Windows下配置nutch
Windows下配置nutch轻松拥有自己的小引擎(表示弄了一上午了)
因为课程需要所以用到nutch,但是看了网上的攻略都不适用,各种bug,所以自己总结了一下经验
1、Nutch简介(建议看一下Nutch)
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫
Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎. 为了完成这一宏伟的目标, Nutch必须能够做到:
* 每个月取几十亿网页
* 为这些网页维护一个索引
* 对索引文件进行每秒上千次的搜索
* 提供高质量的搜索结果
组成
爬虫crawler和查询searcher。
Crawler主要用于从网络上抓取网页并为这些网页建立索引。
Searcher主要利用这些索引检索用户的查找关键词来产生查找结果。也就是crawler的逆过程
两者之间的接口是索引,所以除去索引部分,两者之间的耦合度很低。
Nutch和Lucene
Lucene是一个Java高性能全文索引引擎工具包可以方便的嵌入到各种实际应用中实现全文索引搜索功能。它提供了一系列API,能够对文档进行预处理、过滤、分析、索引和检索排序。在保持高效和简单的特点之外,还保证了开发者可以自由定制和组合各种核心功能。Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用,Lucene为Nutch 提供了文本搜索和索引的API,Nutch不仅提供搜索,而且还有数据抓取的功能。
Nutch是基于Lucene的。Lucene为Nutch提供了文本索引和搜索的API。
一个常见的问题是:我应该使用Lucene还是Nutch?
最简单的回答是:如果你不需要抓取数据的话,应该使用Lucene。
常见的应用场合是:你有数据源,需要为这些数据提供一个搜索页面。在这种情况下,最好的方式是直接从数据库中取出数据并用Lucene API 建立索引。
在你没有本地数据源,或者数据源非常分散的情况下,应该使用Nutch。
2、Nutch在Windows下的配置
因为nutch本身是基于linux内核完成的,所以在windows下配置的话就需要点小步骤啦~
在这里有两种方法可以实现在windows下使用nutch的小梦想:
- 在eclipse下使用nutch
- 借助cygwin使用nutch
个人认为,麻烦度差不多顺利的话秒秒钟,不行的话,呵呵~
首先都需要下载nutch(apache-nutch-1.1-bin.tar.gz),这个是官网的下载然后你可能会发现ta竟然有BAND EXCEED,这个是我上传的一个链接
1、Nutch在eclipse下的配置
- 新建一个Java项目,打开MyEclipse,点击File→New→JavaProject新建一个Java项目,输入ProjectName如Nutch0.9,点击Finish按钮。
- 导入nutch源码:
- 将nutch-0.9\src\java目录下的org文件夹整个复制到新建Java项目Nutch0.9的src包下
- 将nutch-0.9目录下的conf、lib、plugins复制到与src同级目录
- 在conf目录上单击右键→BuildPath→UseasSourceFolder,将配置文件conf加到path中
- 在Nutch0.9目录上单击右键→BuildPath→ConfigureBuildPath…,然后将lib中所有的jar添加到libraries里面
3.修改nutch的conf:
- 修改nutch-site.xml,(这个文件会覆盖nutch-default.xml中的内容),将其内容替换成:
http.agent.name * - 修改crawl-urlfilter.txt 将# accept hosts in MY.DOMAIN.NAME +^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/替换成# accept hosts in MY.DOMAIN.NAME +^http://([a-z0-9]*\.)*这个将要爬取得站点4.在根目录新建urls文件夹,并在其中新建一个url文件,是用来存放要爬取的url的,目录结构及url格式如下:


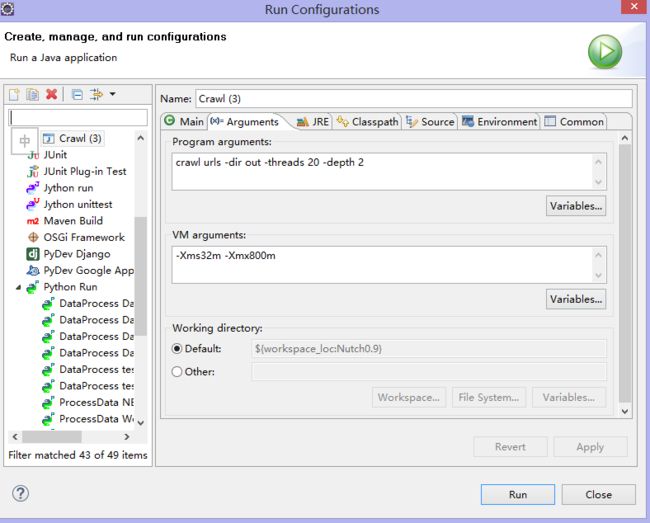
5.测试Crawl类,在MyEclipse中,展开src目录,找到org/apache/nutch/crawl包下的Crawl.java类,双击打开。右击打开RunConfigurations配置一下运行参数:
Run as → Run Configuration → Arguments
Program arguments输入:crawl urls -dir out -threads 20 -depth 2
- crawl:是nutch的爬虫命令
- urls:是新建的urls文件夹,用来读取要爬取得网址
- -dir out:是爬去结果的输出路径
- -threads 20:是开启的进程数
- -depth 2:是要爬取得深度
- -topN 10:是显示前10
VM arguments输入:-Xms32m -Xmx800m(注:这是设置内存大小,如果不设置会导致内存溢出异常)
点击Run,就可以跑喽!结束之后,out变成:

至此可以直接往下看步骤三将项目部署到tomcat上,这里在分析一下nutch的工作过程:
1. 创建一个新的WebDb (admin db -create).
2. 将抓取起始URLs写入WebDB中 (inject).
3. 根据WebDB生成fetchlist并写入相应的segment(generate).
4. 根据fetchlist中的URL抓取网页 (fetch).
5. 根据抓取网页更新WebDb (updatedb).
6. 循环进行3-5步直至预先设定的抓取深度。
7. 根据WebDB得到的网页评分和links更新segments (updatesegs).
8. 对所抓取的网页进行索引(index).
9. 在索引中丢弃有重复内容的网页和重复的URLs (dedup).
10. 将segments中的索引进行合并生成用于检索的最终index(merge).
2、Nutch在cygwin下的配置
1、下载cygwin并安装,将下载的nutch复制到cygwin的home目录下(方便)双击打开cygwin图标,进入一个命令窗口,进入nutch的bin目录,输入./nutch会出来很多nutch支持的命令
2、修改nutch的conf:
- 修改crawl-urlfilter,同eclipse
- 修改nutch_site:
其中searcher.dir的value是指爬去结果存放的路径,并且确保该路径下没有crawledhttp.agent.name * localweb.com searcher.dir D:\nutch\cygwin\Cygwin\home\KeXin\nutch-0.9\crawled
3、在D:\nutch\cygwin\Cygwin\home\KeXin\nutch-0.9\bin下新建文件url.txt里面同样存放网址
4、命令行进入bin输入命令:./nutch crawl weburls.txt -dir localweb -depth 2 -topN 100 -threads 2等待爬虫,OK了
3、将项目部署到tomcat上
下载nutch09的war包,将其丢到tomcat的webapps目录里,然后启动tomcat,再关闭,进入到webapps目录下,找到解压后的war包,进入webapps\nutch-0.9\WEB-INF\classes,找到nutch-site,修改如下:
searcher.dir
D:\nutch\cygwin\Cygwin\home\KeXin\nutch-0.9\bin\localweb
其中searcher.dir的值要和爬取结果存放位置一致
OK了,启动tomcat打开浏览器,输入http://localhost:8080/nutch-0.9/
