强化学习中的各类算法
现有的强化学习主要分为五种:
通过价值选行为:Q-learning、Sarsa、Deep Q Network
直接选行为:Policy Gradients
想象环境并从中学习:Model Based RL
回合更新:基础版的Policy Gradients、Monte-Carlo Learning
单步更新:Q Learning、Sarsa、升级版Policy Gradients
一、Q-Learning

见参考:
https://baijiahao.baidu.com/s?id=1597978859962737001&wfr=spider&for=pc
https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
二、Sarsa
Sarsa具体算法请参考:https://www.baidu.com/link?url=Zd0LKnHffGIji4K9d1rjkxV7mJCOs5uedgabr2x8OLAm-dAa9X1A6FcslSIGwizh8L7vG7jqR9sFuBNLVpH8IrMhfryLHN7wzVw6E0qD-8u&wd=&eqid=abc3e6ec0000a45b000000035bbb0446
三、Sarsa(λ)
Sarsa(λ)具体算法请参考:
https://www.baidu.com/link?url=af1_fWwkNQoUsHn7HyPfxYSSC6msInuG00pgshZhXNXKiHAeMb5tLzf3RN81z-a_KWdbD9i5jq8JqWyewGJh6myp6bzYHxxZKwNKYNlnzKW&wd=&eqid=a85a1423000092ce000000035bbb0c41
四、DQN算法
DQN算法提出的背景,当Q-Table非常之大时,此时像Q-learning那样建立表格已不再合适,是不是有一种可以比较方便直接输出动作或Q值的机制呢?答案当然是有的,这就是DQN。
DQN的思想主要有以下几种:根据状态+动作输出动作的Q值,并选择Q值最大的作为下一步的动作;根据状态直接输出每种动作的Q值,并根据Q值大小来决定下一步将要进行的动作。
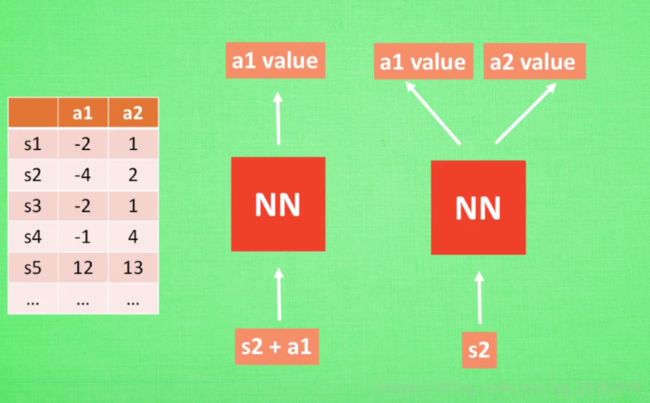
更详细内容请参考:https://blog.csdn.net/u013236946/article/details/72871858
五、Policy Grandients
什么是 Policy Gradients
其实策略梯度的基本思想,就是直接根据状态输出动作或者动作的概率。那么怎么输出呢,最简单的就是使用神经网络啦!
我们使用神经网络输入当前的状态,网络就可以输出我们在这个状态下采取每个动作的概率,那么网络应该如何训练来实现最终的收敛呢?
我们之前在训练神经网络时,使用最多的方法就是反向传播算法,我们需要一个误差函数,通过梯度下降来使我们的损失最小。但对于强化学习来说,我们不知道动作的正确与否,只能通过奖励值来判断这个动作的相对好坏。基于上面的想法,我们有个非常简单的想法:
如果一个动作得到的reward多,那么我们就使其出现的概率增加,如果一个动作得到的reward少,我们就使其出现的概率减小。
根据这个思想,我们构造如下的损失函数:loss= -log(prob)*vt
我们简单用白话介绍一下上面这个损失函数的合理性,那么至于从数学角度上为什么要使用上面的损失函数,可以参考:Why we consider log likelihood instead of Likelihood in Gaussian Distribution。
上式中log(prob)表示在状态 s 对所选动作 a 的吃惊度, 如果概率越小, 反向的log(prob) 反而越大. 而vt代表的是当前状态s下采取动作a所能得到的奖励,这是当前的奖励和未来奖励的贴现值的求和。也就是说,我们的策略梯度算法必须要完成一个完整的eposide才可以进行参数更新,而不是像值方法那样,每一个(s,a,r,s’)都可以进行参数更新。如果在prob很小的情况下, 得到了一个大的Reward, 也就是大的vt, 那么-log(prob)*vt就更大, 表示更吃惊, (我选了一个不常选的动作, 却发现原来它能得到了一个好的 reward, 那我就得对我这次的参数进行一个大幅修改)。
这就是 -log(prob)*vt的物理意义啦.Policy Gradient的核心思想是更新参数时有两个考虑:如果这个回合选择某一动作,下一回合选择该动作的概率大一些,然后再看奖惩值,如果奖惩是正的,那么会放大这个动作的概率,如果奖惩是负的,就会减小该动作的概率。
策略梯度的过程如下图所示:

我们在介绍代码实战之前,最后在强调Policy Gradient的一些细节:
- 算法输出的是动作的概率,而不是Q值。
- 损失函数的形式为:loss= -log(prob)*vt。
- 需要一次完整的episode才可以进行参数的更新。
6、Actor-Critic
基本思想和Policy Grandients相同,但是Actor Critic可以进行单步更新/实时更新。
结合了Policy Gradient(Actor)和Function Approximation(Critic)的方法。Actor基于概率选行为,Critic基于Actor的行为评判行为的得分,Actor根据Critic的评分修改选行为的概率。
Actor Critic方法的优势:可以进行单步更新,比传统的Policy Gradient更新速度快。
Actor Critic方法的劣势:取决于Critic的价值判断,但是Critic难收敛,再加上Actor就更难收敛。
7、DDPG算法
其优势表现在,相比于Actor-Critic算法,更容易进行实时更新。
8、AC3算法
采用的是Actor-Critic算法,只是在此基础上,训练了三个网络,这三个网络各自学习,最终都会对决策产生影响。现有的计算机大多是多核处理器,这样就可以把这三个网络放到不同的核中,分别进行训练,效率比较高,要比传统的方式快了许多倍。在python中是通过多线程来完成。