深度学习经典目标检测实例分割语义分割网络的理解之五 MASK-RCNN
我不生产博文,我是CSDN的搬运工。
本文参考了下面这几篇博客:
@爆米花好美啊 https://blog.csdn.net/u013010889/article/details/78588227
@linolzhang https://blog.csdn.net/linolzhang/article/details/71774168
@lanyuxuan100 https://blog.csdn.net/lanyuxuan100/article/details/70807150
论文下载:Mask R-CNN 部分翻译
代码下载:【Github】
基于最早的 Faster RCNN 框架,出现不少改进,主要有三篇需要看:
1)作者推荐的这篇
Speed/accuracy trade-offs for modern convolutional object detectors
论文下载【arxiv】
2)ResNet
MSRA也算是作者自己的作品,可以 refer to blog【ResNet残差网络】
论文下载【arxiv】
3)FPN
Feature Pyramid Networks for Object Detection,通过特征金字塔来融合多层特征,实现CNN。
论文下载【arxiv】
改进
好了,继续这一系列的整理,mask-rcnn更进一步,利用之前的网络框架又添加了语义分割的功能。
Mask-RCNN 来自于年轻有为的 Kaiming 大神,通过在 Faster-RCNN 的基础上添加一个分支网络,在实现目标检测的同时,把目标像素分割出来。
Mask-RCNN 的网络结构示意:
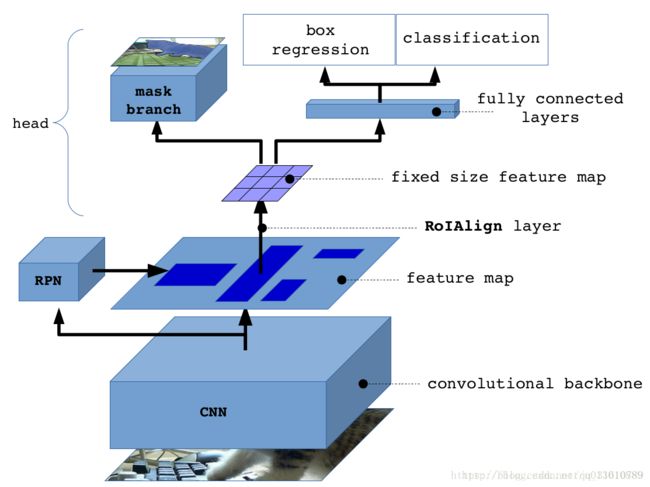
假设大家对 Faster 已经很熟悉了,不熟悉的同学建议先看下之前的博文:【目标检测-RCNN系列】
其中 黑色部分为原来的 Faster-RCNN,红色部分为在 Faster网络上的修改:
1)将 Roi Pooling 层替换成了 RoiAlign;
2)添加并列的 FCN 层(mask 层);
先来概述一下 Mask-RCNN 的几个特点(来自于 Paper 的 Abstract):
1)在边框识别的基础上添加分支网络,用于 语义Mask 识别;
2)训练简单,相对于 Faster 仅增加一个小的 Overhead,可以跑到 5FPS;
3)可以方便的扩展到其他任务,比如人的姿态估计 等;
4)不借助 Trick,在每个任务上,效果优于目前所有的 single-model entries;
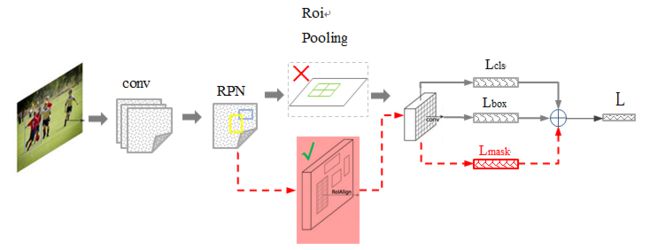
来看下 后面两种 RCNN 方法与 Mask 结合的示意图(直接贴原图了):
图中灰色部分是 原来的 RCNN 结合 ResNet or FPN 的网络,下面黑色部分为新添加的并联 Mask层,这个图本身与上面的图也没有什么区别,旨在说明作者所提出的Mask RCNN 方法的泛化适应能力 - 可以和多种 RCNN框架结合,表现都不错。

关键点
ROIAlign
问题
做segment是pixel级别的,但是faster rcnn中roi pooling有2次量化操作导致了没有对齐,因而产生了漂移出的误差。

两次量化,第一次roi映射feature时,第二次roi pooling时(这个图参考了youtube的视频,但是感觉第二次量化它画错了,根据上一讲ross的源码,不是缩小了,而是部分bin大小和步长发生变化)

RoIWarp,第一次量化了,第二次没有,RoIAlign两次都没有量化

和上一讲faster rcnn举的例子一样,输出7*7
划分7*7的bin(我们可以直接精确的映射到feature map来划分bin,不用第一次量化)

每个bin中采样4个点,双线性插值

则第一个bin 的值应该为2+2+7+7 除以4 = 4.5,对于每个bin,RoIAlign只用了4个值求平均。
对每个bin4个点做max或average pool
# pytorch
# 这是pytorch做法先采样到14*14,然后max pooling到7*7
pre_pool_size = cfg.POOLING_SIZE * 2
grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, pre_pool_size, pre_pool_size)))
crops = F.grid_sample(bottom.expand(rois.size(0), bottom.size(1), bottom.size(2), bottom.size(3)), grid, mode=mode)
crops = F.max_pool2d(crops, 2, 2)
# tensorflow
pooled.append(tf.image.crop_and_resize(
feature_maps[i], level_boxes, box_indices, self.pool_shape,
method="bilinear"))@爆米花好美啊 还提及了一种线性插值的方法,显然更准确,也显然计算更复杂。自己看着办吧。

关键点2 Lmask
L = L_cls + L_box + L_mask
在训练阶段,我们对每个样本的 RoI 定义了多任务损失函数 ,其中 L_cls 和 L_box 的定义和Fast R-CNN 是一样的。在 mask 分支中对每个 RoI 的输出是 K*m*m,表示K个 尺寸是 m*m的二值 mask,K是物体类别数目。每个 ROIAlign 对应 K*m*m 维度的输出。K对应类别个数,即输出K个mask,m对应 池化分辨率(7*7)。
Loss 函数定义:Lmask(Cls_k) = Sigmoid (Cls_k), 即 per-pixel sigmoid,平均二值交叉熵(average binary cross-entropy)Loss,通过逐像素的 Sigmoid 计算得到。
binary_crossentropy
即对数损失函数,log loss,与sigmoid相对应的损失函数。公式:L(Y,P(Y|X)) = -logP(Y|X)
该函数主要用来做极大似然估计的,这样做会方便计算。因为极大似然估计用来求导会非常的麻烦,一般是求对数然后求导再求极值点。损失函数一般是每条数据的损失之和,恰好取了对数,就可以把每个损失相加起来。负号的意思是极大似然估计对应最小损失。
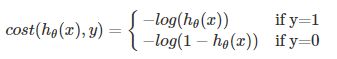
公式1
![]()
公式1合并后的公式
注:我们的 L_mask 只定义对应类别的 mask损失,其他类别的mask输出不会影响该类别的 loss。
我们定义 L_mask 的方式使得我们的网络在生成每个类别的 mask 不会受类别竞争影响,解耦了mask和类别预测。
Why K个mask?
通过对每个 Class 对应一个 Mask 可以有效避免类间竞争(其他 Class 不贡献 Loss )。
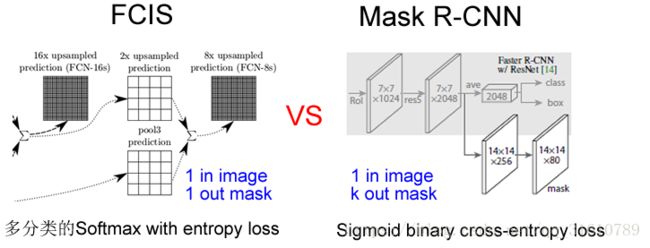
通过结果对比来看(Table2 b),也就是作者所说的 Decouple 解耦,要比多分类 的 Softmax 效果好很多。
3.1. Implementation Details
Training: 对于 mask loss L_mask 只在正样本的 RoIs 上面定义。
我们采用文献【9】的图像-中心 训练方法。将图像长宽较小的一侧归一化到 800个像素。在每个 mini-batch 上每个 GPU 有2个图像,每个图像 N个样本 RoIs,正负样本比例 1:3.其中 对于 C4 框架的 N=64, 对 FPN框架的 N=512。在8个GPU上训练,还有其他一些参数设置。
Inference: 在测试阶段,C4的候选区域个数是300, FPN 是 1000.对这些候选区域我们进行坐标回归,再非极大值抑制。然后对前100个得分最高的检测框进行 mask 分支运算。这样做可以提高速度改善精度。在 mask 分支中 ,我们对每个 RoI 给出 K 个 mask预测,但是我们只使用 分类分支给出的那个类别对应的 mask。然后我们将 m×m 浮点 mask 归一化到 RoI 尺寸,使用一个0.5阈值进行二值化。
human pose estimation:

1.R-CNN:https://arxiv.org/abs/1311.2524
2.Fast R-CNN:https://arxiv.org/abs/1504.08083
3.Faster R-CNN:https://arxiv.org/abs/1506.01497
4.Mask R-CNN:https://arxiv.org/abs/1703.06870
以及文中提到的选择性搜索:
http://www.cs.cornell.edu/courses/cs7670/2014sp/slides/VisionSeminar14.pdf