LinkHashMap 源码解析
简介
LinkHashMap是一种基于HashMap(如果不了解HashMap, 请先了解HashMap),维护一个双向链表以保证node(即Entry)插入顺序的数据结构。而对于HashMap来说(以及它的各式的子类),node是他的粒度(也可以理解成单位、元素等),实际上的结构,就是node在其上如何摆放。
LinkHashMap的node(LinkedHashMapEntry)
其构造如下
static class LinkedHashMapEntry<K,V> extends HashMap.Node<K,V> {
LinkedHashMapEntry before, after;
LinkedHashMapEntry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
} 可以看到,拥有HashMap.Node,以及指向前后node的LinkedHashMapEntry。
LinkHashMap
对于LinkHashMap构造,主要是为了初始化HashMap,以及accessOrder的设置
//双向链表头
transient LinkedHashMapEntry head;
//双向链表尾
transient LinkedHashMapEntry tail;
//是否保持访问顺序,默认为false
final boolean accessOrder;
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
} 在这里,初始化HashMap就不说了,主要说一说accessOrder。accessOrder属性为true时,会要求LinkHashMap不止单纯地保证插入顺序,还要根据访问情况,对这一顺序进行调整。如何进行调整,在下面会说到,这里先跳过。
结构的构造
通过调用put(key, value)将数据封装成node,插入数据结构。而put()操作,是依赖HashMap的,整个流程不变,LinkHashMap只是提供了node,即LinkedHashMapEntry。 通过put() -> putVal() ,在putVal()里讲数据封装成node,这样,这里封装成node的方法已经被LinkHashMap覆盖,所以实际上HashMap.putVal()里调用相应方法创建的node实际是LinkedHashMapEntry,主要关注这个部分, 如下。
Node newNode(int hash, K key, V value, Node e) {
LinkedHashMapEntry p =
new LinkedHashMapEntry(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMapEntry p) {
LinkedHashMapEntry last = tail;
tail = p;
// 说明双向链表还没有node,此时head,tail即是同一个node
if (last == null)
head = p;
// 加入node到链表尾部
else {
p.before = last;
last.after = p;
}
}
而在node创建的时候,调用了linkNodeLast()将node链接了起来。换句话说,对于LinkHashMap,先讲node放入了双向链表,再放入HashMap,然后形成了类似下图的结构

注意:LinkHashMap的node实际上是有三个引用(能理解成指针),after和before维护双向链表,next维护在HashMap上的单链表。
而LinkHashMap的remove操作也是类似,依赖HashMap.remove(), 从remove()->removeNode()->afterNodeRemoval(),在HashMap里,afterNodeRemoval()什么也没做,而LinkHashMap覆盖了afterNodeRemoval(), 将node从双向链表里移除了出去,代码如下
void afterNodeRemoval(Node e) { // unlink
//1⃣️
LinkedHashMapEntry p =
(LinkedHashMapEntry)e, b = p.before, a = p.after;
//2⃣️
p.before = p.after = null;
//说明当前双向链表只存在一个node
if (b == null)
head = a;
//3⃣️
else
b.after = a;
//说明当前双向链表只存在一个node
if (a == null)
tail = b;
//3⃣️
else
a.before = b;
} 代码标注的1、2、3如下图:

就是说在调用到afterNodeRemoval()前 , node在HashMap上已经不占据位置,而调用了afterNodeRemoval()将node从双向链表移除,才算彻底将node移除 , 一图胜过千言万语:
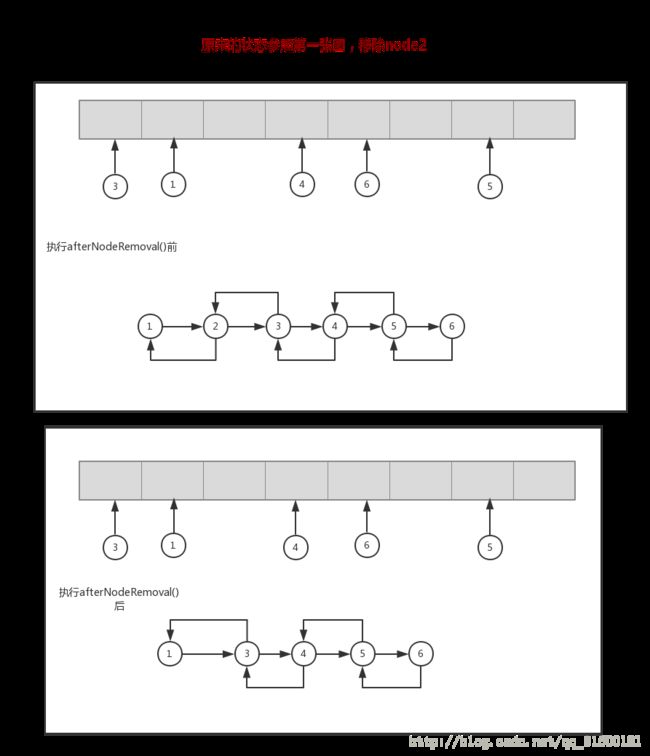
replace()操作也是相似的过程,先调整HashMap,再调整LinkHashMap;
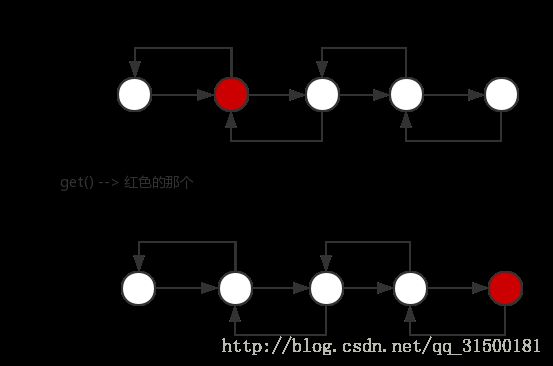
get()方法也是如此,两者都会访问到afterNodeAccess()
void afterNodeAccess(Node e) { // move node to last
LinkedHashMapEntry last;
if (accessOrder && (last = tail) != e) {
LinkedHashMapEntry p =
(LinkedHashMapEntry)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
} afterNodeAccess()如其所诉,是在访问了当前node之后,对此node做一些操作。前面提到的accessOrder,为false时,实际上进行的只是HashMap的get()或者replece()等能访问到进行到此处的方法;
而当accessOrder为ture时,就大不一样了。
accessOrder为ture时,要求LinkHashMap维持访问顺序,简言之,就是让越近访问的node,保持在离双向链表尾部越近的位置,相当于什么呢? 相当于将这个node从双向链表中移除,然后再此插入到双向链表,如下图
迭代器LinkedKeyIterator
接着说一说迭代器LinkedKeyIterator,LinkHashMap的迭代器在迭代时直接利用了双向链表的特定进行遍历,会比HashMap的遍历要快。 HashMap取决于“当前容量+最大容量”,LinkHashMap取决于当前容量,代码如下
final LinkedHashMapEntry nextNode() {
LinkedHashMapEntry e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
/**迭代器**/
final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator<K> {
public final K next() { return nextNode().getKey(); }
}
final class LinkedValueIterator extends LinkedHashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry next() { return nextNode(); }
} 对于LinkHashMap的源码解析到此差不多了,余下的一些感兴趣可以去看看,大同小异
使用场景
比如LRU(最近使用算法)的实现,LRU算发可以用来对内存缓存进行管理,内存缓存会将一些高频使用的数据存储在内存里,这样有助于提升程序性能,而借助LRU,越近被访问的数据能越快被访问。笔者是学Android,在Android里的LruCache就实现了这个功能,有兴趣的同学可以查看这里LruCache
再比如,笔者在工作中遇到要去读取文件,文件中保存了一些属性(用到了属性名,属性值,典型的键值dui),且对这些属性的使用顺序是有要求的。 因此,笔者就使用了LinkHashMap来进行存储,避免使用时顺序错乱,也避免使用如String[] key, String[] value 来存储的呆板代码。
总结
在文章的最后,来说一LinkHashMap的特点,这一些特点在源码的开头处写得很明白
1、保证插入顺序(可以根据需要保证访问顺序)
2、线程不安全
3、遍历时间只与当前容量有关
有不足之处,欢迎指出噢 X_0