情感分析背后的朴素贝叶斯及实现基于评论语料库的影评情感分析(附代码)
一.情感分析的介绍
一句话概括情感分析:判断出一句评价/点评/影评的正/负倾向性;
情感分析是一个二分类的问题,一种是可以直接判断正负,一种是可以判断情感偏向正负性的一个打分;
二,词袋模型(向量空间模型)
2.1情感分析的流程
中文分词处理,停用词的去除,对否定词做处理,情感分析方法主要可以分为两大类,基于词典的方法和机器学习方法。
把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度;
中文分词用于切割句子,卡方统计能够计算类别和特征项之间的i相关程度;
常见的分类机器学习算法包括:朴素贝叶斯分类器,SVM支持向量机,逻辑回归,j决策树等;
2.2词袋模型
给定一个长的文本,这样的段落虽然有顺序,但是它对于主题和情感的信息是不依赖于这个顺序的;也就是说给一个文本,我们的第一步是将这样的序列模型变为一个袋子,这样的袋子是一堆词,这个袋子中的词与词的顺序已经完全打乱;
词袋模型的实现->(向量空间模型)
例如:我非常喜欢《肖申克的救赎》->我/非常/喜欢/肖申克的救赎
先分词,再对词语的顺序进行打乱,怎么打乱呢?就是我们忽略哪个词出现在哪个词之前,我们只需要统计'我'这个词出现的次数,那么怎样在计算机中表示这个词呢,我们需要用一个1-hot的方式进行表示,所谓1-hot,指的是每一个词,实际上是对应计算机中的一个序号,叫做index,一个词对应于一个向量,当且仅当这个词的index对应为1。这样就可以将现实生活中的每一个词语映射为计算机里的每一个数字。通过一个加法运算对向量求和,最后得到一个文本向量,实际上就是这个文章中的词出现次数的一个统计;
将一个词典看作是一个高维的欧式空间,每一句话看作是这些奇向量的简单的线性组合,比如这里有n个词,那么我们的句子就是由这n个词组成的一个n维空间的向量。这个向量的维度,是和字典的大小的维度是一样的。
词袋模型应用:情感分析;文章主题分类;垃圾邮件过滤器;图像分类
1.忽略文章/评论中词语的顺序;
2.每个词对应空间中一个单位向量;
3.文章/评论是词语的加权总和;
三,基于朴素贝叶斯的情感分类器
1.贝叶斯公式介绍

假设知道事件B的结果,我们要更新事件A的结果的概率,这个概率我们将其称之为后验概率,为了,为了计算这个后验概率,我们可以先计算A发生的概率以及在A发生的情况下B发生的概率;
2.朴素贝叶斯分类器
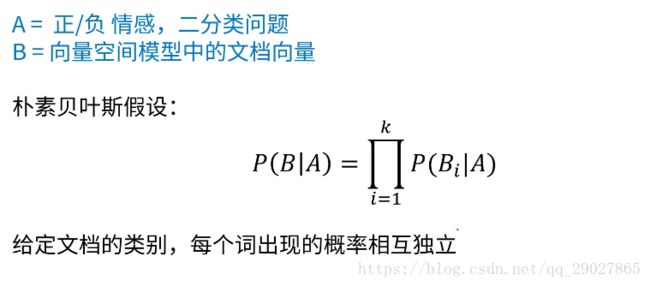
一旦给定了A的假设,也就是说我们知道了A发不发生,我们可以把B的概率分解成所有单独的B的概率的乘积;
通过条件独立假设,如果要来估计一篇文档正向的概率的话,我只要知道每一个词在正向文档中出现的概率,然后把所有的概率乘起来,就可以得到。
我们真正要计算的是一个后验概率,但我们要知道一个后验概率是正比于先验概率乘以似然函数。

现在我们解释下这个公式:我们首先通过贝叶斯公式得到第一步,第一个等式是我们的贝叶斯公式;第二步是因为现在我们要看A的概率,与B的概率没有关系,故近似等于;第三步是将刚才的概率分成小概率的乘积;
这个公式和两项有关:第一个东西是A本身的先验概率,第二个东西是每个词语在正负向文档中出现的概率;

注意:后两个加起来的概率并不为1,它们并不互补;因为它们所基于的条件不同,但是P(Bi=1|A=1)+P(Bi=0|A=1)=1

算法包括两部分:给定一个数据集,我们先估计这三个量:P(A=1),P(B_i=1|A=1),P(B_i=1|A=0),估计这三个量是为了统计,一旦我们拿到了这三个量后,我们只需要根据之前的贝叶斯公式来进行分类即可,即将三个量乘起来。
3.基于朴素贝叶斯的情感分类

常用工具包:SnowNLP(处理中文句子),NLTK;
基于评论集的情感分析代码实现:
import pandas as pd
from snownlp import SnowNLP
# 数据预处理
def pre_data(name):
train = pd.read_csv(name,encoding="gbk")
# 切分数据集
train_content = train["str"]
# 将dataframe的数据集转化为list类型
train_content = train_content.values.tolist()
return train,train_content
# 将情感打分存在列表
def mood_score(sentences):
Pos_score = []
for i in sentences:
sentence = str(i[0])
s = SnowNLP(sentence)
Pos_score.append(s.sentiments)
# 将列表转化为Series
Pos_score_test = pd.Series(Pos_score)
return Pos_score_test
# 保存为新的csv文件
def save_csv(new_name,list_new,df_test,csv_name):
df_test[str(new_name)] = list_new
df_test.to_csv(str(csv_name), encoding='utf_8_sig')
if __name__ == "__main__":
train,content = pre_data("big_V.csv")
pos_score = mood_score(content)
save_csv("pos_score",pos_score,train,"new_pos.csv")欢迎拍砖~