分布式深度学习环境配置,NVIDIA驱动+cuda+cudnn+docker
假设设备中已经安装了python3.6
1.安装NVIDIA驱动
在Ubuntu的操作系统上,输入
ubuntu-drivers devices查看推荐驱动

我的推荐是NVIDIA384,然后输入
sudo ubuntu-drivers autoinstall按推荐安装。
之后输入
nvidia-smi弹出gpu信息即代表安装成功
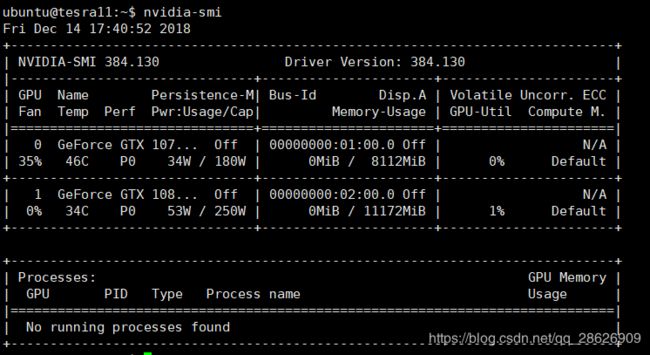
二,安装cuda
我安装的是cuda9.0,所以我在我的文件夹下直接wget下载(不同的版本号可以根据自己的需求去官网下载)
下载链接:https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb
其实大家可以直接在linux下下载:
wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb然后逐步输入(在下载cuda的文件下):
sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64.debsudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pubsudo apt-get updatesudo apt-get install cuda
然后配置环境变量:
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}- 如果是64位系统,输入:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}} - 如果是32位系统,输入:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
然后我们输入:
nvcc -V
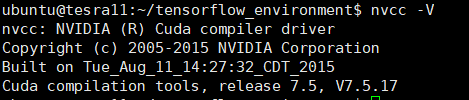
出现上图,恭喜你安装成功,然后重启
但是别高兴太早,安装cudnn之后可能cuda就会出现版本问题,后面讲解决办法
三、cudnn安装
同样,我采用wget下载,下载链接:
https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v7.4.1.5/prod/9.0_20181108/cudnn-9.0-linux-x64-v7.4.1.5.tgz
wget https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v7.4.1.5/prod/9.0_20181108/cudnn-9.0-linux-x64-v7.4.1.5.tgz然后:
tar -xzvf cudnn-9.0-linux-x64-v7.4.1.5.tarsudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp -a cuda/lib64/libcudnn* /usr/local/cuda/lib64cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2出现:

则ok了。好,这时候看着已经ok了,但是有人可能就用分布式tensorflow跑了一下,然后就报错了,是cuda的错误。这是为什么呢?因为我们把cuda给升级了。。。版本对不上了
解决方法:
1.sudo apt-get install cuda-9-0** (强制将cudnn降到9.0版本)
2.sudo apt autoremove cuda (移除高版本的cuda)
然后输入 nvcc -V,结果会提示让你安装什么,按提示安装,这时候应该就好了。
然后重启
四,可能出现的问题
1.因为我们在安装各种乱七八糟的东西时候,会是不是的用到apt-get update以及其他的,如下图:
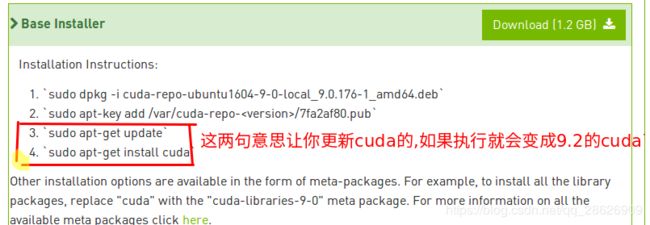
解决方案:执行三中的红色部分。
2.跑分布式tensorflow的时候可能会出现 内核已转移的问题
解决方案:cuda降版本,重启(还是三中的红字部分)
3.tensorflow报错
解决方案,1.排查是否安装tensorflow-gpu(我自己安装的1.10版本)
是否安装 依赖包,如scipy,mkl, numpy,
2.更新sudo apt-get update
sudo apt-get upgrade
3.更新完之后看看cuda,注意降版本
4.grpc错误
解决方案:tensorflow.python.framework.errors_impl.UnknownError: Could not start gRPC server
五,测试代码:
分布式tensorflow测试代码
六、参考文献:
Ubuntu16.04中cuDNN安装教程
Linux安装NVIDIA显卡驱动的正确姿势
ModuleNotFoundError: No module named 'gdbm'
Ubuntu怎样安装Python3.6Ubuntu + CUDA9.0 + tensorflow-gpu 安装过程
Ubutu16.04+Cuda9.2/9.0+Cudnn7.12/7.05+TensorFlow-gpu-1.8/1.6
七、docker的安装
1.安装docker ce
1.sudo apt-get update
2.sudo apt-get install apt-transport-https ca-certificates curl software-properties-common
3.curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
4.sudo apt-key fingerprint 0EBFCD88
5.sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"
6.sudo apt-get update
7.sudo apt-get install docker-ce
2.安装NIVEA-docker
1.curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt-key add -
2.curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
3.sudo apt-get update
4.sudo apt-get install nvidia-docker2
5.sudo pkill -SIGHUP dockerd
6.docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
7.docker pull registry.docker-cn.com/ufoym/deepo
3.测试安装
输入 docker -v即可

然后重启
4.可能出现的问题
如果哪一步出现问题,先一步一步安装完再说,然后有时候你就发现能竟然自己好了,哈哈哈哈哈哈哈,拜拜