菜鸟独白
用Python来玩转数据分析实在是太爽了,因为有强大的Pandas来处理数据非常方便,我个人对数据分析情有独钟,探索数据的秘密非常好玩!前段时间写过一篇小白学数据分析入门招式,但是进阶的部分上次没有来得及整理,今天分享给大家。
我们依然用比较有名的泰坦尼克数据集来做示例,通过对这个数据集的处理,来快速上手数据分析的常见招式和基本手法,让初学者可以快速上手数据分析!

要点:
数据的字符处理
数据的过滤
数据的分组
数据的透视表
1.数据集的字符处理
第一招:对列的处理
我们看一下这个数据集里面的列都是英文的,不是很爽,我们把列的名字变成中文,这样看的舒服。

df.rename(columns={'Survived':'是否获救',
'Name':'姓名',
'Pclass':'船舱等级','Sex':'性别',
'Age':'年龄','SibSp':'兄弟姐妹数',
'Parch':'父母小孩数','Ticket':'船票',
'Fare':'船票费'})
这样处理完之后看一下是不是舒服很多:

第二招:对数据集里面的特定字符串进行替换
我们把性别里面的male替换为男,female替换为女
df['性别'].map({'female':'女','male':'男'})

第三招:对列的字符进行替换
我们看到船票比如A/5 21171 有两部分组成,一部分是英文字符,一部分是纯数字,如果我们只想保留数字部分,我们直接用str字符串进行处理
df['船票']=df['船票'].str.replace(r'[^d+]','')
df.head(3)

pandas里面的字符串功能非常强大,除了replace之外,
还有contains,split,match,findall,endswith等等,这招在清洗数据的非常有用。
2.数据集的过滤
我们在分析数据的时候经常要对数据内容进行过滤,或者是部分提取。
第四招:用逻辑表达式组合过滤
提取性别是女孩并且年龄在10岁以下的
df[(df['性别']=='女')&(df['年龄']<=10)]
df.head(3)
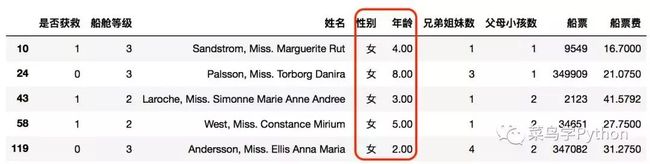
第五招:巧用不等于
提取非3等舱,并且获救乘客信息
df[(df['是否获救']==1)&(df['船舱等级']!=3)]

第六招:也可以用query函数
df.query('船舱等级==[1,2]')

3.数据的分类
我们有的时候需要对数据进行多维度的细分和统计,有下面几招:
第七招:用where函数
第一种比较简单,用where
比如我们认为比如我们认为 年龄在18以下都是未成年,18岁以上成年的
df['是否成年']=np.where(df['年龄']>=18,'成年','未成年')
df.sample(3)

第八招:用万能的apply函数
apply可以处理比较复杂的逻辑,比如我们把年龄划分为几个阶段,小孩,青年,成人,老人。

看一下新增的列"年龄分类"是不是层次分类更精准!
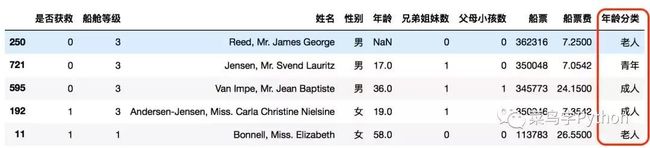
4.数据的切片和透视表
第九招:神奇的groupby函数
我们喜欢对数据按照某种类别分组统计:
1).从性别的维度来对是否获救的人数进行统计
df.groupby('性别')['是否获救'].count()
性别
女 314
男 577
Name: 是否获救, dtype: int64
2).从船舱的等级来看是非获救
df.groupby('船舱等级')['是否获救'].count()
船舱等级
1 216
2 184
3 491
Name: 是否获救, dtype: int64
第十招:对数据进行轴切片分析
比如我们希望对是非获救和船舱等级这个两个轴进行深入切片分析,这样的伎俩在R语言里面也经常用到,这里pandas给我们提供了非常方便的agg函数
df.groupby(['是否获救','船舱等级'])['年龄'].agg(['size','max','min','mean'])
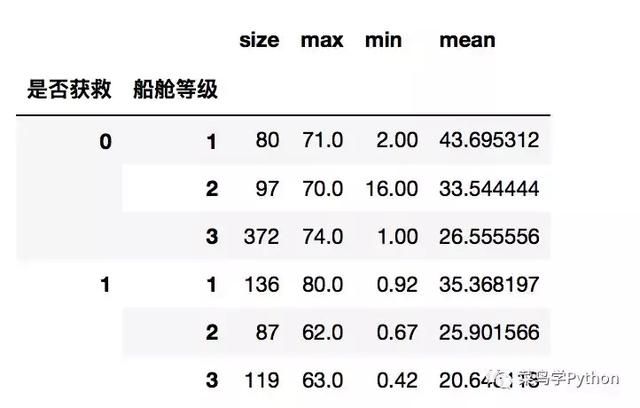
这样就很容易发现,获救里面的头等舱的人比较多,平均年龄相对未获救的要年轻不少.
第十一招:数据透视表
透视表在很多数据分析里面都有,比如常见的excel里面,pandas也提供了类似的功能.
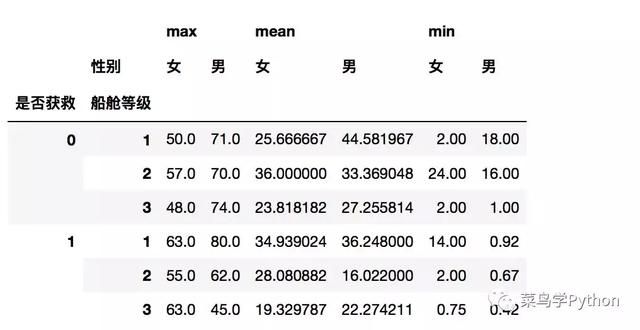
根据一个或者多个键对数据进行聚合,我们用透视表也能做出类似上面的功能,比groupby还要强大.
df.pivot_table(columns=['性别'],
index=['是否获救','船舱等级'],
values='年龄',
aggfunc={'年龄':[np.mean,min,max]})
看完上面的11招,加上前面的(18招,小白必看的数据分析招式|精选上篇),学会这些招数基本上可以算是入门数据分析了。
当然如果需要对数据分析进行系统的学习,还需要掌握很多其他的知识,如有不同见解,我在评论去等着你。
![]()