Scrapy定向爬虫教程(六)——分析表单并回帖
本节内容
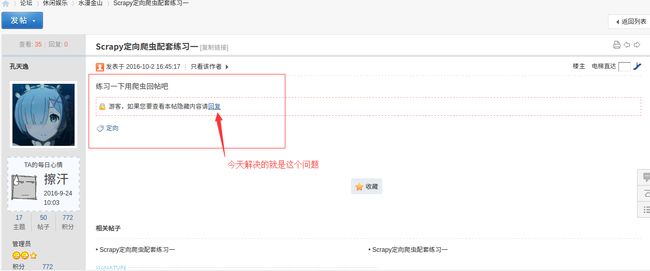
在某些时候,网站的某些内容的访问不仅仅需要用户登录,而且需要回复才能看到全部内容,如下图。所以我们需要通过模拟表单提交实现用爬虫回帖,进而获取到隐藏内容。本节就来介绍模拟表单提交的方法,github地址:https://github.com/kongtianyi/heartsong/tree/reply
前提
你已经了解了HTML表单的相关知识(这个很好找)和scrapy的简单功能以及配置Cookie,如果还不会,请戳Scrapy定向爬虫教程(五)——保持登陆状态。
分析表单
在帖子页面的底部找到表单,右键检查,查看这一部分的源代码

我们知道,表单提交的数据都在标签里,明显这里也没有多选框之类的东西,我们只需要把有name属性的元素如和