深度强化学习用于对话生成(论文笔记)
一、如何定义一个好的对话
尽管SEQ2SEQ模式在对话生成方面取得了成功,但仍出现了两个问题(图1):
-
通过使用最大似然估计(MLE)目标函数预测给定会话上下文中的下一个对话转角来训练SEQ2SEQ模型。SEQ2SEQ模型倾向于生成概率较大、高度通用的回答,比如“我不知道”,而不管输入是什么。然而,“我不知道”显然不是一个好的行动,因为它结束了谈话。
-
系统被困在一个无限循环的重复响应中。
 图1.使用在OpenSubtitle数据集上训练的4层lstm编解码器模拟两个代理之间的对话标题
图1.使用在OpenSubtitle数据集上训练的4层lstm编解码器模拟两个代理之间的对话标题
好的对话应当是前瞻性的或互动性的,信息丰富,连贯一致。因此,我们的目标是整合SEQ2SEQ和强化学习,同时利用两者的优势。实验结果(表1右侧面板的抽样结果)表明,对比使用MLE目标函数训练的标准SEQ2SEQ模型,我们的方法促进了更持久的对话(图2)。
 图2.使用强化学习模型的对话模拟
图2.使用强化学习模型的对话模拟
二、开放领域对话中的强化学习
在这一部分中,我们详细描述了所提出的RL模型的组成部分。
学习系统由两个agents组成。我们使用p来表示从第一个agent生成的句子,使用q表示来自第二个agent的句子,两个agents轮流交谈。一个对话可以表示为由两个agents生成的句子的交替序列:![]() 。
。
作者对网络参数进行了优化,以便使用策略搜索最大限度地实现预期的未来回报。Policy gradient方法比Q-learning方法更适合我们的场景。因为在改变目标和调整策略以实现长期奖励最大化之前,我们可以使用已经产生合理响应的MLE参数初始化编码器-解码器 RNN。而Q-learning直接估计每项行动的未来预期回报,这可能与MLE目标相差数量级,因此使MLE参数不适合初始化。
Action
动作 a 就是生成的对话语句,且a是无限的,因为可以生成任意长度的序列。
State
先前的两个对话回合![]() 表示状态。通过将
表示状态。通过将![]() 喂给LSTM编码器模型,对话历史将进一步转换为向量表示。
喂给LSTM编码器模型,对话历史将进一步转换为向量表示。
Policy
策略采用LSTM编解码器的形式(即![]() ),并由其参数定义。注意,我们使用策略的随机表示(对给定状态的动作的概率分布)。确定性的策略会导致一个不连续的目标,很难使用基于梯度的方法进行优化。
),并由其参数定义。注意,我们使用策略的随机表示(对给定状态的动作的概率分布)。确定性的策略会导致一个不连续的目标,很难使用基于梯度的方法进行优化。
Reward
r 表示每项行动所获得的奖励。在本小节中,我们将讨论有助于对话成功的主要因素,并描述如何在可计算的奖励函数中对这些因素进行近似操作。
-
Ease of answering
这部分的奖励函数如下:
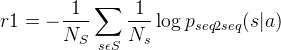
Note:S——包含8个回合的迟钝响应列表,例如: “I don’t know what you are talking about”,“I have no idea”等(这是在SEQ2SEQ对话模型中经常出现的情况)
![]() ——迟钝回复s出现的次数
——迟钝回复s出现的次数
![]() ——SEQ2SEQ模型的似然输出
——SEQ2SEQ模型的似然输出
-
Information Flow
我们希望每个代理提供新的信息在每一个回合,以保持对话的移动和避免重复的序列。因此,我们惩罚来自同一agent的连续回合之间的语义相似性。设![]() 和
和![]() 表示从编码器连续两个回合
表示从编码器连续两个回合![]() 和
和![]() 获得的表示。奖励是由它们之间的余弦相似性的负对数来给予的。
获得的表示。奖励是由它们之间的余弦相似性的负对数来给予的。
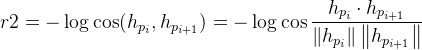
-
Semantic Coherence
我们还需要衡量反应的充分性,以避免产生的答复得到很高的奖励,但不符合语法或不连贯的情况。因此,我们考虑到行动a与历史上以前的转折之间的相互信息,以确保所产生的反应是一致和适当的:
![]()
Note:![]() ——表示一个给定的对话回合[pi,qi]产生响应的概率
——表示一个给定的对话回合[pi,qi]产生响应的概率
![]() ——表示根据响应a生成先前对话话语
——表示根据响应a生成先前对话话语![]() 的后向概率
的后向概率
![]() ——训练方式类似于标准的SEQ2SEQ模型,其源和目标互换
——训练方式类似于标准的SEQ2SEQ模型,其源和目标互换
综上,动作 a 的最终奖励是上述奖励的加权总和:
![]()
其中![]() ,设
,设![]() 。当代理人到达每句话的结尾时,就会看到奖励。
。当代理人到达每句话的结尾时,就会看到奖励。
有了打分函数,也就有了奖励机制。强化学习不再从例子中直接学习生成最大概率的回复,而是根据激励函数的指导尝试生成最大得分的回复。

第二步就不再是传入某个人类对话样本指导它学习语言模型之类,而是让它自顾自地生成一个回复。

第三步用激励函数给模型生成的回复打分,让它知道自己做得怎么样。
三、模拟
我们方法的核心思想是模拟两个agents轮流交谈的过程。通过它,我们可以探索状态-行动空间,并学习一个策略![]() 从而得到最优的预期奖励。我们采用AlphaGo风格的策略(Silveret al.,2016),使用一般的响应生成策略初始化RL系统,该策略是从完全监督的设置中学习的。
从而得到最优的预期奖励。我们采用AlphaGo风格的策略(Silveret al.,2016),使用一般的响应生成策略初始化RL系统,该策略是从完全监督的设置中学习的。
Supervised Learning
对于训练的第一阶段,我们在先前工作的基础上,使用监督的SEQ2SEQ模型预测给定对话历史的生成目标序列。监督模型的结果稍后将用于初始化。
我们在OpenSubtitle数据集上训练了一个SEQ2SEQ模型,它由大约8000万个源-目标对组成。我们将数据集中的每一个回合作为目标,并将前两个句子的连接作为源输入。
Mutual Information
来自SEQ2SEQ模型的示例通常是单调乏味的,并且是通用的,例如,“我不知道”。因此,我们不希望使用预先训练的SEQ2SEQ模型初始化策略模型因为这将导致RL模型的经验缺乏多样性。对源和目标之间的相互信息进行建模将大大减少产生迟钝反应的机会,并提高一般的响应质量。现在,我们展示了如何获得一个能产生最大互信息响应的编解码模型。
我们将产生最大互信息响应的问题看作是一个强化学习问题,当模型到达序列的末尾时,观察到互信息值的奖励。
我们使用与训练的![]() 模型初始化策略模型
模型初始化策略模型![]() 。给定输入[pi, qi],我们生成一个候选列表
。给定输入[pi, qi],我们生成一个候选列表![]() 。对每一个
。对每一个![]() ,我们将从训练模型
,我们将从训练模型![]() 和
和![]() 中获得相互信息评分
中获得相互信息评分![]() ,这种相互信息得分将被用作奖励,并被反向传播到编解码模型中,使其适合于生成具有较高回报的序列。对一个序列的预期奖励是:
,这种相互信息得分将被用作奖励,并被反向传播到编解码模型中,使其适合于生成具有较高回报的序列。对一个序列的预期奖励是:
![]()
梯度是使用似然比技巧估计的:![]()
我们使用随机梯度下降来更新编解码模型中的参数。对于每一个长度序列T,我们对前L个字符进行MLE损失估计,对其余T-L个字符运用强化算法。我们逐渐将L的值退火为零。最终梯度为:
![]()
Dialogue Simulation between Two Agents
我们模拟两个agents之间的对话,让他们轮流交谈。仿真过程如下:在第一步,训练集中的一条消息被传送给第一代理。代理将输入消息编码为向量表示,并开始解码以生成响应输出。将来自第一代理的即时输出与对话历史相结合,第二代理通过将对话历史编码为表示并使用解码器RNN生成响应。随后反馈给第一个代理,然后重复这个过程(图3)。
 图3. 两个代理之间的对话模拟
图3. 两个代理之间的对话模拟
-
Optimization
我们初始化了策略模型PRL,其参数来自上一小节描述的互信息模型。然后,我们使用策略梯度方法来寻找能够带来更大预期回报的参数。最大化的目标是预期的未来回报:
![J_{RL}\left ( \theta \right )=E_{p_{RL}\left ( a1:T \right )}\left [ \sum_{i=1}^{i=T}R\left ( a_{i},\left [ p_{i},q_{i} \right ] \right ) \right ]](http://img.e-com-net.com/image/info8/6bc7c77dd23f4e0e9ec9e2ddd6d975d9.gif)
我们使用似然比技巧来进行梯度更新:
![\bigtriangledown J_{RL}\left ( \theta \right )\approx \sum_{i=1} \bigtriangledown \log p\left ( a_{i}|p_{i},q_{i} \right )\sum_{i=1}^{i=T}R\left ( a_{i},\left [ p_{i},q_{i} \right ] \right ) \right](http://img.e-com-net.com/image/info8/9d3c52b42b8845f3bccb90c7ec7325e0.gif)
-
Curriculum Learning
再次采用课程学习策略,从模拟两轮对话开始,逐步增加模拟轮数。我们最多产生5个回合,因为要检查的候选人数量在候选名单的大小上呈指数增长。在仿真的每一步产生五个候选响应。
四、实验结果
在这一部分中,我们描述了实验结果和定性分析。我们使用人工判断和两种自动度量来评估对话生成系统:会话长度(整个会话中的回合数)和多样性。
Dataset
对话模拟需要高质量的初始输入到Agent。例如,初始输入“为什么?”这是不可取的,因为目前尚不清楚对话如何进行。我们从OpenSubtitle数据集中提取1000万条消息的子集,并提取出80万条序列,其生成响应“i don’t know what you are taking about”的可能性最低,以确保初始输入易于响应。
Automatic Evaluation
评估对话系统是困难的。BLEU和perplexity等指标被广泛用于对话质量评估,但人们广泛讨论了这些自动评估指标与真实响应质量之间的相关性。由于所提出的系统的目标不是预测最高概率的响应,而是对话的长期成功,所以我们不使用BLEU或perplexity来进行评估。
| Model | #Of simulated turns |
| SEQ2SEQ | 2.68 |
| mutual information | 3.40 |
| RL | 4.48 |
-
对话的长度
测试集由1000条输入消息组成。为了降低循环对话的风险,我们将模拟轮数限制在8以下。结果如表1所示。可以看到,使用相互信息模型导致两个agents之间更持久的对话。所提出的RL模型首先根据互信息目标进行训练,并从中受益。我们观察到,采用对话模拟的RL模型获得了最佳的评价结果。
-
多样性
我们通过计算生成的响应中不同的unigrams和bigrams来报告多样性程度。该值根据生成的字符总数进行缩放,以避免偏向长句子。因此,产生的度量是unigrams和bigrams的类型比率。
| Model | Unigrams | Bigrams |
| SEQ2SEQ | 0.0062 | 0.015 |
| mutual information | 0.011 | 0.031 |
| RL | 0.017 | 0.041 |
-
人类评估
| Setting | RL-win | RL-lose | Tie |
| single-turn general quality | 0.40 | 0.36 | 0.24 |
| single-turn ease to answer | 0.52 | 0.23 | 0.25 |
| multi-turn general quality | 0.72 | 0.12 | 0.16 |
-
定性分析与讨论
从表3中,我们可以看到基于RL的agent确实比其他基线生成更多的交互式响应(表4)。我们还发现,RL模型倾向于以另一个问题结束句子,并将会话交给用户。
| Input Message Mutual | Information | Model RL |
| How old are you? |
I’m 16. | I’m 16, why are you asking? |
| What’s your full name? |
I have no idea. | What’s yours? |
| I don’t want to go home tonight. |
Really? | Why? |
| Do you have any feelings for me? |
I don’t know what you are talking about. | I don’t want to hurt your feelings. |
| How much time do you have here? |
Not long enough. | Sorry, sir. Ten seconds. |
| Shall we get started? |
Of course! | Yes. We’ve got a lot of work to do here. |
| Do you play football? |
No, i don’t | Yes.I love football! |
| We’d have to talk to him. |
I mean, he’s a good guy | About what ? |
| How come you never say it? | Because I don’t want to hurt you. | I don’t think it’s a good idea to say it |
在错误分析中,我们发现尽管我们在连续的回合中惩罚重复的话语,但对话有时会进入一个长度大于1的周期,如图4所示。
我们认为这可以归因于有限的对话历史。观察到的另一个问题是,模型有时会在谈话中开始一个不太相关的话题。在相关性和较少的重复性之间有一种权衡。
 图4.出现重复的周期大于1的模拟对话
图4.出现重复的周期大于1的模拟对话
当然,最根本的问题是手动定义的奖励函数不可能涵盖定义理想会话的关键方面。理想情况下,这个系统会从人类那里得到真正的回报。当前模式的另一个问题是,我们只能探索一小部分候选回复和模拟转换。