OpenCv学习笔记16--传统目标检测(BOW+SVM)
此opencv系列博客只是为了记录本人对<>的学习笔记,所有代码在我的github主页https://github.com/RenDong3/OpenCV_Notes.
欢迎star,不定时更新...
本篇文章为转载,原文:https://www.cnblogs.com/zyly/p/9796600.html
因为最近这两篇文章涉及目标检测方向,本人对这个方向还是很感兴趣的,虽然之前所复现的都是基于深度学习的目标检测算法,但感觉都是在调包,所以对目标检测的传统方法进行学习,以后也会逐步提高自己的coding能力,就目前而言,个人感觉pytorch框架挺好用的,代码简洁舒服,(当然TensorFlow作为工业级框架,也是要学习精通的),时间紧任务重,上车吧!!!
在上一节、我们已经介绍了使用HOG和SVM实现目标检测和识别,这一节我们将介绍使用词袋模型BOW和SVM实现目标检测和识别。
一 词袋介绍
词袋模型(Bag-Of-Word)的概念最初不是针对计算机视觉的,但计算机视觉会使用该概念的升级。词袋最早出现在神经语言程序学(NLP)和信息检索(IR)领域,该模型忽略掉文本的语法和语序,用一组无序的单词来表达一段文字或者一个文档。
我们使用BOW在一系列文档中构建一个字典,然后使用字典中每个单词次数构成向量来表示每一个文档。比如:
- 文档1:I like OpenCV and I like Python;
- 文档2:I like C++ and Python;
- 文档3:I don't like artichokes;
对于这三个文档,我们建立如下的字典:
dic = {1:'I',
2:'like',
3:'OpenCV',
4:'and',
5:'Python',
6:'C++',
7:'don\'t',
8:'artichokes'}该字典一共有8项。使用这8项构成的向量来表示每个文档,每个向量包含字典中的所有单词,向量的每个元素表示文档中每个单词出现的次数。则上面三个文档可以使用如下向量来表示:
[2,2,1,1,1,0,0,0]
[1,1,0,1,1,1,0,0]
[1,1,0,0,0,0,1,1]这里大家可以数一下上述字典中单词出现的次数,向量中确实是单词出现次数的表示,最上面是文档1....
每一个向量都可以看做是一个文档的直方图表示或被当做特征,这些特征可以用来训练分类器(后面基本基于这个思路).在实际中,也有许多有效地应用,比如垃圾邮箱过滤。
二 计算机视觉中的BOW
与应用到文本的BOW模型类比,我们可以把BOW模型应用到计算机视觉,我们把图像的特征当做单词,把图像“文字化”之后,有助于大规模的图像检索。
1、BOW基本步骤
- 特征提取:提取数据集中每幅图像的特征点,然后提取特征描述符,形成特征数据(如:SIFT或者SURF方法);
- 学习词袋:把处理好的特征数据全部合并,利用聚类把特征词分为若干类,此若干类的数目由自己设定,每一类相当于一个视觉词汇;
- 利用视觉词袋量化图像特征:每一张图像由很多视觉词汇组成,我们利用统计的词频直方图,可以表示图像属于哪一类;
这个过程需要获取视觉词汇(visual word)字典,从一定程度上来说,词汇越多越好,因此我们需要的数据集也相应的越大越好;
2、BOW可视化
下面我们来对BOW过程进行可视化,
- 假设我们有三个目标类,分别是人脸、自行车和吉他。首先从图像中提取出相互独立的视觉词汇(假设使用SIFT方法):

通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
- 将所有的视觉词汇集合在一起:

- 利用K-means算法构造词汇字典。K-means算法是一种基于样本间相似性度量的间接聚类方法,此算法以k为参数,把n个对象分为k个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT算法提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为词汇字典中的基础词汇,假定我们将k设为4,那么词汇字典的构建过程如下:

- 利用词汇字典中的词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用词汇字典中的词汇近似代替,通过统计词汇字典中每个词汇在图像中出现的次数,可以将图像表示成为一个$k=4$维数值向量:
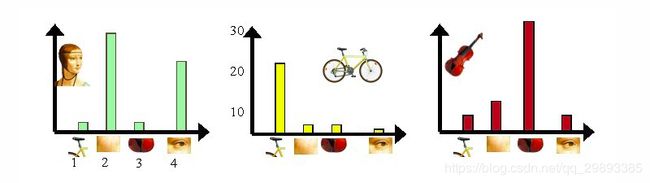
上图中,我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇字典中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉词汇,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示(我们假定存在误差,实际情况亦不外如此):
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个字典,字典中包含4个视觉单词,即:
dic = {1:'自行车',
2:'人脸',
3:'吉他',
4:'人脸类'}最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数绘制对应的直方图。
需要说明的是,以上过程只是针对三个目标类非常简单的一个示例,实际应用中,为了达到较好的效果,单词表中的词汇数量k往往非常庞大,并且目标类数目越多,对应的kk值也越大,一般情况下,k的取值在几百到上千,在这里k=4仅仅是为了方便说明。
最后小结一下,实质上就是利用BOW将图像"文字化",便于图像特征提取和大规模的图像检索...
先使用SIFT提取特征,利用K-means算法聚类构成词汇字典,然后给一张测试图像,BOW会将图像当成文档进行向量化表示,利用BOW量化绘制直方图,得到图像属于哪一类....
三 目标识别
对于图像和视频检测中的目标类型没有具体限制,但是为了使结果的准确度在可以接收的范围内,需要一个足够大的数据集,包括训练图像的大小尽量也一样。
如果自己构建数据集将会花费较长的时间,因此,在这里我们利用现成的数据集,在网上可以下载这样的数据集,这里我们使用猫和狗的数据集:(这里原作者给出的链接是官网的,下载速度比较慢..,所以这里给出百度云链接)
链接: https://pan.baidu.com/s/1JnZfLdPYFij1UT-_NqmhJg
提取码: ekm8

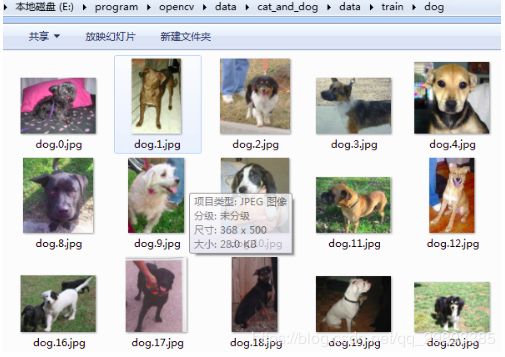
训练集一共包含25000张照片,其中一半是狗(正样本),一半是猫(负样本),在这里我们就使用其中的部分数据集,训练一个二分类器;
- 首先我们选取一定数量的正负样本(这里选择的为10,没有选择全部样本是因为数据量大,计算速度就会很慢,而且该数值小一些有时候效果会更好),然后使用SIFT算法提取特征数据,并使用聚类分类(k=40),形成词汇字典;
- 选取更多正负样本数据集(这里选择的是400),利用视觉词袋(即词汇字典)量化每一个样本特征,并使用SVM进行训练;
- 对100个样本进行测试;
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 17 09:38:26 2018
@author: ren_dong
"""
'''
词袋模型BOW+SVM 目标识别
以狗和猫数据集二分类为例
如果是狗 返回True
如果是猫 返回False
'''
import numpy as np
import cv2
class BOW(object):
def __init__(self, ):
# 创建一个SIFT对象 用于关键点提取
self.feature_detector = cv2.xfeatures2d.SIFT_create()
# 创建一个SIFT对象 用于关键点描述符提取
self.descriptor_extractor = cv2.xfeatures2d.SIFT_create()
def path(self, cls, i):
'''
用于获取图片的全路径
'''
# train_path/dog/dog.i.jpg
return '%s/%s/%s.%d.jpg' % (self.train_path, cls, cls, i + 1)
def fit(self, train_path, k):
'''
开始训练
args:
train_path:训练集图片路径 我们使用的数据格式为 train_path/dog/dog.i.jpg train_path/cat/cat.i.jpg
k:k-means参数k
'''
self.train_path = train_path
# FLANN匹配 参数algorithm用来指定匹配所使用的算法,可以选择的有LinearIndex、KTreeIndex、KMeansIndex、CompositeIndex和AutotuneIndex,这里选择的是KTreeIndex(使用kd树实现最近邻搜索)
flann_params = dict(algorithm=1, tree=5)
flann = cv2.FlannBasedMatcher(flann_params, {})
# 创建BOW训练器,指定k-means参数k 把处理好的特征数据全部合并,利用聚类把特征词分为若干类,此若干类的数目由自己设定,每一类相当于一个视觉词汇
bow_kmeans_trainer = cv2.BOWKMeansTrainer(k)
pos = 'dog'
neg = 'cat'
# 指定用于提取词汇字典的样本数
length = 10
# 合并特征数据 每个类从数据集中读取length张图片(length个狗,length个猫),通过聚类创建视觉词汇
for i in range(length):
bow_kmeans_trainer.add(self.sift_descriptor_extractor(self.path(pos, i)))
bow_kmeans_trainer.add(self.sift_descriptor_extractor(self.path(neg, i)))
# 进行k-means聚类,返回词汇字典 也就是聚类中心
voc = bow_kmeans_trainer.cluster()
# 输出词汇字典 (40, 128)
print(type(voc), voc.shape)
# 初始化bow提取器(设置词汇字典),用于提取每一张图像的BOW特征描述
self.bow_img_descriptor_extractor = cv2.BOWImgDescriptorExtractor(self.descriptor_extractor, flann)
self.bow_img_descriptor_extractor.setVocabulary(voc)
# 创建两个数组,分别对应训练数据和标签,并用BOWImgDescriptorExtractor产生的描述符填充
# 按照下面的方法生成相应的正负样本图片的标签 1:正匹配 -1:负匹配
traindata, trainlabels = [], []
for i in range(400): # 这里取200张图像做训练
traindata.extend(self.bow_descriptor_extractor(self.path(pos, i)))
trainlabels.append(1)
traindata.extend(self.bow_descriptor_extractor(self.path(neg, i)))
trainlabels.append(-1)
# 创建一个SVM对象
self.svm = cv2.ml.SVM_create()
# 使用训练数据和标签进行训练
self.svm.train(np.array(traindata), cv2.ml.ROW_SAMPLE, np.array(trainlabels))
def predict(self, img_path):
'''
进行预测样本
'''
# 提取图片的BOW特征描述
data = self.bow_descriptor_extractor(img_path)
res = self.svm.predict(data)
print(img_path, '\t', res[1][0][0])
# 如果是狗 返回True
if res[1][0][0] == 1.0:
return True
# 如果是猫,返回False
else:
return False
def sift_descriptor_extractor(self, img_path):
'''
特征提取:提取数据集中每幅图像的特征点,然后提取特征描述符,形成特征数据(如:SIFT或者SURF方法);
'''
im = cv2.imread(img_path, 0)
return self.descriptor_extractor.compute(im, self.feature_detector.detect(im))[1]
def bow_descriptor_extractor(self, img_path):
'''
提取图像的BOW特征描述(即利用视觉词袋量化图像特征)
'''
im = cv2.imread(img_path, 0)
return self.bow_img_descriptor_extractor.compute(im, self.feature_detector.detect(im))
if __name__ == '__main__':
# 测试样本数量,测试结果
test_samples = 100
test_results = np.zeros(test_samples, dtype=np.bool)
# 训练集图片路径 狗和猫两类 进行训练
train_path = './data/cat_and_dog/data/train'
bow = BOW()
bow.fit(train_path, 40)
# 指定测试图像路径
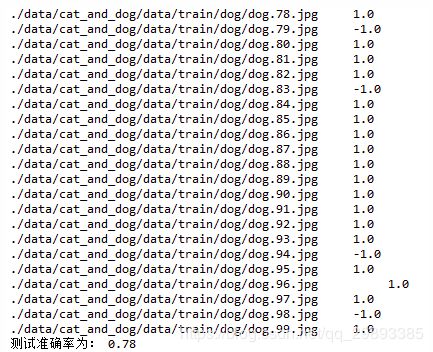
for index in range(test_samples):
dog = './data/cat_and_dog/data/train/dog/dog.{0}.jpg'.format(index)
dog_img = cv2.imread(dog)
# 预测
dog_predict = bow.predict(dog)
test_results[index] = dog_predict
# 计算准确率
accuracy = np.mean(test_results.astype(dtype=np.float32))
print('测试准确率为:', accuracy)
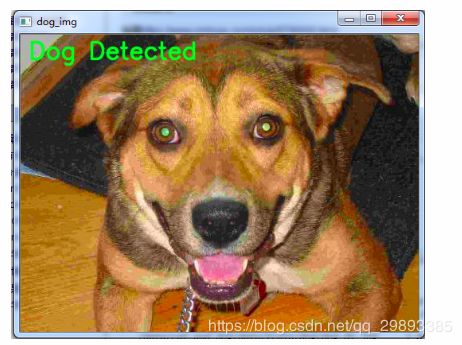
# 可视化最后一个
font = cv2.FONT_HERSHEY_SIMPLEX
if test_results[0]:
cv2.putText(dog_img, 'Dog Detected', (10, 30), font, 1, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('dog_img', dog_img)
cv2.waitKey(0)
cv2.destroyAllWindows() 运行结果如下: