分布式tensorflow测试代码
数据集:minist (我走的是本地读取)
数据集链接:https://pan.baidu.com/s/1o2faz60YLaba3q7hn_JWqg 提取码:yv3y
代码和数据集放在一个文件下

目的:测试服务器是否安装成功cuda和cudnn
环境:ubuntu16.04,python3.6,tensorflow-gpu1.10,cuda9.0,cudnn7.4
import math
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
import time
flags = tf.app.flags
flags.DEFINE_string("data_dir", r"./mnist", "the directory of mnist_data")
flags.DEFINE_integer("train_step",1000, "the step of train")
flags.DEFINE_integer("batch_size", 128, "the number of batch")
flags.DEFINE_integer("image_size", 28, "the size of image")
flags.DEFINE_integer("hid_num", 100, "the size of hid layer")
flags.DEFINE_float("learning_rate", 0.01, "the learning rate")
# flags.DEFINE_string("checkpoint_dir",r"./temp/checkpoint","the directory of checkpoint")
# flags.DEFINE_string("log_dir",r"./temp/log","the directory of log")
flags.DEFINE_string("summary_dir", r"./temp/summary", "the directory of summary")
flags.DEFINE_integer("task_index", 0, "the index of task")
flags.DEFINE_string("job_name", "ps", "ps or worker")
flags.DEFINE_string("ps_host","localhost:22333", "the ip and port in ps host")
flags.DEFINE_string("worker_host", "localhost:21333", "the ip and port in worker host")
flags.DEFINE_string("cuda", "", "specify gpu")
FLAGS = flags.FLAGS
if FLAGS.cuda:
os.environ["CUDA_VISIBLE_DEVICES"] = FLAGS.cuda
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
def main(_):
#train_step_list=[50]
ps_spc = FLAGS.ps_host.split(",")
worker_spc = FLAGS.worker_host.split(",")
cluster = tf.train.ClusterSpec({"ps": ps_spc, "worker": worker_spc})
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
is_chief = (FLAGS.task_index == 0)
with tf.device(tf.train.replica_device_setter(cluster=cluster)):
start = time.time()
global_step = tf.Variable(0, name="global_step", trainable=False)
hid_w = tf.Variable(tf.truncated_normal(shape=[FLAGS.image_size * FLAGS.image_size, FLAGS.hid_num],
stddev=1.0 / FLAGS.image_size), name="hid_w")
hid_b = tf.Variable(tf.zeros(shape=[FLAGS.hid_num]), name="hid_b")
sm_w = tf.Variable(tf.truncated_normal(shape=[FLAGS.hid_num, 10], stddev=1.0 / math.sqrt(FLAGS.hid_num)),
name="sm_w")
sm_b = tf.Variable(tf.zeros(shape=[10]), name="sm_b")
x = tf.placeholder(tf.float32, [None, FLAGS.image_size * FLAGS.image_size])
y_ = tf.placeholder(tf.float32, [None, 10])
hid_lay = tf.nn.xw_plus_b(x, hid_w, hid_b)
hid_act = tf.nn.relu(hid_lay)
y = tf.nn.softmax(tf.nn.xw_plus_b(hid_act, sm_w, sm_b))
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-4, 1.0)))
train_op = tf.train.GradientDescentOptimizer(FLAGS.learning_rate).minimize(cross_entropy,
global_step=global_step)
#last_step=500
hooks = [tf.train.StopAtStepHook(last_step=FLAGS.train_step)]
# tf.train.CheckpointSaverHook(checkpoint_dir=FLAGS.checkpoint_dir,
# save_steps=1000)]
# gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
# sess_config = tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False, allow_soft_placement=True)
# sess_config.gpu_options.allow_growth = True
sess_config = tf.ConfigProto(log_device_placement=False)
with tf.train.MonitoredTrainingSession(master=server.target,
is_chief=is_chief,
# checkpoint_dir=FLAGS.checkpoint_dir,
hooks=hooks,
config=sess_config)as mon_sess:
step = 0
while True:
step += 1
batch_x, batch_y = mnist.train.next_batch(FLAGS.batch_size)
train_feed = {x: batch_x, y_: batch_y}
_, loss_v, g_step = mon_sess.run([train_op, cross_entropy, global_step], feed_dict=train_feed)
print("step: %d, cross_entropy: %f, global_step:%d" % (step, loss_v, g_step))
if mon_sess.should_stop():
end = time.time()
#print("step_size=", last_step)
print("time costing:", end - start)
break
if __name__ == "__main__":
tf.app.run()
代码是一个ps,一个worker。19行和20行都走的是本地ip,如有需要多机分布式,自行修改。
如果运行提示grpc错误,杀死python的进程
运行代码:
python mnist_monite.py --job_name=ps --task_index=0 --cuda=-1再开一个页面,输入:
python mnist_monite.py --job_name=worker --task_index=0 --cuda=0然后下图是PS的运行截图:
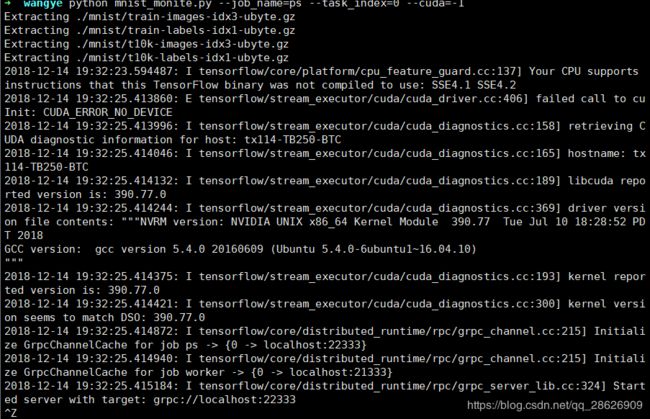
然后是worker的截图:
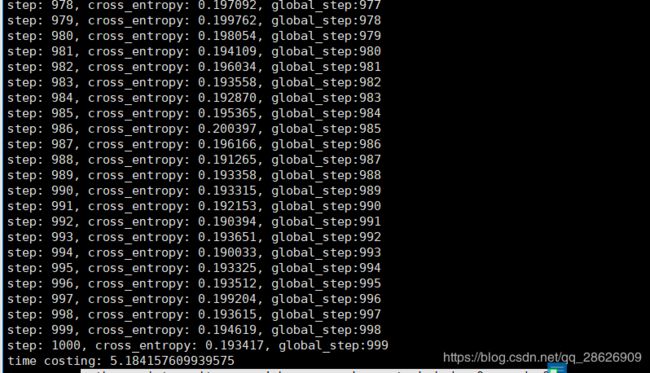
ok了