吴恩达《序列模型》课程笔记(1)-- 循环神经网络(RNN)
序列模型 — 循环神经网络
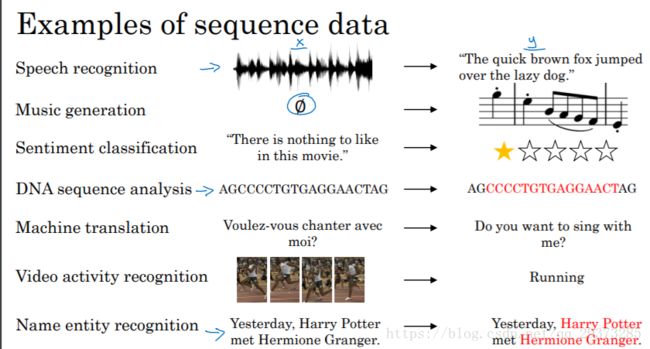
1. 序列模型的应用
序列模型能解决哪些激动人心的问题呢?
语音识别:将输入的语音信号直接输出相应的语音文本信息。无论是语音信号还是文本信息均是序列数据。
音乐生成:生成音乐乐谱。只有输出的音乐乐谱是序列数据,输入可以是空或者一个整数。
情感分类:将输入的评论句子转换为相应的等级或评分。输入是一个序列,输出则是一个单独的类别。
DNA序列分析:找到输入的DNA序列的蛋白质表达的子序列。
机器翻译:两种不同语言之间的想换转换。输入和输出均为序列数据。
视频行为识别:识别输入的视频帧序列中的人物行为。
命名实体识别:从输入的句子中识别实体的名字。
x和y可以只有一个是序列,也可以都是序列。
2. 数学符号
输入x:如“Harry Potter and Herminone Granger invented a new spell.”(以序列作为一个输入),![]() 表示输入x中的第t个符号。
表示输入x中的第t个符号。
输出y:如“1 1 0 1 1 0 0 0 0”(人名定位),同样,![]() 表示输出y中的第t个符号。
表示输出y中的第t个符号。
![]() 用来表示输入x的长度;
用来表示输入x的长度;
![]() 用来表示输出y的长度 ;
用来表示输出y的长度 ;
![]() 表示第i个输入样本的第t个符号,其余同理。
表示第i个输入样本的第t个符号,其余同理。
利用单词字典编码来表示每一个输入的符号:如one-hot编码等,实现输入x和输出y之间的映射关系。

3. 循环神经网络模型
传统标准的神经网络:
对于学习X和Y的映射,我们可以很直接的想到一种方法就是使用传统的标准神经网络。也许我们可以将输入的序列X以某种方式进行字典编码以后,如one-hot编码,输入到一个多层的深度神经网络中,最后得到对应的输出Y。如下图所示:
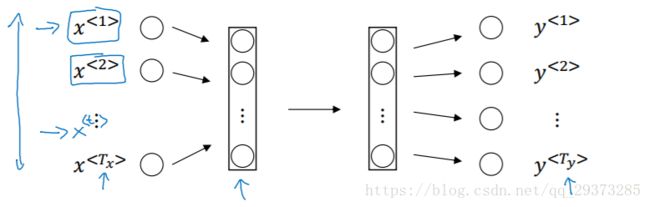
但是,结果表明这种方法并不好,主要是存在下面两个问题:
-
输入和输出数据在不同的例子中可以有不同的长度;
-
这种朴素的神经网络结果并不能共享从文本不同位置(如在序列1或者其他序列位置)所学习到的特征。(如卷积神经网络中学到的特征的快速地推广到图片其他位置)
*循环神经网络:
循环神经网络作为一种新型的网络结构,在处理序列数据问题上则不存在上面的两个缺点。在每一个时间步中,循环神经网络会传递一个激活值到下一个时间步中,用于下一时间步的计算。如下图所示:

这里需要注意在零时刻,我们需要编造一个激活值,通常输入一个零向量,有的研究人员会使用随机的方法对该初始激活向量进行初始化。同时,上图中右边的循环神经网络的绘制结构与左边是等价的。
循环神经网络是从左到右扫描数据的,同时共享每个时间步的参数。 如在上面的循环神经网络中,预测y<3>时,用的不仅是x<3>,还要使用x<1>和 x<2>的信息。
管理从输入x<t>到隐藏层的连接,每个时间步都使用相同的Wax,同下;Waa管理激活值a<t>到隐藏层的连接;Wya管理隐藏层到激活值y<t>的连接。
上述循环神经网络结构的缺点:每个预测输出y<t>仅使用了前面的输入信息,而没有使用后面的信息。Bidirectional RNN(双向循环神经网络)可以解决这种存在的缺点。
循环神经网络的前向传播:
下图是循环神经网络结构图:
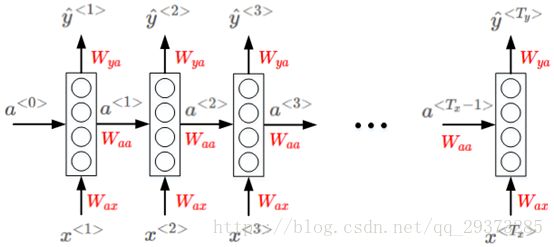
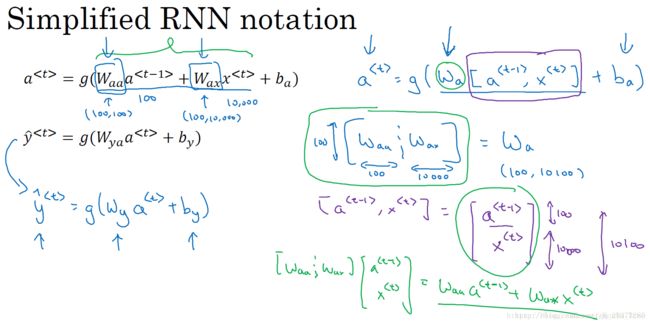
RNN模型包含三类权重系数,分别是 Wax ,Waa , Wya 且不同元素之间同一位置共享同一权重系数。

RNN的正向传播(Forward Propagation)过程为:
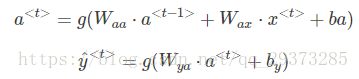
其中,g(⋅)表示激活函数,不同的问题需要使用不同的激活函数。
为了简化表达式,可以对![]() 项进行整合:
项进行整合:
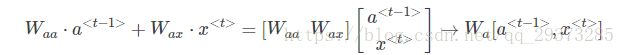
则正向传播可表示为:
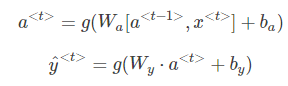
值得一提的是,以上所述的RNN为单向RNN,即按照从左到右顺序,单向进行,![]() 只与左边的元素有关。但是,有时候
只与左边的元素有关。但是,有时候![]() 也可能与右边元素有关。例如下面两个句子中,单凭前三个单词,无法确定“Teddy”是否为人名,必须根据右边单词进行判断。
也可能与右边元素有关。例如下面两个句子中,单凭前三个单词,无法确定“Teddy”是否为人名,必须根据右边单词进行判断。
He said, “Teddy Roosevelt was a great President.”
He said, “Teddy bears are on sale!”
因此,有另外一种RNN结构是双向RNN,简称为BRNN。y^
4. 通过时间的反向传播
为了进行反向传播计算,使用梯度下降等方法来更新RNN的参数,我们需要定义一个损失函数, 单个元素的损失函数如下:
![]()
该样本所有元素的损失函数为(对每个时间步求和):

反向传播(Backpropagation)过程就是从右到左分别计![]() 对参数Wa,Wy,ba,by的偏导数。思路与做法与标准的神经网络是一样的。一般可以通过成熟的深度学习框架自动求导,例如PyTorch、Tensorflow等。
对参数Wa,Wy,ba,by的偏导数。思路与做法与标准的神经网络是一样的。一般可以通过成熟的深度学习框架自动求导,例如PyTorch、Tensorflow等。
________________________________________________________________________
5. 不同类型的RNN
对于RNN,不同的问题需要不同的输入输出结构。
many-to-many ![]() 和
和![]()
这种情况下的输入和输出的长度相同,是上面例子的结构,如下图所示:
我们上面介绍的一种RNN的结构是输入和输出序列的长度是相同的,但是像机器翻译这种类似的应用来说,输入和输出都是序列,但长度却不相同,这是另外一种多对多的结构:
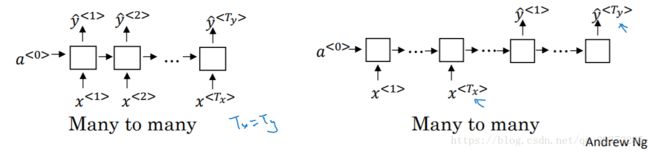
many-to-one:![]()
如在情感分类问题中,我们要对某个序列进行正负判别或者打星操作。在这种情况下,就是输入是一个序列,但输出只有一个值:
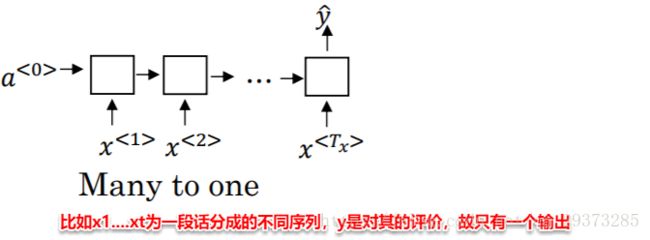
one-to-many:![]()
如在音乐生成的例子中,输入一个音乐的类型或者空值,直接生成一段音乐序列或者音符序列。在这种情况下,就是输入是一个值,但输出是一个序列:

6. 语言模型和序列生成
在NLP中,构建语言模型是最基础也是最重要的工作之一,我们可以通过RNN来很好的实现。
什么是语言模型?
对于下面的例子,两句话有相似的发音,但是想表达的意义和正确性却不相同,如何让我们的构建的语音识别系统能够输出正确地给出想要的输出。也就是对于语言模型来说,从输入的句子中,评估各个句子中各个单词出现的可能性,进而给出整个句子出现的可能性。

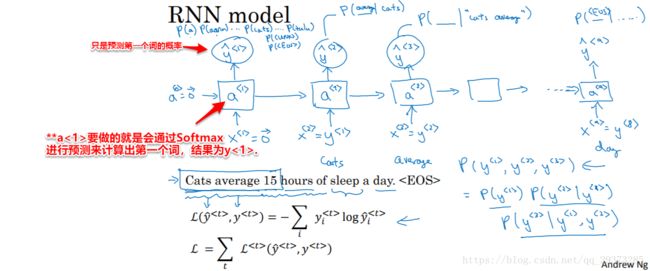
使用RNN构建语言模型:(通过几个词预测后面的词)
训练集:一个很大的语言文本语料库;

Tokenize:将句子使用字典库标记化;其中,未出现在字典库中的词使用“UNK”来表示;
第一步:使用零向量对输出进行预测,即预测第一个单词是某个单词的可能性;
第二步:通过前面的输入,逐步预测后面一个单词出现的概率;
训练网络:使用softmax损失函数计算损失,对网络进行参数更新,提升语言模型的准确率。
7. 新序列采样
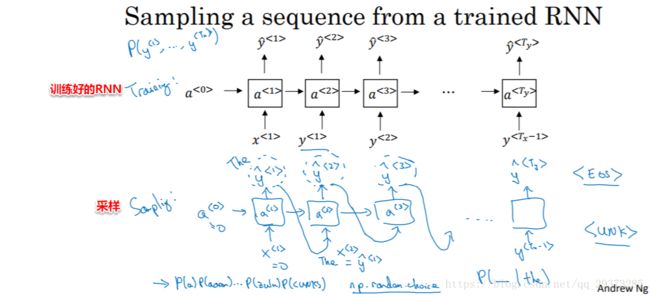
在完成一个序列模型的训练之后,如果我们想要了解这个模型学到了什么,其中一种非正式的方法就是进行一次新序列采样(sample novel sequences)。
对于一个序列模型,其模拟了任意特定单词序列的概率,如P(y<1>,⋯,y<Ty>),而我们要做的就是对这个概率分布进行采样,来生成一个新的单词序列。 如下面的一个已经训练好的RNN结构,我们为了进行采样需要做的:首x<1>=0,a<0>=0,在这第一个时间步,我们得到所有可能的输出经过softmax层后可能的概率,根据这个softmax的分布,进行随机采样,获取第一个随机采样单词y^<1>;然后继续下一个时间步,我们以刚刚采样得到的y^<1>作为下一个时间步的输入,进而softmax层会预测下一个输出y^<2>,依次类推;如果字典中有结束的标志如:“EOS”,那么输出是该符号时则表示结束;若没有这种标志,则我们可以自行设置结束的时间步。
上面的模型是基于词汇的语言模型,我们还可以构建基于字符的语言模型,其中每个单词和符号则表示一个相应的输入或者输出:
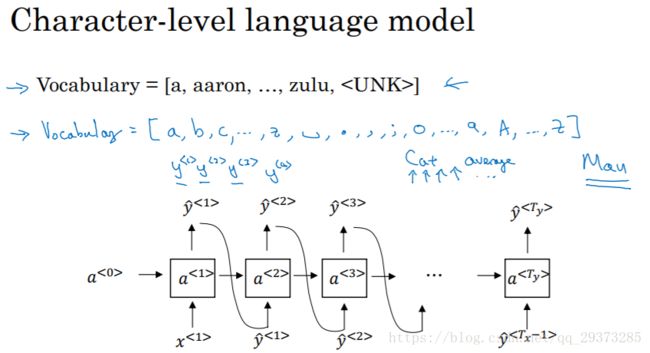
但是基于字符的语言模型,一个主要的缺点就是我们最后会得到太多太长的输出序列,其对于捕捉句子前后依赖关系,也就是句子前部分如何影响后面部分,不如基于词汇的语言模型那样效果好;同时基于字符的语言模型训练代价比较高。所以目前的趋势和常见的均是基于词汇的语言模型。但随着计算机运算能力的增强,在一些特定的情况下,也会开始使用基于字符的语言模型。
8. RNN的梯度消失
RNN在NLP中具有很大的应用价值,但是其存在一个很大的缺陷,那就是梯度消失的问题。例如下面的例句中:
The cat, which already ate ………..,was full;
The cats, which already ate ………..,were full.
在这两个句子中,cat对应着was,cats对应着were,(中间存在很多很长省略的单词),句子中存在长期依赖(long-term dependencies),前面的单词对后面的单词有很重要的影响。但是我们目前所见到的基本的RNN模型,是不擅长捕获这种长期依赖关系的。
如下图所示,和基本的深度神经网络结构类似,输出y得到的梯度很难通过反向传播再传播回去,也就是很难对前面几层的权重产生影响,所以RNN也有同样的问题,也就是很难让网络记住前面的单词是单数或者复数,进而对后面的输出产生影响。 (即因为梯度消失的问题,反向传播很困难,后面的层很难影响前面的层)
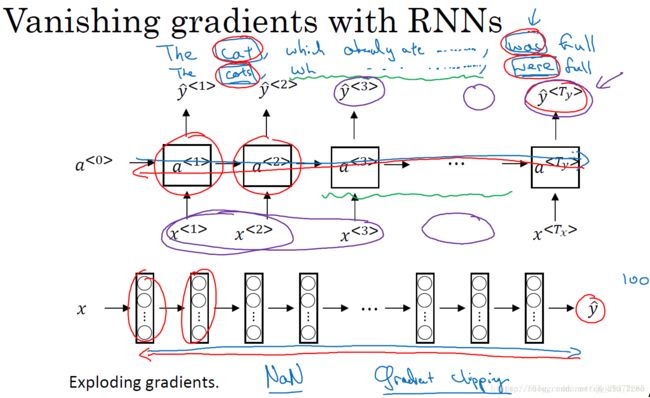
对于梯度消失问题,在RNN的结构中是我们首要关心的问题,也更难解决;虽然梯度爆炸(网络越深梯度不仅会指数下降也可能会指数上升的问题)在RNN中也会出现,但对于梯度爆炸问题,因为参数会指数级的梯度,会让我们的网络参数变得很大,得到很多的Nan或者数值溢出。
所以梯度爆炸是很容易发现的(反而梯度消失比较棘手),我们的解决方法就是用梯度修剪,也就是观察梯度向量,如果其大于某个阈值,则对其进行缩放,保证它不会太大。
9. GRU单元
门控循环单元(Gated Recurrent Unit, GRU)改变了RNN的隐藏层,使其能够更好地捕捉深层次连接,并改善了梯度消失的问题。
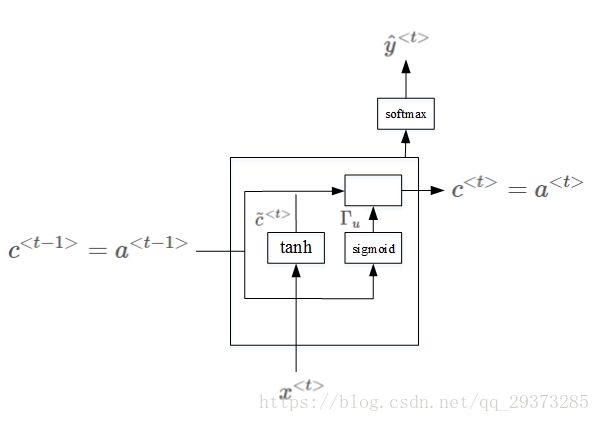
RNN 单元:
对于RNN的一个时间步的计算单元(RNN隐藏单元的可视化呈现),在计算![]() 也就是下图右边的公式,能以左图的形式可视化呈现:
也就是下图右边的公式,能以左图的形式可视化呈现:

![]()
简化的GRU 单元:
我们以时间步从左到右进行计算的时候,在GRU单元中,存在一个新的变量称为c,(代表cell),作为“记忆细胞”,其提供了长期的记忆能力。

GRU的可视化实现如下图右边所示:
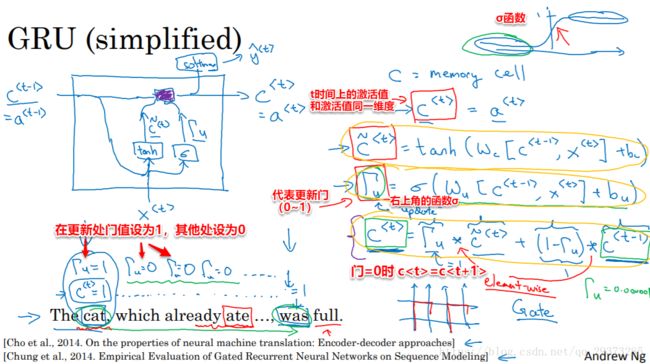
门的作用是决定什么时候去更新这个![]() (当看到cats的时候更新,后面就不管了 )
(当看到cats的时候更新,后面就不管了 )
当门=0时,![]() =
=![]() 。
。
完整的GRU 单元:(视觉门和相关门)
完整的GRU单元还存在另外一个门,以决定每个时间步的候选值,公式如下:

10. LSTM
GRU能够让我们在序列中学习到更深的联系,长短期记忆(long short-term memory, LSTM)对捕捉序列中更深层次的联系要比GRU更加有效。LSTM中,使用了单独的更新门Γu和遗忘门Γf,以及一个输出门Γo,其主要的公式如下:

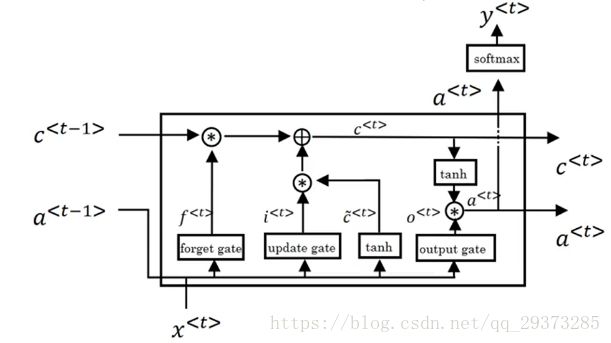
LSTM单元的可视化图如下所示:
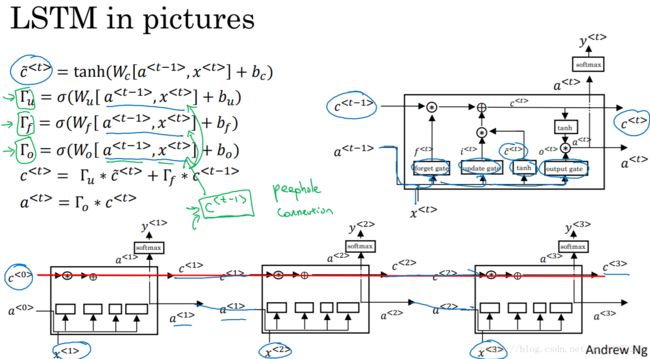
其中,在实际使用时,几个门值不仅仅取决于![]() 和
和 ![]() ,还可能会取决于上一个记忆细胞的值
,还可能会取决于上一个记忆细胞的值![]() ,这也叫做偷窥孔连接。
,这也叫做偷窥孔连接。
11. 双向RNN (可以用于STML和GRU)
双向RNN(bidirectional RNNs)模型能够让我们在序列的某处,不仅可以获取之间的信息,还可以获取未来的信息。
对于下图的单向RNN的例子中,无论我们的RNN单元是基本的RNN单元,还是GRU,或者LSTM单元,对于下面例子中第三个单词”Teddy”很难判断是否是人名,仅仅使用前面的两个单词是不够的,需要后面的信息来进行判断,但是单向RNN就无法实现获取未来的信息。
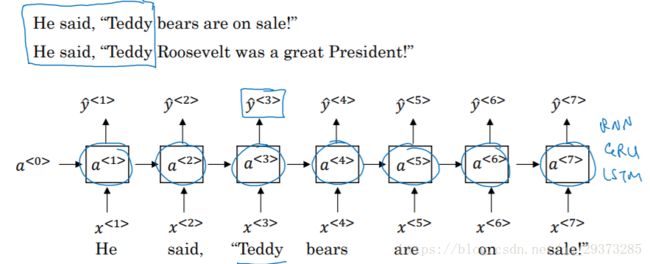
而双向RNN则可以解决单向RNN存在的弊端。在BRNN中,不仅有从左向右的前向连接层,还存在一个从右向左的反向连接层。
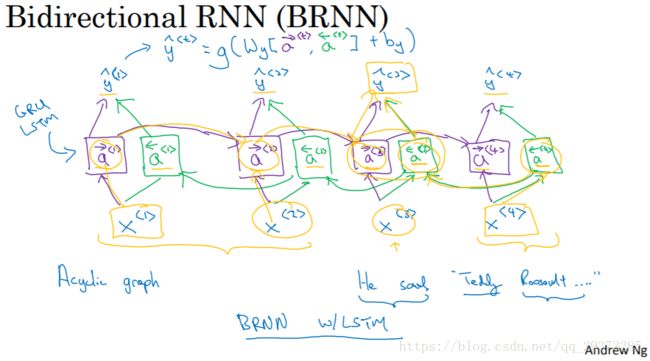
其中,预测输出的值:
![]()
预测结果即有前向的信息,又有反向的信息。在NLP问题中,常用的就是使用双向RNN的LSTM。
双向RNN的缺点是你需要完整的数据的序列。比如识别语音,你要说完一段语音才能识别,这就是缺点。
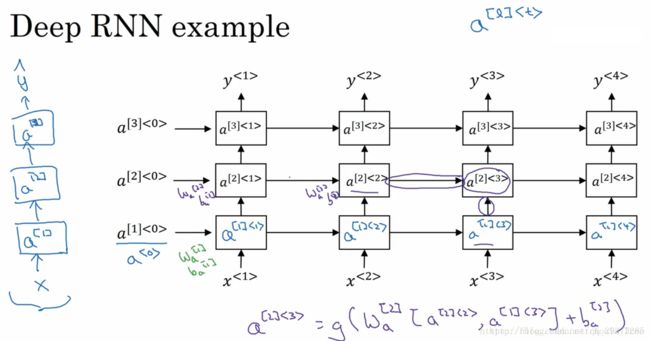
12. 深层RNNs
与深层的基本神经网络结构相似,深层RNNs模型具有多层的循环结构,但不同的是,在传统的神经网络中,我们可能会拥有很多层,几十层上百层,但是对与RNN来说,三层的网络结构就已经很多了,因为RNN存在时间的维度,所以其结构已经足够的庞大。如下图所示: