hive数据处理及hdfs文件操作
写在前面:
本想使用hive调用python脚本实现统计分析movielens数据,但是最后一步调用脚本的地方不成功没找到问题所在,于是将过程中的一些经验写出来,非常详尽,对新手来说应该挺有用的。
另外调用脚本的程序和报错我会贴出来,应该是脚本写的有问题,后面找到问题或者有人告诉我我会更新。
还拿hive与movie lens数据说事儿。
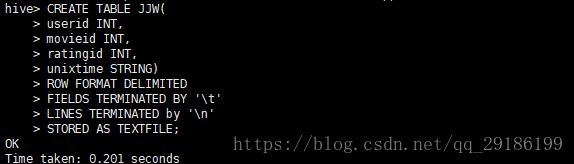
1、首先进入hive数据库创建基表:
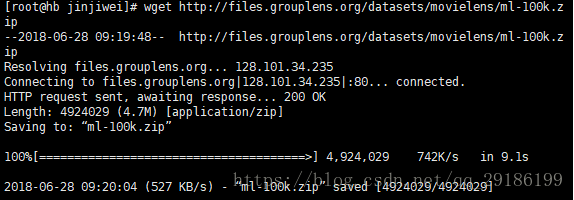
2、在linxu文件工作文件夹下下载数据资源并且解压,我的目录是opt/jskp/jinjiwei:
wget http://files.grouplens.org/datasets/movielens/ml-100k.zip

3、在hdfs上新建自己的工作文件夹,我的是hdfs dfs -mkdir 文件名(JJW)

4、将本地解压的文件上传到hdfs:
hdfs dfs -put /opt/jskp/jinjiwei/ml-100k /JJW(hdfs目录)在hdfs上面查看上传结果:

5、将ml-100k文件下的u.data文件加载到hive数据库前面建的基表JJW中:

可以看到我第一次加载文件路径是本地路径是错误的,第二次是hdfs上面路径,结果正确,下面验证加载结果:

可以在hive中及进行一些简单的统计如:

6、创建子表JJW_new,用于把基表JJW数据导入子表(因为我调用python脚本不成功,这里就直接导入了)
CREATE TABLE JJW_new (
userid INT,
movieid INT,
rating INT,
weekday INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
7、编写python脚本,功能仅仅将unix时间改为正常时间戳:
import sys
import datetime
for line in sys.stdin:
line = line.strip()
userid, movieid, rating, unixtime = line.split('\t')
weekday=datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([userid, movieid, rating, str(weekday)])8、添加本地python脚本如下图,路径为本地绝对路径:
![]()
9、最终不调用python脚本方法:
INSERT OVERWRITE TABLE JJW_new
SELECT
userid, movieid, ratingid, unixtime
FROM JJW;验证:

10、引用脚本方法:
INSERT OVERWRITE TABLE JJW_new
SELECT
TRANSFORM (userid, movieid, ratingid, unixtime)
USING 'python weekday_mapper.py'
AS (userid, movieid, rating, weekday)
FROM JJW;报错:
hive> INSERT OVERWRITE TABLE JJW_new
> SELECT
> TRANSFORM (userid, movieid, ratingid, unixtime)
> USING 'python tansform.py'
> AS (userid, movieid, rating, weekday)
> FROM JJW;
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1526968712310_2578, Tracking URL = http://hm:8088/proxy/application_1526968712310_2578/
Kill Command = /opt/software/hadoop/hadoop-2.6.4/bin/hadoop job -kill job_1526968712310_2578
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-06-28 13:00:12,907 Stage-1 map = 0%, reduce = 0%
2018-06-28 13:00:42,417 Stage-1 map = 100%, reduce = 0%
Ended Job = job_1526968712310_2578 with errors
Error during job, obtaining debugging information...
Examining task ID: task_1526968712310_2578_m_000000 (and more) from job job_1526968712310_2578
Task with the most failures(4):
-----
Task ID:
task_1526968712310_2578_m_000000
URL:
http://hm:8088/taskdetails.jsp?jobid=job_1526968712310_2578&tipid=task_1526968712310_2578_m_000000
-----
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row {"userid":47,"movieid":324,"ratingid":3,"unixtime":"879439078"}
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:195)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:450)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row {"userid":47,"movieid":324,"ratingid":3,"unixtime":"879439078"}
at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:550)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:177)
... 8 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: [Error 20001]: An error occurred while reading or writing to your custom script. It may have crashed with an error.
at org.apache.hadoop.hive.ql.exec.ScriptOperator.processOp(ScriptOperator.java:410)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:793)
at org.apache.hadoop.hive.ql.exec.SelectOperator.processOp(SelectOperator.java:87)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:793)
at org.apache.hadoop.hive.ql.exec.TableScanOperator.processOp(TableScanOperator.java:92)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:793)
at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:540)
... 9 more
Caused by: java.io.IOException: Stream closed
at java.lang.ProcessBuilder$NullOutputStream.write(ProcessBuilder.java:433)
at java.io.OutputStream.write(OutputStream.java:116)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:126)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.write(BufferedOutputStream.java:126)
at java.io.DataOutputStream.write(DataOutputStream.java:107)
at org.apache.hadoop.hive.ql.exec.TextRecordWriter.write(TextRecordWriter.java:53)
at org.apache.hadoop.hive.ql.exec.ScriptOperator.processOp(ScriptOperator.java:378)
... 15 more
FAILED: Execution Error, return code 20001 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. An error occurred while reading or writing to your custom script. It may have crashed with an error.
MapReduce Jobs Launched:
Job 0: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
11、使用到的命令总结一波:
本地数据加载到hive表(可覆盖表内容)
LOAD DATA LOCAL INPATH '/opt/jskp/jinjiwei/ml-100k/u.data’
OVERWRITE INTO TABLE jjw; 本地数据加载到hive表(不可覆盖表内容)
LOAD DATA INPATH '/opt/jskp/jinjiwei/ml-100k/u.data' INTO table testkv;本地数据上传到hdfs
hdfs dfs -put /opt/jskp/jinjiwei/ml-100k.zip /JJW修改hdfs的一个文件:
获取
hdfs dfs -get JJW/transform.py
修改
vi transform.py
上传
hdfs dfs -put -f test.txt yourHdfsPath/test.txt基本hadoop dfs与hdfs dfs可互换,后面跟的参数大多为linux命令,如hdfs dfs -ls , hdfs dfs -mkdir等。
另外hive与linux交互:可在hive环境下用!linux命令如!find等。
其他一些命令可以参考这里(不是我写的哦):HDFS 常用文件操作命令