使用tensorflow objet_detection API 实现遥感影像飞机模型识别全过程
1 思路产生
在进行了多次cifor10网络训练浦东机场飞机样本的试验后,发现网络只能做到辨别是不是飞机而无法实现在一张图中正确找出一架或多架飞机的功能,实验思路陷入僵局。7月27日凌晨觉得如此下去不能完胜既定实验任务,幸而在知乎大神的博文中发现了object_detection API这一google最新开源出来的技术,简要阅读后发现和自己的实验目标十分吻合,遂开始这一方向的研究。
2 环境准备
简要阅读官方文档后,按照installation进行配置。
- 问题1: Add Libraries to PYTHONPATH配置问题
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slimpwd是当前路径的意思,需要自己填写完整的路径进行配置,否则是找不到slim文件夹的,修改后为
export PYTHONPATH=$PYTHONPATH:/home/diana/tensorflow/models:/home/diana/tensorflow/models/slim- 问题2:Protobuf Compilation配置问题
# From tensorflow/models/
protoc object_detection/protos/*.proto --python_out=.每次使用新解压出来的object_detection文件夹时都要重新运行这一句,否则运行demo时会出现找不到string_int_label_map_pb2的问题,查看label_map_util.py文件发现from object_detection.protos import string_int_label_map_pb2 ,重新配置后问题解决。
- 问题3:python2 与python3 不兼容问题
运行demo进行测试,运行到
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)报错”得到的是byte类型,not string”
搜索之后锁定问题出在python的版本问题,这个API仅支持python2.7。尝试修改源码失败,从根本解决问题重新安装了沙箱facecourse-py2,并在其中安装tensorflow进行配置,demo运行成功!(但是我今天写blog想符合错误信息的时候,它使用python3也不报错了…….)
- 问题4: 安装tensorflow时版本不匹配
沙箱安装时遇到的问题和解决办法见我的上一篇blog[http://blog.csdn.net/qq_31120801/article/details/76359089]按照上述办法安装完成后运行失败,考虑到可能是
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.8.0rc0-cp27-none-linux_x86_64.whl –ignore-installed忽略了一些依赖包,所以使用pip install tensorflow 重新安装,这个命令会帮助你自动匹配相应的版本,由于是从国外的网站进行下载所以速度很慢,经常因为网速问题出现time runs out导致安装失败,可以使用清华大学临时镜像进行下载pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow 也可以修改配置文件永久使用清华大学镜像源。
- 问题5:libcudart.so.6: cannot open shared object file: No such file or directory
查看/usr/local/cuda/lib64文件夹发现只有libcudnn.so.5,使用以下语句建立libcudnn.so.6的软连接后问题解决
sudo ln -s libcudnn.so.5.* libcudnn.so.6一定要加 -s,否则删除libcudnn.so.6时会把libcudnn.so.5源文件一起删掉。
3 数据准备
object_detection API仅支持两种格式的数据集,分别是Oxford-IIIT Pets Dataset和PASCAL VOC2007/2012格式,所以要先将自己的数据制作成VOC2007格式,参考博文[http://www.cnblogs.com/whlook/p/7220105.html] ,因为这个工具是使用C++和python实现的所以在win10系统下安装vs2013和opencv2.4.9并进行配置,网上参考博文很丰富,使用时需要改为release模式,添加好标记后要按 ‘o’ 生成xml文件。在win10环境下安装沙箱facecourse-pyw,为win10下的python3.6下载匹配的opencv python-3.2.08-cp36-cp36m-win amd 64.whl
4 在本机实现训练过程
参考博文
[http://blog.csdn.net/shz_0519/article/details/73471128?utm_source=itdadao&utm_medium=referral]
由于本机显存太小,报错OOM无法进行训练。
5 在云端实现训练过程
注册谷歌云,创建GCS并配置自己的名字。
export YOUR_GCS_BUCKET=${YOUR_GCS_BUCKET}export YOUR_GCS_BUCKET=17diana18其他的步骤和在本机运行相似
- 问题6:Configuring the Object Detection Pipeline配置问题
和在本机运行不同的是要将PATH_TO_BE_CONFIGURED改为云端GCS的名称,并且配置文件中还可以设置相应的训练次数等参数,需要根据试验情况和样本数量自行修改。
sed -i "s|PATH_TO_BE_CONFIGURED|"gs://${YOUR_GCS_BUCKET}"/data|g" \
object_detection/samples/configs/faster_rcnn_resnet101_pets.configtrain_input_reader: {
tf_record_input_reader {
input_path: "gs://17diana18/data/pet_train.record"
}
label_map_path: "gs://17diana18/data/pascal_label_map.pbtxt"
}
eval_config: {
num_examples: 2000
}
eval_input_reader: {
tf_record_input_reader {
input_path: "gs://17diana18/data/pet_val.record"
}
label_map_path: "gs://17diana18/data/pascal_label_map.pbtxt"
shuffle: false
num_readers: 1
}6 将训练模型保存为.pb文件并移植到demo
gsutil cp gs://${YOUR_GCS_BUCKET}/train/model.ckpt-3942.* .
python object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path object_detection/samples/configs/faster_rcnn_inception_resnet_v2_atrous_pets.config \
--checkpoint_path model.ckpt-3942 \
--inference_graph_path output_inference_graph.pb直接导入生成的.pb文件即可不用再次下载模型
PATH_TO_CKPT = '/home/diana/tensorflow/models/output_inference_graph.pb'
PATH_TO_LABELS = os.path.join('data', 'pascal_label_map.pbtxt')
NUM_CLASSES = 17 模型识别性能测试与分析
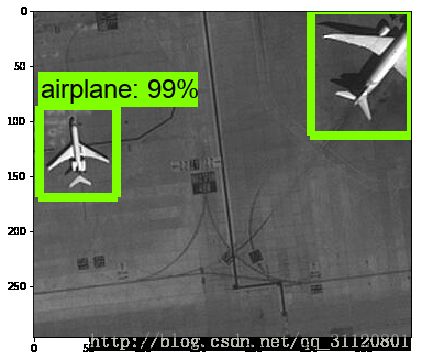


以后的实验将根据识别结果存在的问题做进一步的完善。