio")
self.horizontalLayout_2.addWidget(self.pushButton_download_audio)
self.verticalLayout.addLayout(self.horizontalLayout_2)
self.tableWidget = QTableWidget(self.centralwidget)
self.tableWidget.setObjectName("tableWidget")
self.tableWidget.setColumnCount(0)
self.tableWidget.setRowCount(0)
self.verticalLayout.addWidget(self.tableWidget)
MainWindow.setCentralWidget(self.centralwidget)
self.statusbar = QStatusBar(MainWindow)
self.statusbar.setObjectName("statusbar")
MainWindow.setStatusBar(self.statusbar)
self.retranslateUi(MainWindow)
QMetaObject.connectSlotsByName(MainWindow)
def retranslateUi(self, MainWindow):
_translate = QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))
self.pushButton_openfile.setText(_translate("MainWindow", "打开文件"))
self.pushButton_start.setText(_translate("MainWindow", "开始"))
self.pushButton_savepath.setText(_translate("MainWindow", "保存路径"))
self.pushButton_learnedfile.setText(_translate("MainWindow", "需要剔除的单词"))
self.pushButton_download_audio.setText(_translate("MainWindow", "下载音频"))