【论文笔记】Deep GrabCut for Object Selection
这篇论文基于《Deep Interactive Object Selection》,一作是同一个人。
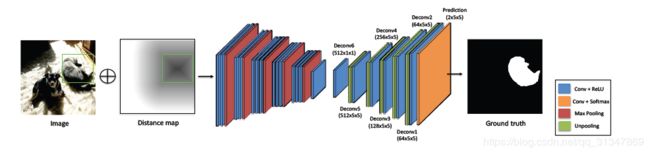
框架图:
目前的问题:
用 bounding box 做分割任务对 bounding box 的要求太高,需要紧紧贴着目标物体进行绘制,也就是假设用户绘制的边界框是刚好很符合目标物体边界的,但实际操作中,边界框通常是没这么准的,要么会大一点要么会小一点。
如果 bbox 小于目标物体的轮廓或者 bbox 内没有足够的背景信息,分割出来的效果都不太好,而且仅仅使用 bbox 中的信息还会会丢失上下文信息。
创新点:
使用 loosely-placed rectangle 执行分割任务,且得到的分割效果和使用一个 tight rectangle 得到的分割效果差不多,该方法可用于实例分割和交互式分割任务。
主要方法:
- 将 bbox 转换为欧式距离图(大小与输入的图像大小一致),将其作为一种软约束,在输入训练网络时,只需要将该欧式距离图和原 RGB 图像连接起来(即在通道数上进行扩展)
- 使用 dense CRF 将单独的分割结果转换为实例级的语义标签
主要方法
1. Rectangle sampling
方法描述: 通过采样各个分割目标的矩形框,扩充出一个训练集,同时还能保证不会过拟合。
具体实现:
对于每个实例,它的 ground truth 是最紧挨着物体边缘的 bounding box B 0 B^{0} B0,表示为 [ x m i n 0 , y m i n 0 , x m a x 0 , y m a x 0 ] [x^{0}_{min}, y^{0}_{min}, x^{0}_{max}, y^{0}_{max}] [xmin0,ymin0,xmax0,ymax0],即 bounding box 的左下角( [ x m i n 0 , y m i n 0 ] [x^{0}_{min}, y^{0}_{min}] [xmin0,ymin0])和右上角( [ x m a x 0 , y m a x 0 ] [x^{0}_{max}, y^{0}_{max}] [xmax0,ymax0])。
随机采样 N t r a i n N_{train} Ntrain 个矩形框,各个矩形框 B i , i ∈ { 1 , . . . , N t r a i n } B^{i}, i \in \{1, ..., N_{train}\} Bi,i∈{1,...,Ntrain} 的两个点(四个坐标)为:
x m i n / m a x i = x m i n / m a x 0 + v ⋅ g j i ⋅ ( x m a x 0 − x m i n 0 ) x^{i}_{min / max} = x^{0}_{min/max} + v · g^{i}_{j} · (x^{0}_{max} - x^{0}_{min}) xmin/maxi=xmin/max0+v⋅gji⋅(xmax0−xmin0)
y m i n / m a x i = y m i n / m a x 0 + v ⋅ g j i ⋅ ( y m a x 0 − y m i n 0 ) y^{i}_{min / max} = y^{0}_{min/max} + v · g^{i}_{j} · (y^{0}_{max} - y^{0}_{min}) ymin/maxi=ymin/max0+v⋅gji⋅(ymax0−ymin0)
其中, v v v 是一个超参数,控制矩形框的偏移程度, g j i g^i_j gji 服从标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1), j ∈ { 1 , 2 , 3 , 4 } j \in \{1,2,3,4\} j∈{1,2,3,4} 为 standard Gaussian random variables
2. Rectangle transformation
方法描述: 将上一步得到的每一个矩形框都转换为一个 distance map
具体实现:
给定图像 L L L 中的一个目标物体矩形框 B B B,定义矩形框 B B B 上的 pixel 为一个像素集合: S e = { p i ∣ p i i s o n t h e e d g e o f B } S_e = \{p_i | p_i \ is \ on \ the \ edge \ of \ B\} Se={pi∣pi is on the edge of B}, p i p_i pi 表示了像素 i i i 的位置。
同样地,
定义矩形框 B B B 内的 pixel 为一个像素集合: S i S_i Si
定义矩形框 B B B 外的 pixel 为一个像素集合: S o S_o So
创建 2D 图像的 distance map D D D,该 distance map 与原图像有着相同的宽度和高度
位置 p i p_i pi 的像素距离计算:
D ( p i ) = { 128 − m i n ∀ p j ∈ S e ∣ p i − p j ∣ , i f p i ∈ S i 128 , i f p i ∈ S e 128 + m i n ∀ p j ∈ S e ∣ p i − p j ∣ , i f p i ∈ S o D(p_i) = \begin{cases} 128 - min_{\forall p_j \in S_e}|p_i - p_j| & , if\ \ p_i \in S_i \\ 128 & , if\ \ p_i \in S_e \\ 128 + min_{\forall p_j \in S_e}|p_i - p_j| & , if\ \ p_i \in S_o \end{cases} D(pi)=⎩⎪⎨⎪⎧128−min∀pj∈Se∣pi−pj∣128128+min∀pj∈Se∣pi−pj∣,if pi∈Si,if pi∈Se,if pi∈So
其中, ∣ ⋅ ∣ |·| ∣⋅∣ 为欧几里得距离,本文使用 有符号的距离变换 来捕获输入矩形框的上下文信息(之前在 引文[25] 中使用的是无符号的距离变换,效果就不如这里好)
考虑到存储效率,将距离 D D D 截取到 0 ~ 255,最后将 distance map D 和 RGB 图像进行连接,送入训练网络进行训练。
3. DEDN model training
输入: RGB 与 distance map D 的 4 通道连接图
输出: 二值分割结果
CEDN model(Convolutional Encoder-Decoder Network)包含两个部分:encoder & decoder
Encoder: 由 convolutional layer 和 max-pooling layer 组成,作用是提取深层信息,将输入图片逐渐抽象成更小的 feature map。
Decoder: 由 convolutional layer 和 unpooling layer 组成,作用是根据 feature map 重建图像细节信息,还原到输入图像的大小
论文中,使用 VGG-16 的前 14 层参数来初始化 encoder 网络,而且由于 VGG 输入图像是三通道的,这里是 4 通道,所以第一层 convolutional filters 的第四通道参数初始化为 0
网络结构图:
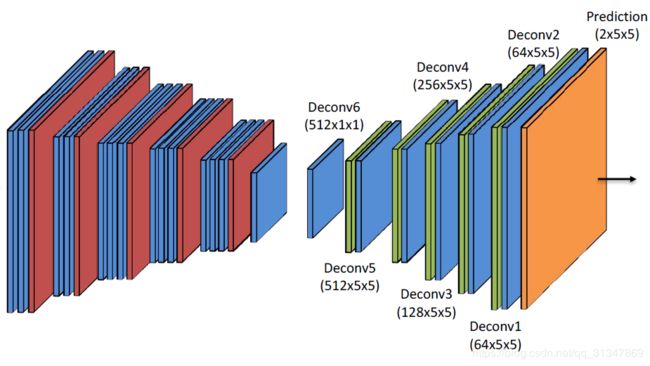
decoder 的参数由 Xavier 初始化,为解决过拟合问题,decoder 网络中在每个 conv layer 后都使用了 dropout 层。此外,在每个 training epoch 的开始阶段,随机地对所有训练数据进行重新采样。
将检测结果转换为像素级标签:
给定一张测试图片,将一组 detection rectangle 以及 labels 和 scores 作为输入,首先使用 NMS(非极大值抑制)处理这些 rectangle(暂时不考虑 class labels),然后在经过 NMS 处理后剩余的 rectangle 中独立地进行分割操作(rectangle segmentation),对每个 rectangle 生成前景概率图 P i f P_i^f Pif 和背景概率图 p i b p_i^b pib

实验部分
训练数据集: PASCAL VOC 2012 和 MS COCO
VOC 2012 训练和测试数据集划分: [8][9]
COCO 训练集: 2014 train-80k
采样参数: v = 0.15
优化方法: Adam
学习率: 1 0 − 5 10^{-5} 10−5
NMS threshold: 0.5
训练输入图像大小 resize 到 320 * 320
每个 train interation,对每个 instance 随机采样 4 个 bounding box,将它们作为一个 mini-batch。
-------实验结果(待补充)-------------