Tesseract-OCR从入门到精通之windows环境实现图片文字识别
1下载Tesseract-OCR
https://download.csdn.net/download/qq_29099209/10601927
https://download.csdn.net/download/qq_29099209/10601922
2测试是否可用
dos命令行识别图片

生成识别文件
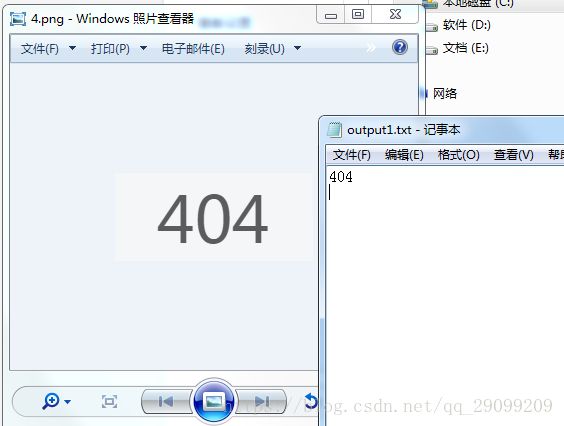
3:中文包
https://download.csdn.net/download/qq_29099209/10617419
进行图片识别
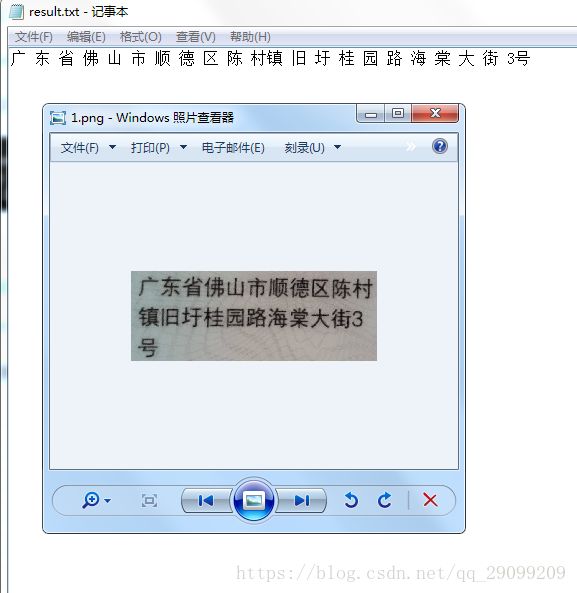
如果不想训练字体库 感觉可以设置图片边框进行裁剪识别,正确率提高很多
4下载训练识别工具
https://download.csdn.net/download/qq_29099209/10617639
打开可能会报错,需要下载一个JDK
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载成功应该就不会报错了
5将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把图片文件重命名 mjorcen.normal.exp0.jpg在转tif。
例如:mjorcen.normal.exp0.jpg
6生成box文件,box文件和对应的tif一定要在相同的目录下,不然后面打不开
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox7打开jTessBoxEditor矫正错误并训练
8点击open 选择刚才改名字的图片文件
改正错误的识别,点击delete把多余的删除掉即可,然后点击save进行保存
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 nobatch box.trainunicharset_extractor mjorcen.normal.exp0.box新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
![]()
![]()
shapeclustering -F font_properties -U unicharset mjorcen.normal.exp0.trmftraining -F font_properties -U unicharset -O unicharset mjorcen.normal.exp0.trcntraining mjorcen.normal.exp0.tr最后会生成五个文件,把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.
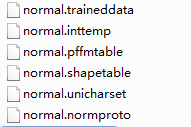
命令行输入,合并五个文件:
combine_tessdata normal.1、把 normal.traineddata 复制到Tesseract-OCR 安装目录下的tessdata文件夹中
2、识别命令:
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l normal效果:
![]()
还是有地方识别的不好,需要再多训练训练,也可能是删除了的原因,把原来识别多余的地方改成空白,与原来的库合并再试一次