带你玩转kubernetes-k8s(第16篇:k8s-深入掌握Pod-玩转Pod调度)
上节为大家讲解了Pod的健康检查和服务可用性检查,这节我就带着大家更深层次的去学习Pod
玩转Pod调度
在k8s平台上,我们很少会直接创建一个Pod,在大多数情况下会通过RC、Deployment、DaemonSet、Job等控制器完成对一组Pod副本的创建,调度及全生命周期的自动控制任务。
在最早的k8s版本里面没有这么多Pod副本控制器的,只有一个Pod副本控制器RC(Replication Controller),这个控制器是这样设计实现的:RC独立于所控制的Pod,并通过Label标签这个松耦合关系控制目标Pod实例的创建和销毁,随着k8s的发展,RC也出现了新的继任者-Deployment,用于更加自动地完成 Pod副本的部署、版本更新、回滚等功能。
严谨地说,RC的继任者其实并不是Deployment,而是ReplicaSet,因为ReplicaSet进一步增强了RC标签选择器的灵活性。之前RC的标签选择器只能选择一个表情,而ReplicaSet拥有集合式的标签选择器,可以选择多个Pod标签,如下所示:
selector:
machLabels:
tier: frontend
matchExpressions:
- { key: tier, operator: In, values: [frontend] }与RC不同,ReplicaSet被设计成能控制多个不同标签的Pod副本。一种常见的应用场景是,应用MyApp目前发布了V1与V2两个版本,用户希望MyApp的Pod副本数保持为3个,可以同时包含v1和v2版本的Pod,就可以用ReplicaSet来实现这种控制,写法如下:
selector:
matchLabels:
version: v2
matchExpressions:
- { key : version, operator: In, values: [v1,v2] }
其实,kubernetes的滚动升级就是巧妙运用ReplicaSet的这个特性来实现的,同时,Deployment也是通过ReplicaSet来实现Pod副本自动控制功能的。我们不应该直接使用底层的RepicaSet来控制Pod副本,而应该使用管理ReplicaSet的Deployment对象来控制副本,这是来自官方的建议。
在大多数情况下,我们希望Deployment创建Pod副本被成功调度到集群中的任何一个可用节点,而不关心具体会调度到哪个节点,而不关心具体会调度到哪个节点。但是,在真实的生产环境中的确也存在一种需求:希望某种Pod的副本全部在指定的一个或者一些节点上运行,比如希望将MySQL数据库调度到一个具有SSD磁盘的目标节点上,此时Pod模板中的NodeSelector属性就开始发挥作用了,上述MySql定向调度案例的实现方式可分为以下两步。
(1) 把具有SSD磁盘的Node都打上自定义标签 “disk=ssd”。
(2) 在Pod模板中设定NodeSelector的值为 “disk=ssd”。
如此一来,k8s在调度Pod副本的时候,就会先按照Node的标签过滤出合适的目标节点,然后选择一个最佳节点进行调度。
上述逻辑看起来简单又完美,但在真实的生产环境中可能面临以下令人尴尬的问题。
上述逻辑看起来既简单又完美,但在真实的生产环境中可能面临以下令人尴尬的问题。
(1)如果NodeSelector选择的Label不存在或者不符合条件,比如这些目标节点此时宕机或者资源不足,该怎么办?
(2)如果要选择多种合适的目标节点,比如SSD磁盘的节点或者超高速硬盘的节点,该怎么办?Kubernates引入了NodeAffinity(节点亲和性设置)来解决该需求。
在真实的生产环境中还存在如下所述的特殊需求。
(1)不同Pod之间的亲和性(Affinity)。比如MySQL数据库与Redis中间件不能被调度到同一个目标节点上,或者两种不同的Pod必须被调度到同一个Node上,以实现本地文件共享或本地网络通信等特殊需求,这就是PodAffinity要解决的问题。
(2)有状态集群的调度。对于ZooKeeper、Elasticsearch、MongoDB、Kafka等有状态集群,虽然集群中的每个Worker节点看起来都是相同的,但每个Worker节点都必须有明确的、不变的唯一ID(主机名或IP地址),这些节点的启动和停止次序通常有严格的顺序。此外,由于集群需要持久化保存状态数据,所以集群中的Worker节点对应的Pod不管在哪个Node上恢复,都需要挂载原来的Volume,因此这些Pod还需要捆绑具体的PV。针对这种复杂的需求,Kubernetes提供了StatefulSet这种特殊的副本控制器来解决问题,在Kubernetes 1.9版本发布后,StatefulSet才可用于正式生产环境中。
(3)在每个Node上调度并且仅仅创建一个Pod副本。这种调度通常用于系统监控相关的Pod,比如主机上的日志采集、主机性能采集等进程需要被部署到集群中的每个节点,并且只能部署一个副本,这就是DaemonSet这种特殊Pod副本控制器所解决的问题。
(4)对于批处理作业,需要创建多个Pod副本来协同工作,当这些Pod副本都完成自己的任务时,整个批处理作业就结束了。这种Pod运行且仅运行一次的特殊调度,用常规的RC或者Deployment都无法解决,所以Kubernates引入了新的Pod调度控制器Job来解决问题,并继续延伸了定时作业的调度控制器CronJob。
与单独的Pod实例不同,由RC、ReplicaSet、Deployment、DaemonSet等控制器创建的Pod副本实例都是归属于这些控制器的,这就产生了一个问题:控制器被删除后,归属于控制器的Pod副本该何去何从?在Kubernates 1.9之前,在RC等对象被删除后,它们所创建的Pod副本都不会被删除;在Kubernates 1.9以后,这些Pod副本会被一并删除。如果不希望这样做,则可以通过kubectl命令的--cascade=false参数来取消这一默认特性:
kubectl delete replicaset my-repset --cascade=false接下来,我们通过实例来为大家讲解Pod调度控制器的各种功能和特性。
Deployment或RC:全自动调度
Deployment或RC的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
下面是一个Deployment配置的例子,使用这个配置文件可以创建一个ReplicaSet,这个ReplicaSet会创建3个Nginx应用的Pod:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80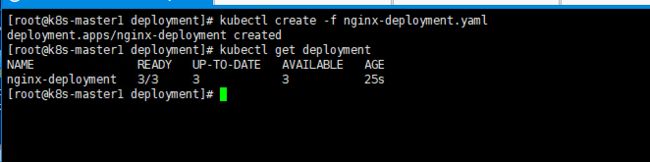
该状态说明Deployment已创建好所有3个副本,并且所有副本都是最新的可用的。
通过运行kubectl get rs和kubectl get pods可以查看已创建的ReplicaSet(RS)和Pod的信息。
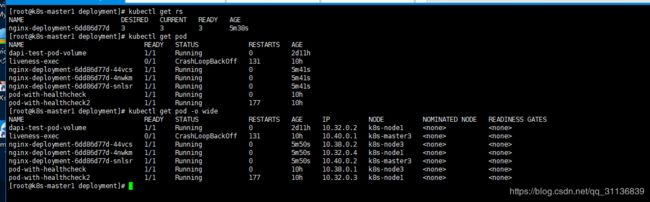
从调度策略上来说,这3个Nginx Pod由系统全自动完成调度。它们各自最终运行在哪个节点上,完全由Master的Scheduler经过一系列算法计算得出,用户无法干预调度过程和结果。
除了使用系统自动调度算法完成一组Pod的部署,Kubernetes也提供了多种丰富的调度策略,用户只需在Pod的定义中使用NodeSelector、NodeAffinity、PodAffinity、Pod驱逐等更加细粒度的调度策略设置,就能完成对Pod的精准调度。下面对这些策略进行说明。
NodeSelector
Kubernetes Master上的Scheduler服务(kube-scheduler进程)负责实现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会被调度到哪个节点上。在实际情况下,也可能需要将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,来达到上述目的。
(1)首 先通过kubectl label命令给目标Node打上一些标签:
kubectl label nodes = 这里,我们为k8s-node1节点打上一个zone=north标签,表明它是一个“北方”的一个节点
kubectl label nodes k8s-node1 zone=north

上述命令行操作也可以通过修改资源定义文件的方式,并执行kubectl replace -f xxx.yaml命令来完成。
(2)然后,在Pod的定义中加上nodeSelector的设置,以redis-master-controller.yaml为例:
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
nodeSelector:
zone: north

如果我们给多个Node都定义了相同的标签(例如zone=north),则scheduler会根据调度算法从这组Node中挑选一个可用的Node进行Pod调度。
通过基于Node标签的调度方式,我们可以把集群中具有不同特点的Node都贴上不同的标签,例如“role=frontend”“role=backend”“role=database”等标签,在部署应用时就可以根据应用的需求设置NodeSelector来进行指定Node范围的调度。
需要注意的是,如果我们指定了Pod的nodeSelector条件,且在集群中不存在包含相应标签的Node,则即使在集群中还有其他可供使用的Node,这个Pod也无法被成功调度。
除了用户可以自行给Node添加标签,Kubernetes也会给Node预定义一些标签,包括:
◎ kubernetes.io/hostname
◎ beta.kubernetes.io/os(从1.14版本开始更新为稳定版,到1.18版本删除)
◎ beta.kubernetes.io/arch(从1.14版本开始更新为稳定版,到1.18版本删除)
◎ kubernetes.io/os(从1.14版本开始启用)
◎ kubernetes.io/arch(从1.14版本开始启用)
用户也可以使用这些系统标签进行Pod的定向调度。
NodeSelector通过标签的方式,简单实现了限制Pod所在节点的方法。亲和性调度机制则极大扩展了Pod的调度能力,主要的增强功能如下。
◎ 更具表达力(不仅仅是“符合全部”的简单情况)。
◎ 可以使用软限制、优先采用等限制方式,代替之前的硬限制,这样调度器在无法满足优先需求的情况下,会退而求其次,继续运行该Pod。
◎ 可以依据节点上正在运行的其他Pod的标签来进行限制,而非节点本身的标签。这样就可以定义一种规则来描述Pod之间的亲和或互斥关系。
亲和性调度功能包括节点亲和性(NodeAffinity)和Pod亲和性(PodAffinity)两个维度的设置。节点亲和性与NodeSelector类似,增强了上述前两点优势;Pod的亲和与互斥限制则通过Pod标签而不是节点标签来实现,也就是上面第4点内容所陈述的方式,同时具有前两点提到的优点。
NodeSelector将会继续使用,随着节点亲和性越来越能够表达nodeSelector的功能,最终NodeSelector会被废弃。
小结:
今天的内容到此为止,希望大家可以好好消化,下节我为大家带来Node亲和性调度、Pod亲和与互斥调度策略。
谢谢大家的支持。