初学python
python是一门简单易学,功能强大的编程语言。它拥有高效的高级数据结构和简单却有效的面向对象编程方法。Python优雅的语法和动态类型以及其解释性的性质,使它在许多领域和大多数平台成为编写脚本和快速应用程序开发的理想语言。
安装python
如果使用linux系统,系统里可能默认安装了python,你可以打开gnome-terminal,在里面输入命令python,就可以进入python编辑运行界面了,如果失败了,那可能你的linux系统并没有安装python,不过这种可能性很小。
如果使用windows系统,你可以在 https://www.python.org/上下载python的安装包,我选择的是python2.7.13。
安装好python后,我们可以使用python自带的编辑器IDLE,IDLE具有语法加亮的功能,还有其他的功能,比如允许你在IDLE中运行你的程序。特别注意的是不要使用Notepad--它是一个糟糕的选择,因为它没有语法加亮功能,而且更重要的是,它不支持缩进,而对于python来说,缩进是非常重要的。一个好的编辑器,比如IDLE(还有VIM)将会自动帮助我们做这些事情。
第一个python程序
安装好python编辑器后,我们可以开始我们的第一个python程序了。打开IDLE:
print 'Hello world!'有了输出,理所当然的我们就想到了,怎么输入呢?
name=raw_input()
你可能觉得这样有点不合用户的使用习惯,又没说输入什么,那我怎么知道输入什么呢?我们可以这样:
name=raw_input('Please input your name:')python基础概念
看到这应该对python有了一定的了解吧!它确实是如此的简单,我这里说的只是python的语法比较简单,并不是学习python比较简单,实际上python并不简单,它只是使用很简单的语句,就可以实现很强大的功能,可能我们现在还没有发现,以后我们就会知道的。
数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然的可以处理各种数值。但是计算机处理的远不止数值,还可以处理文本、图形、音频、视频、和网页等各种各样的数据,不同的数据需要定义不同的数据类型。
数:python有4种类型的数——整数、长整数、浮点数和复数。
字符串:它是字符的数列,基本上每个python程序都需要使用到字符串。
使用单引号(' '):用单引号指示字符串,就如同
'Quote me on this'这样。所有的空白,即空格和制表符都照原样保留。
使用双引号(" "):在双引号中的字符串与单引号中的字符串的使用完全相同,但是一般我们使用单引号,只有在一个字符串中出现单引号时,我们把该字符串用双引号包裹起来。
使用三引号(''' '''):用来指示一个多行的字符串,如果字符串内部很多换行,用\n写在一行里不好阅读,为了简化,就使用了三引号,你可以在三引号中自由的使用单引号和双引号。例如:
'''This is a multi-line string.
This is the first line.
This is the second line.
"What's your name?," I asked.
He said "Bond, James Bond."
字符串编码,如果我们想要输出中文,我们应该这样:
print u'中文' 它便表示用Unicode表示的字符
'''
还有布尔值类型,它只有两种值True和False,布尔值可以使用and、or和not运算,也就是与或非。
空值,使用None表示。
此外,python还提供了列表、字典等其它的数据类型,还允许创建自定义数据类型。
变量和常量
常量就是不能变的量,例如数字,字符串等。
变量,它可以是任何数字类型,变量在程序中用一个变量名表示,变量名必须是大小写英文、数字和_的组合,且不能用数字开头。
a='abc'
就是在内存中创建了一个‘abc’的字符串,又创建了一个名为a的变量并把它指向‘abc’。
列表和元组
列表:list,是一种有序的集合,可以随时添加和删除其中的元素。下面便是建立了一个名为name 的列表:
name=['Alex','Bob','Carry']
它可以使用索引访问每个位置的元素,索引从0开始,name[0]便是获取第一个元素,它是‘Alex’,我们还可以用-1做索引,直接获取最后一个元素,以此类推,可以获取倒数第2个、第3个,当然倒数第4个就越界了。
我们可以通过len(name)来获取list的长度。
list的一些函数:
| name. | append('Wenxue') | 向list的末尾追加一个元素 |
| count('Wenxue') | 查看该元素出现的次数 | |
| index('Wenxue') | 查看该元素的索引 | |
| remove('Wenxue') | 移除该元素,如果有多个,删除最前面的一个 | |
| pop() | 最后一个出去,可添加索引参数,移除指定位置的元素,return 移除的元素 | |
| reverse() | 排序,每执行一次,list都会改变 | |
| sort() | 排序,按照从小到大的顺序排列,最常用的 |
获得列表中最小值:min(list)
相反有:max(liist)
元组:tuple,与list非常类似,但是tuple一旦初始化,便不可更改,所以它没有pop、insert等方法。下面是建立一个元组:
name=('Alex','Bob','Carry')
不变的tuple有什么意义?因为tuple不可变,所以代码更安全,如果可能,能用铺tuple代替list就尽量用tuple。
定义只有一个元素的tuple,必须加一个逗号,避免歧义,如:t=(1,)
虽然tuple不可变,但是tuple中可以加入列表元素,并且列表元素是可变的,这是为什么呢?从表面上看,tuple变了,但实际上是list的元素变了,tuple并没有变,tuple并没有指向别的list,所以tuple不变是指,tuple的每个元素,指向永远不变,指向一个list就不能改为指向别的对象,但指向的list本身是可变的。
dict和set
字典:dict(dictionary),使用键-值存储,具有极快的查找速度,key键必须保持不变。下面是新建一个字典
d={'Alex':95,'Bob':98,'Carry':93}
根据键来获取值,d['Alex'],值便是95,也可以这样赋值。
为了避免键不存在的错误,我们可以这样:
'Alex' in d #判断‘Alex’是否在字典d中
d.get('Alex')
#如果key不存在,可以返回None,或者自己指定的value
要删除一个key,可以用pop(key)方法,对应的value就会删除。
| d. | keys() | 得到键列表 |
| values() | 得到值列表 | |
| items() | 得到键值元组的列表,[(,),(,)] |
for k,v in d.items():
print k,v
#输出键值
set:与dict类似,是key的集合,但是不存储value,key值依然不能重复,下面是创建一个set:
s=set([1,2,3])
要创建一个set,需要提供一个list作为输入集合,传入的参数[1,2,3]是一个集合,但是显示的set([1,2,3])只是表明这个set内部有1,2,3这3个元素,显示的[ ]并不表示这是一个list。注意:重复的元素会被过滤。
运算符

运算符的优先级

流程控制
if条件语句
if ... :
elif ... :
else:
循环语句
while ... :
for i in n:
break、continue语句
函数
函数:它们允许你给一块语句一个名称,然后你可以在你的程序的任何地方使用这个名称任意多次地运行这个语句块。这被称为调用函数。函数通过
def关键字
定义。def关键字后跟一个函数的 标识符 名称,然后跟一对圆括号。圆括号之中可以包括一些变量名,该行以冒号结尾。接下来是一块语句,它们是函数体。
例如:
def sayHello():
print 'Hello World!'默认参数
对于一些函数,你可能希望它的一些参数是可选的,如果用户不想要为这些参数提供值的话,这些参数就使用默认值。
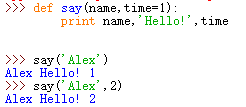
用处:如果开始定义是say(name),直接改为say(name,time),那么之前调用say(name)的位置就会出错,全部需要修改,而如果我们改为默认参数,那么都可以调用,就不会出错。
注意:必选参数在前,默认参数在后,有多个参数时,变化大的参数放在前面,变化小的放在后面,默认参数必须指向不变对象。
关键参数
如果你的某个函数有许多参数,而你只想指定其中的一部分,那么你可以通过命名来为这些参数赋值。
例如:
def say(a,b=1,c=2) say(1,c=4)
可变参数
参数的数目可变。定义:
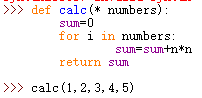
numbers接受到的是一个tuple。如果有一个list或tuple,,我们可以在前面加一个*号,把list或tuple的元素变成可变参数传入进去,我们可以这样调用,list=[1,2,3,4,5],calc(*list)
关键字参数
允许传入0个或任意个含参数名的参数,这些关键字在函数内部自动组装为一个dict。这样定义:
def person(name,age,**kw):
print 'name:',name,'age:',age,'other:',kw
person('Bob',35,city='Beijing')
结果:
name:Bob age:35 other:{'city':'Beijing'}
也可以直接传入一个dict person('Bob',35,**dict)
参数组合
这四种参数可以一起使用,但是定义的顺序必须是:必选参数,默认参数,可变参数和关键字参数
python高级应用
高级特性
切片
对于
list取出指定索引范围的元素,如果用循环取出的话,是十分繁琐的,因此,python提供了切片操作符。
L是一个list:
L[0:3]
从索引0开始取,直到索引为3结束,但不包括索引3,即索引0,1,2,如果第一个索引是0,还可以省略:L[:3]
同样的python也支持倒数切片:L[-2:]
从倒数第2个到最后一个
L=range(10)
0-9的列表
L[::2]
所有数,每两个取一个,结果是:[0,2,4,6,8]
什么都不写
L[:]
就可以原样复制一个list
tuple也是一种list,唯一的区别是tuple不可变。因此,tuple也可以使用切片操作,只是操作的结果仍是tuple。
迭代
在python中迭代是用for...in完成的,for循环可以用在所有可迭代对象中,如list,tuple,dict,字符串等。
怎么判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断:
对list实现类似java那样的下标循环,python内置的enumerate函数可以把一个list变成索引-元素对:

列表生成式
[x*x for x in range(1,11)]
结果:[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
[x*x for x in range(1,11) if x%2==0
]结果是:[4, 16, 36, 64, 100]
[m+n for m in 'ABC' for n in 'XYZ']
双层循环,结果是:
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ'] ,三层和三层以上的用的就很少了。
生成器
在python中,一边循环,一边计算的机制,称为生成器generator。创建生成器:
1、把列表生成式的[ ]改为(),就创建了一个generator:g=(x*x for x in range(10))。
列表生成器要把元素打印出来,可以使用g.next()方法,调用一次,打印出来一个元素。generator保存的是算法,每次调用next(),就计算出下一个元素的值,知道计算出最后一个元素,没有更多元素时,抛出StopIteration的错误。
所以正常的方法是使用for循环:for n in g:print n
就可以得到结果。
2、如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。
与普通函数的执行流程不一样,变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。上面就是一个斐波那契数列。
函数式编程
map
map函数接收两个参数,一个是函数,一个是序列。map将传入的函数依次作用于序列的每个元素,并把结果作为新的list返回。
举例说明:

reduce
reduce把一个函数作用在一个序列上,这个函数必须接收两个参数,reduce把结果和序列的下一个元素做累计计算。
举例说明:

filter
filter函数也接收一个函数和一个序列。和map不同的是,filter把传入的函数依次作用于每个元素,然后根据返回的值是True还是False决定保留还是丢弃该元素。
举例说明:filter(is2,[1,2,3,4,5,6,7]) 结果:只保留奇数[1, 3, 5, 7]
sorted
sorted函数可以对list进行排序:
sorted([23,1,4,34,5,2,4,42,3])
结果[1, 2, 3, 4, 4, 5, 23, 34, 42]
结果[1, 2, 3, 4, 4, 5, 23, 34, 42]
也可以接收一个比较函数来实现自定义的排序:

面向对象编程
类和对象是面向对象编程的两个主要方面。类创建一个新类型,而对象这个类的实例。这类似于你有一个int类型的变量,这存储整数的变量是int类的实例(对象)。
类使用class关键字定义:
class Student(object):
def __init__(self,name,age):
self.__name=name
self.__age=age
def get_name(self):
return self.__name
def set_name(self,name):
self.__name=name
def get_age(self):
return self.__age
def set_age(self,age):
self.__age=age
def toString(self):
print '[name:%s,age:%s]' %(self.__name,self.__age)类中每一个方法都必须有第一个参数self,代表类本身。__init__就相当于一个构造函数,将传入的值传给类的属性中,类的任何方法都可以调用属性。将类的属性名称前加上下划线__,就变成一个私有变量private,只有内部可以访问,通过self__name,为了让外界访问和修改属性,可以增加get_name(self)和set_name(self,name)这样的属性方法。
class Student(object):object代表继承的类,如果没有继承就用object来代替。
获取对象信息:
type('str')
判断对象类型
isinstance('a',str)
判断‘a’是否是str类型的,返回一个布尔值
dir('ABC')
获得一个对象的所有属性和方法。返回一个包含字符串的list
len(''ABC)
它会自动调用对象内部的__len__方法
hasattr(s,'x')
有属性'x'吗?
setattr(s,'x',12)
设置属性x
getattr(s,'x')
获取属性x
如果试图获取不存在的属性,会抛出AttributeError的错误
异常处理
try:
可能出异常的语句
except IOError:
出IO异常时执行,如果是except:那么什么异常都执行
else:
不出异常时执行
finally:
无论是否出异常都执行
常见异常
| AttributeError | 试图访问对象没有的属性 |
| IOError | 输入/输出异常,基本上是无法打开文件 |
| ImportError | 无法引入模块或包 |
| IndentationError | 语法错误,代码没有对齐 |
| IndexError | 索引超出范围 |
| KeyError | 试图访问字典中不存在的键 |
| KeyboardInterrupt | Ctrl+C被按下 |
| NameError | 使用一个还没有被赋予对象的变量 |
| SyntaxError | python代码非法,代码不能编译 |
| TypeError | 传入对象类型与要求不符 |
| UnboundLocalError | 试图访问一个还未被设置的局部变量,基本上是由于有另一个同名的全局变量 |
| ValueError | 传入一个调用者不期望的值 |
差不多学到这里了,那就先更新到这里吧!初学,如果有错误,请多多包含,我会努力改正,这是第一次写博客哦!请大家多多支持。