C#算法设计之知识储备
前言
算法的讨论具有一定的规则,其中也包含一些不成文的约定,本博文旨在为初学算法的同学指明一条通向算法的“不归路”。
渐近记号
1、Θ(big-theta)
若存在正常量
、
和
,使得当
时,不等式
恒成立,则称g(n)是f(n)的一个渐近紧确界,记作Θ。它包含渐近上界和渐近下界。
简单的理解为在 ![]() 时,f(n)被夹在
时,f(n)被夹在 ![]() 和
和 ![]() 之间,
之间,![]() 为f(n)的渐近下界,
为f(n)的渐近下界,![]() 为f(n)的渐近上界。
为f(n)的渐近上界。
2、O(big-oh)
若存在正常量 c和
恒成立,则称g(n)是f(n)的一个渐近上界,记作O。
简单的理解为在 ![]() 时,cg(n)总是在f(n)之上。
时,cg(n)总是在f(n)之上。
3、Ω(big-omege)
若存在正常量 c和
恒成立,则称g(n)是f(n)的一个渐近下界,记作Ω。
简单的理解为在 ![]() 时,cg(n)总是在f(n)之下。
时,cg(n)总是在f(n)之下。
其它几个记号在讨论算法的复杂度时极少用到,故本博文不予介绍。
以下给出这3种常用记号的函数图:
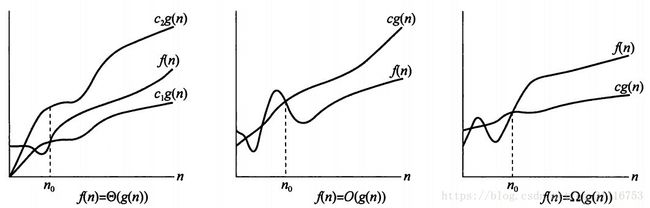
我们使用O表示算法在最坏的情况下所代表的时间复杂度,Ω表示算法在最好的情况下所代表的时间复杂度,Θ表示算法在平均情况下所代表的时间复杂度。
由于网络中很多文章均没有将这3个符号分清楚,比如我们讨论冒泡排序的时间复杂度时,其在最坏的情况下的时间复杂度为: ![]() ,在最好的情况下的时间复杂度为:
,在最好的情况下的时间复杂度为: ![]() ,在平均情况下的时间复杂度也为:
,在平均情况下的时间复杂度也为: ![]() 。这种记法是不正确的,但由于大家都这么写,本系列博文若未特殊说明,沿用此记法。
。这种记法是不正确的,但由于大家都这么写,本系列博文若未特殊说明,沿用此记法。
时间复杂度
在分析算法的时间复杂度时,我们一般分析其在最坏的情况下的关键代码的执行次数。还以冒泡排序为例,冒泡排序算法采用双循环比较相邻2个元素的值的大小,若符合预期则不管,若不符合预期则交换这2个元素的位置。设问题的规模为n,那么在最坏的情况下,即原数组逆序排列时,我们需要执行交换元素的代码次数为 ![]() 次,所以我们认为冒泡排序的时间复杂度为:
次,所以我们认为冒泡排序的时间复杂度为: ![]() 。事实上冒泡排序在最坏的情况下执行的精确次数一般不是
。事实上冒泡排序在最坏的情况下执行的精确次数一般不是 ![]() 次,而是略低于
次,而是略低于 ![]() 次,因为内循环可以被优化。每次外循环执行完毕后内循环可以少执行一次,因为每次外循环执行完毕时,最大的值已经在最后面了(若我们需要升序排序),内循环无需处理后面的元素。具体分析可参考我的另一篇博文,C#算法设计排序篇之01-冒泡排序(附带动画演示程序)。
次,因为内循环可以被优化。每次外循环执行完毕后内循环可以少执行一次,因为每次外循环执行完毕时,最大的值已经在最后面了(若我们需要升序排序),内循环无需处理后面的元素。具体分析可参考我的另一篇博文,C#算法设计排序篇之01-冒泡排序(附带动画演示程序)。
还有另外几个规则,在讨论算法的时间复杂度时,我们更关心的是高阶项,忽略低阶项。例如一个算法在最坏的情况下的执行次数为 ![]() 次,那么这个低阶的 n 可以被忽略,其时间复杂度就是
次,那么这个低阶的 n 可以被忽略,其时间复杂度就是 ![]() 。因为当 n 趋向于无穷大时,低阶的 n 对整体的执行次数没有多大影响。当一个算法执行的次数为 n 时,那么它的时间复杂度为
。因为当 n 趋向于无穷大时,低阶的 n 对整体的执行次数没有多大影响。当一个算法执行的次数为 n 时,那么它的时间复杂度为 ![]() ,也称这个算法的时间复杂度为线性的。n/2,n,2n,100000000n,都是线性的算法,均记为
,也称这个算法的时间复杂度为线性的。n/2,n,2n,100000000n,都是线性的算法,均记为 ![]() 。设一个算法的执行次数为 cn 次,常量c被忽略,因为当 n 趋向于无穷大时,常量对整体的执行次数没有多大影响。
。设一个算法的执行次数为 cn 次,常量c被忽略,因为当 n 趋向于无穷大时,常量对整体的执行次数没有多大影响。
你可能想到另外一个问题,线性的 100000000n 和 ![]() ,哪个效率更高?答案和你的问题规模有关。
,哪个效率更高?答案和你的问题规模有关。
若问题规模趋向于无穷大,线性的算法总是好于 ![]() ,因为高阶函数的增长速度快于低阶函数。对于
,因为高阶函数的增长速度快于低阶函数。对于 ![]() 和 100000000n ,当问题的规模大于1亿时,
和 100000000n ,当问题的规模大于1亿时,![]() 显著的超越线性的 100000000n ,但是若你的问题规模总是小于1亿,那么此时选择
显著的超越线性的 100000000n ,但是若你的问题规模总是小于1亿,那么此时选择 ![]() 的算法是个不错的选择,因为小于1亿时,
的算法是个不错的选择,因为小于1亿时, ![]() 小于 100000000n 。不过现实开发中,你不可能设计出 100000000n 的线性算法,此处仅作讨论。
小于 100000000n 。不过现实开发中,你不可能设计出 100000000n 的线性算法,此处仅作讨论。
若一个算法总是在某一确定时间内完成其运算,我们记作 ![]() ,并称其时间复杂度为常量的(或常数的)。典型的算法是哈希算法。我们一般认为哈希算法的时间复杂度为常量的(本博文不讨论关键字冲突等问题)。
,并称其时间复杂度为常量的(或常数的)。典型的算法是哈希算法。我们一般认为哈希算法的时间复杂度为常量的(本博文不讨论关键字冲突等问题)。
以下给出几种常见的时间复杂度曲线图以供参考:
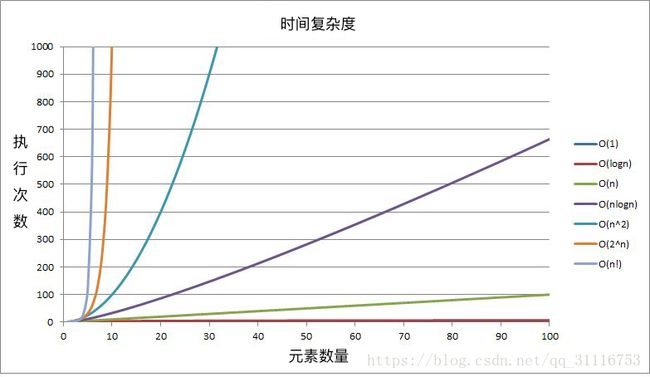
空间复杂度
与时间复杂度基本类似,本博文不予赘述。
基于比较的排序算法的下界
基于比较的排序算法的下界为 ![]() ,《算法导论》第3版中文版第107~108页(英文版第191~192页)使用决策树模型证明了此下界,有兴趣的同学可以自行观摩。
,《算法导论》第3版中文版第107~108页(英文版第191~192页)使用决策树模型证明了此下界,有兴趣的同学可以自行观摩。
常见的基于比较的排序算法有:冒泡排序、快速排序、直接插入排序、选择排序、归并排序、堆排序、希尔排序、二叉树排序等。
非基于比较的以空间换时间的排序算法有:计数排序、基数排序、桶排序等。
其中快速排序、归并排序、堆排序、二叉树排序4种排序算法都达到了比较排序算法的下界,我们一般称它们为基于比较的先进算法。
以上排序算法都可以在我的 C#算法设计概述 系列博文中找到,其中包含了时间复杂度的分析等。
排序算法的稳定性
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
即保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。
不稳定的排序算法有快速排序、直接选择排序、希尔排序、堆排序,简记为快、选、希、堆。其它的常见排序算法均为稳定性算法。
研究排序算法稳定性的意义是什么呢?
若你只想给一个无序数组排序,那么排序算法的稳定性没有任何意义。
若你要给一组对象排序,那么其可能是有意义的。例如一个学生对象包含学号和某次考试的总分2个字段,原来已经按学号排好序了(从小到大),现在让你按分数给这个学生对象的数组排序,但是若分数相同,那么学号小的依然排在前面,对于这种情况,你只能选择快、选、希、堆以外的排序算法。
内部排序与外部排序
内部排序:
待排序记录存放在计算机随机存储器中(内存)进行的排序过程。
外部排序:
待排序记录的数量很大,以致于内存不能一次容纳全部记录,所以在排序过程中需要对外存进行访问的排序过程。
假如你有1000亿条整数数据(无法一次载入内存),这些数据都是存在硬盘上的,现在你要写一个算法判定这1000亿条数据是不是升降排列的(nums[k+1] >= nums[k]),你可以每次从硬盘取出一批数据(内存可承受的),逐一判定相邻数据的大小关系,若不满足nums[k+1] >= nums[k]的关系直接判定false,如果1000条数据全部可以取出并没有被判定为false,则可以判定为true。
联机算法
联机算法是在任意时刻算法对要操作的数据只读入(扫描)一次,一旦被读入并处理,它就不需要在被记忆了。而在此处理过程中算法能对它已经读入的数据立即给出相应子序列问题的正确答案。
联机算法仅需要常量空间(不包含原数据)并以线性时间运行,因此联机算法几乎是完美的算法。
关于算法中的对数
数学中的对数:
对数是对求幂的逆运算,正如除法是乘法的倒数,反之亦然。
如果a的x次方等于N(a>0,且a不等于1),那么数x叫做以a为底N的对数(logarithm),记作
。其中,a叫做对数的底数,N叫做真数。
- 特别地,我们称以10为底的对数叫做常用对数(common logarithm),并记为lg;
- 称以无理数e(e=2.71828...)为底的对数称为自然对数(natural logarithm),并记为ln;
- 零没有对数;
- 在实数范围内,负数无对数。 在复数范围内,负数是有对数的。
算法中的对数:
考虑到计算机是二进制的,并且在很多算法中均出现以2作为基数的思想,比如分治策略、二分查找、二叉树等。所以在算法的讨论中若没有特别的说明 ![]() 是指以 2 为底的 n 的对数,即
是指以 2 为底的 n 的对数,即 ![]() ,《算法导论》第3版中均记作
,《算法导论》第3版中均记作 ![]() ,一般图书或博文中记作
,一般图书或博文中记作 ![]() ,它们都是指以 2 为底的 n 的对数。
,它们都是指以 2 为底的 n 的对数。
总结
以上即为学习算法的前提知识储备,本博文没有讨论过于深奥的数学知识,仅为算法的初学者提供些许的帮助。