python训练mask rcnn模型&&C++调用训练好的模型--基于opencv4.0(干货满满)
介绍
我的第一篇关于mask rcnn训练自己数据的博文,基于python代码,虽然可以跑,但是不能真正用到工程领域中,工程领域更多的是基于C++和C,如果编译tensorflow C++ API也是可以,然后利用api调用模型,但是会比较麻烦,自己也尝试过,不是那么友好。
opencv4.0,终于等到你~~~,opencv4.0已经支持mask rcnn的调用,只需要.pb文件和.pbtxt文件即可进行推理,注意,现在opencv还不支持训练深度学习模型,不过很期待这一天的到来!同时,google推出的object detection api也支持mask rcnn的训练了,这款api支持.pb和.pbtxt文件的生成,正好可以传给opencv使用,这两家怕是在一起合作的吧。
本文就是基于object detection api对mask rcnn进行训练,然后使用opencv调用,完成从python到C++的转换。
训练数据
训练数据的制作,是通过labelme,这个工具我就不多介绍了,网上很多,我上一篇mask rcnn博客上也有,对图像进行处理,最终会生成json文件。
和上篇博文不同,这里只需要原图像和对应的json文件,因为object detection api需要tfrecords格式的训练数据,因此需要把json文件转换成tfrecords文件。当然了,这里有转换代码。
其中data.pbtxt文件,格式如下,有几种类别就写几种。
item {
id: 1
name: 'tank'
}
item {
id: 2
name: 'white'
}
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun Aug 26 10:57:09 2018
@author: shirhe-lyh
"""
"""Convert raw dataset to TFRecord for object_detection.
Please note that this tool only applies to labelme's annotations(json file).
Example usage:
python3 create_tf_record.py \
--images_dir=your absolute path to read images.
--annotations_json_dir=your path to annotaion json files.
--label_map_path=your path to label_map.pbtxt
--output_path=your path to write .record.
"""
import cv2
import glob
import hashlib
import io
import json
import numpy as np
import os
import PIL.Image
import tensorflow as tf
import read_pbtxt_file
flags = tf.app.flags
flags.DEFINE_string('images_dir', default='train_data/mask_data/train/images',help='')
flags.DEFINE_string('annotations_json_dir', 'train_data/mask_data/train/json',
help='')
flags.DEFINE_string('label_map_path',default='train_data/mask_data/data.pbtxt',help='')
flags.DEFINE_string('output_path', default='train_data/mask_data/train/tf_record/train.record', help='')
FLAGS = flags.FLAGS
def int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def int64_list_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def bytes_list_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=value))
def float_list_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def create_tf_example(annotation_dict, label_map_dict=None):
"""Converts image and annotations to a tf.Example proto.
Args:
annotation_dict: A dictionary containing the following keys:
['height', 'width', 'filename', 'sha256_key', 'encoded_jpg',
'format', 'xmins', 'xmaxs', 'ymins', 'ymaxs', 'masks',
'class_names'].
label_map_dict: A dictionary maping class_names to indices.
Returns:
example: The converted tf.Example.
Raises:
ValueError: If label_map_dict is None or is not containing a class_name.
"""
if annotation_dict is None:
return None
if label_map_dict is None:
raise ValueError('`label_map_dict` is None')
height = annotation_dict.get('height', None)
width = annotation_dict.get('width', None)
filename = annotation_dict.get('filename', None)
sha256_key = annotation_dict.get('sha256_key', None)
encoded_jpg = annotation_dict.get('encoded_jpg', None)
image_format = annotation_dict.get('format', None)
xmins = annotation_dict.get('xmins', None)
xmaxs = annotation_dict.get('xmaxs', None)
ymins = annotation_dict.get('ymins', None)
ymaxs = annotation_dict.get('ymaxs', None)
masks = annotation_dict.get('masks', None)
class_names = annotation_dict.get('class_names', None)
labels = []
for class_name in class_names:
label = label_map_dict.get(class_name, None)
if label is None:
raise ValueError('`label_map_dict` is not containing {}.'.format(
class_name))
labels.append(label)
encoded_masks = []
for mask in masks:
pil_image = PIL.Image.fromarray(mask.astype(np.uint8))
output_io = io.BytesIO()
pil_image.save(output_io, format='PNG')
encoded_masks.append(output_io.getvalue())
feature_dict = {
'image/height': int64_feature(height),
'image/width': int64_feature(width),
'image/filename': bytes_feature(filename.encode('utf8')),
'image/source_id': bytes_feature(filename.encode('utf8')),
'image/key/sha256': bytes_feature(sha256_key.encode('utf8')),
'image/encoded': bytes_feature(encoded_jpg),
'image/format': bytes_feature(image_format.encode('utf8')),
'image/object/bbox/xmin': float_list_feature(xmins),
'image/object/bbox/xmax': float_list_feature(xmaxs),
'image/object/bbox/ymin': float_list_feature(ymins),
'image/object/bbox/ymax': float_list_feature(ymaxs),
'image/object/mask': bytes_list_feature(encoded_masks),
'image/object/class/label': int64_list_feature(labels)}
example = tf.train.Example(features=tf.train.Features(
feature=feature_dict))
return example
def _get_annotation_dict(images_dir, annotation_json_path):
"""Get boundingboxes and masks.
Args:
images_dir: Path to images directory.
annotation_json_path: Path to annotated json file corresponding to
the image. The json file annotated by labelme with keys:
['lineColor', 'imageData', 'fillColor', 'imagePath', 'shapes',
'flags'].
Returns:
annotation_dict: A dictionary containing the following keys:
['height', 'width', 'filename', 'sha256_key', 'encoded_jpg',
'format', 'xmins', 'xmaxs', 'ymins', 'ymaxs', 'masks',
'class_names'].
#
# Raises:
# ValueError: If images_dir or annotation_json_path is not exist.
"""
# if not os.path.exists(images_dir):
# raise ValueError('`images_dir` is not exist.')
#
# if not os.path.exists(annotation_json_path):
# raise ValueError('`annotation_json_path` is not exist.')
if (not os.path.exists(images_dir) or
not os.path.exists(annotation_json_path)):
return None
with open(annotation_json_path, 'r') as f:
json_text = json.load(f)
shapes = json_text.get('shapes', None)
if shapes is None:
return None
image_relative_path = json_text.get('imagePath', None)
if image_relative_path is None:
return None
image_name = image_relative_path.split('/')[-1]
image_path = os.path.join(images_dir, image_name)
image_format = image_name.split('.')[-1].replace('jpg', 'jpeg')
if not os.path.exists(image_path):
return None
with tf.gfile.GFile(image_path, 'rb') as fid:
encoded_jpg = fid.read()
image = cv2.imread(image_path)
height = image.shape[0]
width = image.shape[1]
key = hashlib.sha256(encoded_jpg).hexdigest()
xmins = []
xmaxs = []
ymins = []
ymaxs = []
masks = []
class_names = []
hole_polygons = []
for mark in shapes:
class_name = mark.get('label')
class_names.append(class_name)
polygon = mark.get('points')
polygon = np.array(polygon)
if class_name == 'hole':
hole_polygons.append(polygon)
else:
mask = np.zeros(image.shape[:2])
cv2.fillPoly(mask, [polygon], 1)
masks.append(mask)
# Boundingbox
x = polygon[:, 0]
y = polygon[:, 1]
xmin = np.min(x)
xmax = np.max(x)
ymin = np.min(y)
ymax = np.max(y)
xmins.append(float(xmin) / width)
xmaxs.append(float(xmax) / width)
ymins.append(float(ymin) / height)
ymaxs.append(float(ymax) / height)
# Remove holes in mask
for mask in masks:
mask = cv2.fillPoly(mask, hole_polygons, 0)
annotation_dict = {'height': height,
'width': width,
'filename': image_name,
'sha256_key': key,
'encoded_jpg': encoded_jpg,
'format': image_format,
'xmins': xmins,
'xmaxs': xmaxs,
'ymins': ymins,
'ymaxs': ymaxs,
'masks': masks,
'class_names': class_names}
return annotation_dict
def main(_):
if not os.path.exists(FLAGS.images_dir):
raise ValueError('`images_dir` is not exist.')
if not os.path.exists(FLAGS.annotations_json_dir):
raise ValueError('`annotations_json_dir` is not exist.')
if not os.path.exists(FLAGS.label_map_path):
raise ValueError('`label_map_path` is not exist.')
label_map = read_pbtxt_file.get_label_map_dict(FLAGS.label_map_path)
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
num_annotations_skiped = 0
annotations_json_path = os.path.join(FLAGS.annotations_json_dir, '*.json')
for i, annotation_file in enumerate(glob.glob(annotations_json_path)):
if i % 100 == 0:
print('On image %d', i)
annotation_dict = _get_annotation_dict(
FLAGS.images_dir, annotation_file)
if annotation_dict is None:
num_annotations_skiped += 1
continue
tf_example = create_tf_example(annotation_dict, label_map)
writer.write(tf_example.SerializeToString())
print('Successfully created TFRecord to {}.'.format(FLAGS.output_path))
if __name__ == '__main__':
tf.app.run()
这时就生成了train.record和test.record文件。该代码需要read_pbtxt_file文件,下载链接:read_pbtxt_file.py,下载好之后放到同级目录即可。
Object Detection Api-mask rcnn训练自己的数据
关于如何使用mask rcnn训练自己的数据请参考我上一篇博文:object detection api SSD训练自己的数据,在这里再简单说下,主要做两件事,第一就是下载 mask_rcnn_inception_v2_coco模型,里面包含.pb模型。
下载完成之后,到object_detection文件夹下面找到samples\configs\mask_rcnn_inception_v2_coco.config文件,在其中修改:
model {
faster_rcnn {
num_classes: 2 #改成自己的类别数,有几种就写几
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 512 #这里不能设置太大,否则会报内存已满的错误
max_dimension: 512
}
训练参数可以修改,也可以不修改,调参试试看。
train_config: {
batch_size: 1
optimizer {
momentum_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: 0.0002
schedule {
step: 900000
learning_rate: .00002
}
schedule {
step: 1200000
learning_rate: .000002
}
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
设置初始参数的路径,也就是下载好的模型~
gradient_clipping_by_norm: 10.0
fine_tune_checkpoint: "model_zoo/mask_rcnn_inception_v2_coco_2018_01_28/model.ckpt"
from_detection_checkpoint: true
配置好train.record和test.record,data.pbtxt上面有说过,是自己建立的。
train_input_reader: {
tf_record_input_reader {
input_path: "train_data/mask_data/train/tf_record/train.record"
}
label_map_path: "train_data/mask_data/data.pbtxt"
load_instance_masks: true
mask_type: PNG_MASKS
}
eval_config: {
num_examples: 60
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "train_data/mask_data/test/tf_record/test.record"
}
label_map_path: "train_data/mask_data/data.pbtxt"
load_instance_masks: true
mask_type: PNG_MASKS
shuffle: false
num_readers: 1
}
配置好之后就可以训练了~
训练
训练时使用train.py文件,在legacy文件夹中,拿出来就好,放在与legacy文件夹同级目录中。关于train.py文件需要修改以下位置:
flags.DEFINE_string('train_dir', 'training_data/mask/',
'Directory to save the checkpoints and training summaries.')
flags.DEFINE_string('pipeline_config_path', 'samples/configs/mask_rcnn_inception_v2_coco.config',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file. If provided, other configs are ignored')
其中:'train_dir’是训练模型保存的路径,'pipeline_config_path’是mask_rcnn_inception_v2_coco.config配置文件的路径。
接着运行,开始训练~~~
训练结束后需要把model.ckpt文件转换为.pb文件,这时需要用到export_inference_graph.py文件,需要修改以下位置:
flags.DEFINE_string('pipeline_config_path', 'samples/configs/mask_rcnn_inception_v2_coco.config',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file.')
flags.DEFINE_string('trained_checkpoint_prefix', 'training_data/mask/model.ckpt-13798',
'Path to trained checkpoint, typically of the form '
'path/to/model.ckpt')
flags.DEFINE_string('output_directory', 'pd_model/mask_rcnn_inception_v2_coco', 'Path to write outputs.')
其中:'trained_checkpoint_prefix’是训练后保存的模型,选择最好的那个,'output_directory’是输出.pb模型的路径,pipline_config_path是mask_rcnn_inception_v2_coco.config文件。

当生成.pb文件之后,还需要生成.pbtxt文件,opencv中sources/samples包含dnn模块,里面有转换代码,这里直接给出 dnn下载链接。下载之后,放到train.py文件的同级目录下,其中的tf_text_graph_mask_rcnn.py文件可以生成.pbtxt文件。
parser.add_argument('--input', default='F:/tensorflow_object_detection/object_detection_12_29/pd_model/mask_rcnn_inception_v2_coco/frozen_inference_graph.pb', help='Path to frozen TensorFlow graph.')
parser.add_argument('--output', default='F:/tensorflow_object_detection/object_detection_12_29/pd_model/mask_rcnn_inception_v2_coco/mask_rcnn.pbtxt', help='Path to output text graph.')
parser.add_argument('--config', default='F:/tensorflow_object_detection/object_detection_12_29/samples/configs/mask_rcnn_inception_v2_coco.config', help='Path to a *.config file is used for training.')
args = parser.parse_args()
其中:input是转换后的.pb模型,output是输出的.pbtxt文件,config还是那个配置文件。当生成.pbtxt文件之后,就可以使用opencv4.0调用了~
opencv调用mask rcnn模型
这一步就完成了从python到C++的转换。好了先上源代码吧~
#include
#include
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace dnn;
using namespace std;
// Initialize the parameters
float confThreshold = 0.5; // Confidence threshold
float maskThreshold = 0.3; // Mask threshold
vector classes;
vector colors = { Scalar(255, 0, 255), Scalar(0, 255, 0), Scalar(255, 0, 0) };
// Draw the predicted bounding box
void drawBox(Mat& frame, int classId, float conf, Rect box, Mat& objectMask);
// Postprocess the neural network's output for each frame
void postprocess(Mat& frame, const vector& outs);
int main()
{
// Load names of classes
string classesFile = "./mask_rcnn_inception_v2_coco_2018_01_28/mscoco_labels.names";
ifstream ifs(classesFile.c_str());
string line;
while (getline(ifs, line)) classes.push_back(line);
//// Load the colors
//string colorsFile = "./mask_rcnn_inception_v2_coco_2018_01_28/colors.txt";
//ifstream colorFptr(colorsFile.c_str());
//while (getline(colorFptr, line))
//{
// char* pEnd;
// double r, g, b;
// r = strtod(line.c_str(), &pEnd);
// g = strtod(pEnd, NULL);
// b = strtod(pEnd, NULL);
// Scalar color = Scalar(r, g, b, 255.0);
// colors.push_back(Scalar(r, g, b, 255.0));
//}
// Give the configuration and weight files for the model
String textGraph = "C:/Users/18301/Desktop/mask_rcnn_inception_v2_coco/mask_rcnn.pbtxt";
String modelWeights = "C:/Users/18301/Desktop/mask_rcnn_inception_v2_coco/frozen_inference_graph.pb";
// Load the network
Net net = readNetFromTensorflow(modelWeights, textGraph);
net.setPreferableBackend(DNN_BACKEND_OPENCV);
net.setPreferableTarget(DNN_TARGET_CPU);
// Open a video file or an image file or a camera stream.
string str, outputFile;
//VideoWriter video;
Mat frame, blob;
// Create a window
static const string kWinName = "Deep learning object detection in OpenCV";
namedWindow(kWinName, WINDOW_NORMAL);
clock_t startTime = clock();
// get frame from the video
frame = imread("C:/Users/18301/Desktop/data/4.jpg");
// Stop the program if reached end of video
if (frame.empty())
{
cout << "Done processing !!!" << endl;
cout << "Output file is stored as " << outputFile << endl;
waitKey(3000);
}
// Create a 4D blob from a frame.
blobFromImage(frame, blob, 1.0, Size(512, 512), Scalar(), true, false);
//blobFromImage(frame, blob);
//Sets the input to the network
net.setInput(blob);
// Runs the forward pass to get output from the output layers
std::vector outNames(2);
outNames[0] = "detection_out_final";
outNames[1] = "detection_masks";
vector outs;
net.forward(outs, outNames);
// Extract the bounding box and mask for each of the detected objects
postprocess(frame, outs);
// Put efficiency information. The function getPerfProfile returns the overall time for inference(t) and the timings for each of the layers(in layersTimes)
vector layersTimes;
double freq = getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
string label = format("Mask-RCNN on 2.5 GHz Intel Core i7 CPU, Inference time for a frame : %0.0f ms", t);
putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
// Write the frame with the detection boxes
Mat detectedFrame;
frame.convertTo(detectedFrame, CV_8U);
clock_t endTime = clock();
cout << "整个程序用时:" << double(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
imshow(kWinName, frame);
waitKey(0);
return 0;
}
// For each frame, extract the bounding box and mask for each detected object
void postprocess(Mat& frame, const vector& outs)
{
Mat outDetections = outs[0];
Mat outMasks = outs[1];
// Output size of masks is NxCxHxW where
// N - number of detected boxes
// C - number of classes (excluding background)
// HxW - segmentation shape
const int numDetections = outDetections.size[2];
const int numClasses = outMasks.size[1];
outDetections = outDetections.reshape(1, outDetections.total() / 7);
for (int i = 0; i < numDetections; ++i)
{
float score = outDetections.at(i, 2);
if (score > confThreshold)
{
// Extract the bounding box
int classId = static_cast(outDetections.at(i, 1));
int left = static_cast(frame.cols * outDetections.at(i, 3));
int top = static_cast(frame.rows * outDetections.at(i, 4));
int right = static_cast(frame.cols * outDetections.at(i, 5));
int bottom = static_cast(frame.rows * outDetections.at(i, 6));
left = max(0, min(left, frame.cols - 1));
top = max(0, min(top, frame.rows - 1));
right = max(0, min(right, frame.cols - 1));
bottom = max(0, min(bottom, frame.rows - 1));
Rect box = Rect(left, top, right - left + 1, bottom - top + 1);
// Extract the mask for the object
Mat objectMask(outMasks.size[2], outMasks.size[3], CV_32F, outMasks.ptr(i, classId));
// Draw bounding box, colorize and show the mask on the image
drawBox(frame, classId, score, box, objectMask);
}
}
}
// Draw the predicted bounding box, colorize and show the mask on the image
void drawBox(Mat& frame, int classId, float conf, Rect box, Mat& objectMask)
{
//Draw a rectangle displaying the bounding box
rectangle(frame, Point(box.x, box.y), Point(box.x + box.width, box.y + box.height), Scalar(255, 178, 50), 3);
//Get the label for the class name and its confidence
string label = format("%.2f", conf);
if (!classes.empty())
{
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ":" + label;
}
//Display the label at the top of the bounding box
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
box.y = max(box.y, labelSize.height);
rectangle(frame, Point(box.x, box.y - round(1.5*labelSize.height)), Point(box.x + round(1.5*labelSize.width), box.y + baseLine), Scalar(255, 255, 255), FILLED);
putText(frame, label, Point(box.x, box.y), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0, 0, 0), 1);
Scalar color = colors[classId];
// Resize the mask, threshold, color and apply it on the image
resize(objectMask, objectMask, Size(box.width, box.height));
Mat mask = (objectMask > maskThreshold);
Mat coloredRoi = (0.3 * color + 0.7 * frame(box));
coloredRoi.convertTo(coloredRoi, CV_8UC3);
// Draw the contours on the image
vector contours;
Mat hierarchy;
mask.convertTo(mask, CV_8U);
findContours(mask, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE);
drawContours(coloredRoi, contours, -1, color, 5, LINE_8, hierarchy, 100);
coloredRoi.copyTo(frame(box), mask);
}
其中:
colors是画mask图像时的颜色,在这里因为只有两类物体,classID分别对应1和2,故在这里只生成了三个颜色,可以根据自己的类别进行调整。
classes是类别信息,可以去mscoco_labels.names下载,根据自己的要求进行更改,我把前面两个便签改成tank和white了,后面的标签其实也没啥用,可以删除也可以不删除。
接着就是调用.pb和.pbtxt文件了,把训练好的文件放到指定路径即可。
注意:blob时的图像大小不要设置太大,否则会非常慢~~~
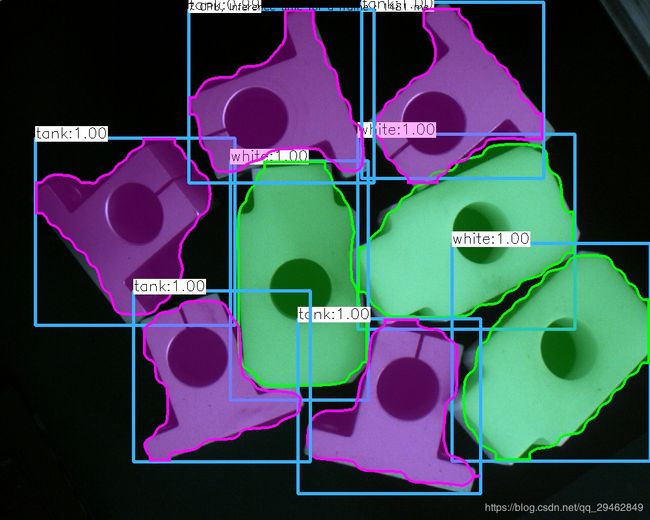
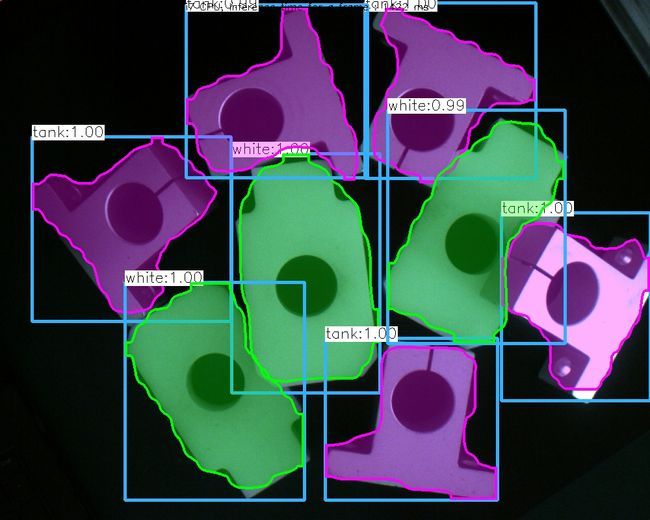
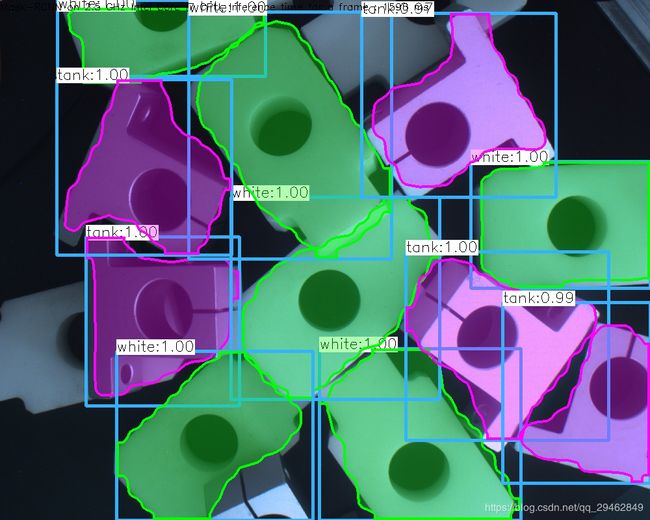
结果图像
训练只用了160幅图像,训练了一个小时,感觉效果还不够,接下来会把训练好的模型测试结果公布~~~