深层神经网络--Tensorflow实战google深度学习框架
1.深度学习与深层神经网络
维基百科对深度学习的精确定义为:一类通过多层非线性变换对高复杂性数据建模算法的合集。因为深层神经网络时实现“多层非线性变换”最常用的一种方法,深度学习有两个非常重要的特性---多层和非线性。
多层:是因为可以具备组合特征提取的功能,可以有效的提取人类不能手动提取的很多特征。
非线性:只通过线性变换,任意层的全连接神经网络和单层网络模型的表达能力没有任何区别,而且他们都是线性模型,然后线性模型能够解决的问题是有限的。如果将每一个神经元(也就是神经网络中的节点)的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了。这个非线性函数就是激活函数。
2.激活函数
| 激活函数 |
优点 |
缺点 |
| sigmod |
非线性,范围(0,1) |
很敏感,易饱和,影响预测精度 |
| sofmax |
非线性,范围(0,1),归一化 |
较敏感 |
| tanh |
非线性,范围(-1,1),容错性好,有界 |
不敏感,梯度较大 |
| relu |
非线性,单侧抑制,范围(0,+) |
|
2.1 softmax函数:

优点是:输出概率范围有限,为(0,1),并且对其进行了归一化。
缺点是:饱和的时候梯度太小。
2.2 RELU函数:
ReLU(x)=max{0,x}
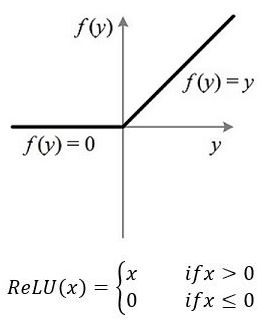
从上图不难看出,ReLU函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被成为单侧抑制。可别小看这个简单的操作,正因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。尤其体现在深度神经网络模型(如CNN)中,当模型增加N层之后,理论上ReLU神经元的激活率将降低2的N次方倍。因为有的特征有用,有的特征没有用,ReLU实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。缺点就是输出的范围较大。
2.3 sigmod函数:
Sigmoid函数是一个有着优美S形曲线的数学函数,在逻辑回归、人工神经网络中有着广泛的应用。Sigmoid函数的数学形式是:
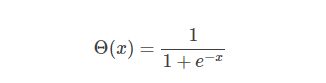
其函数图像如下:
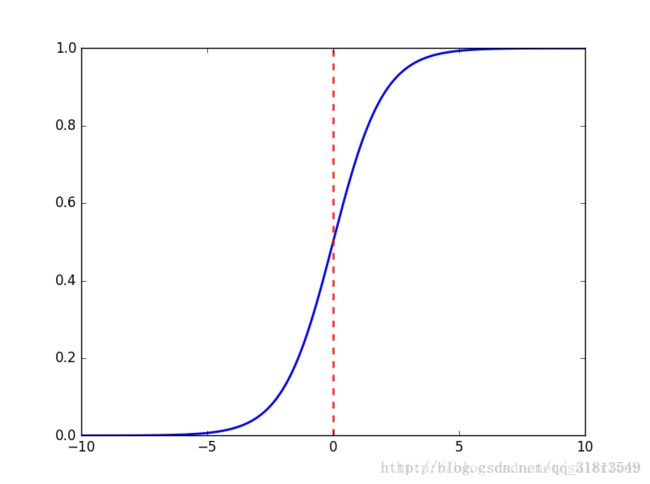
可以看出,sigmoid函数连续,光滑,严格单调,以(0,0.5)中心对称,是一个非常良好的阈值函数。当x趋近负无穷时,y趋近于0;趋近于正无穷时,y趋近于1;x=0时,y=0.5。当然,在x超出[-6,6]的范围后,函数值基本上没有变化,值非常接近,在应用中一般不考虑。Sigmoid函数的值域范围限制在(0,1)之间,我们知道[0,1]与概率值的范围是相对应的,这样sigmoid函数就能与一个概率分布联系起来了。
sigmoid的优点在于输出范围有限,为(0, 1),所以数据在传递的过程中不容易发散,可以用作输出层。当然也有相应的缺点,就是饱和的时候梯度太小,易于饱和,影响神经网络预测的精度值。
2.4 tanh函数:
tanh(x)函数的数学公式为:
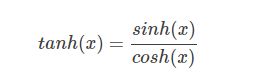
函数取值范围(-1,1),函数图像下图所示:

其中sinh(x)数学公式为:
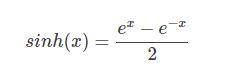
其中cosh(x)数学公式为:
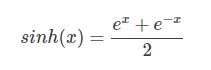
tanh作为激活函数,因为其非线性,值域为(-1,1),导函数的值域为(0,1)
观察sigmoid和tanh的函数曲线,sigmoid在输入处于[-1,1]之间时,函数值变化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态,影响神经网络预测的精度值。tanh的输出和输入能够保持非线性单调上升和下降关系,符合BP网络的梯度求解,容错性好,有界,渐进于0、1,符合人脑神经饱和的规律,但比sigmoid函数延迟了饱和期。
3.损失函数
3.1、交叉熵
交叉熵:刻画的是2个概率分布之间的距离。所以输入为2个概率分布。
适用于分类问题。
真实类标签,可以通过One-hot的编码方式生成概率分布,预测类标签,可以通过softmax函数(分类模型经过softmax函数之后,也是一个概率分布,因为概率之和为1)生成概率分布。
交叉熵越小,越相似。

cross_entropy=tf.nn.softmax_cross_entropy_with_logists(y,y_)3.2、均方误差MSE
MSE: Mean Squared Error
适用于回归问题
均方误差是指参数估计值与参数真值之差平方的期望值;
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
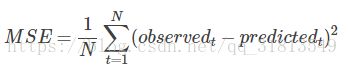
tf.reduce_mean(tf.square(y_-y))3.3 自定义损失函数
可以优化任意的损失函数,有时候一个问题不止一个损失函数,可能是多个损失函数结合在一起。
tf.greater()需输入两个张量,然后逐个元素比较,并返回一个包含所有结果的张量
tf.select()中第一个参数为bool型张量,当张量中的元素为True时,执行第二个参数(第1个损失函数),当为False时,执行第三个参数(第2个损失函数)
loss_less = 10
loss_more = 1
loss = tf.reduce_sum(tf.select(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less))
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)4. 神经网络优化算法
4.1 梯度下降算法
神经网络的优化过程可以分为两个阶段:
第一个阶段先通过前向传播算法计算得到预测值,并将预测值和真实值作对比得出两者之间的差距。
第二个阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。
梯度下降算法主要用于优化单个参数的取值,而反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,从而使神经网络模型在训练数据上的损失函数尽可能小。
缺点:
- 需要注意的是,梯度下降算法并不能保证被优化的函数达到全局最优解,参数的初始值会很大程度上影响最后得到的结果,只有当损失函数为凸函数时,梯度下降算法才能保证达到全局最优解。
- 除了不一定能达到全局最优之外,梯度下降算法的另外一个问题就是计算时间太长,因为要在全部训练数据上最小化损失,所有损失函数是在所有训练数据上的损失和。为了加速训练过程,可以使用随机梯度下降算法(SGD,stochastic gradient descent),这个算法优化的不是在全部训练数据上的损失函数,而是在每一轮迭代中,随即优化某一条训练数据上的损失函数。也由于在某一条数据上损失函数并不代表全部数据,于是使用随机梯度下降优化得到的神经网络甚至可能无法达到局部最优。
- 除了不一定达到全局最优和计算时间长之外,学习率和初始值也对训练的效果又很大的影响。
解决方法:
- 为了综合梯度下降法和随机梯度下降法,采取batch方法。即每次计算一小部分训练数据的损失函数。每次使用一个batch可以大大减小收敛所需要的迭代次数可同时可以是收敛的结果更加接近梯度下降的效果。
- 学习率可以通过指数衰减法进行设置。tf.train.exponential_decay函数实现了指数衰减学习率。通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减少学习率,使得模型在训练后期更加稳定。exponential_decay函数会指数级地减少学习率,它实现了如下功能:
global_step = tf.Variable(0)
LEARNING_RATE = tf.train.exponential_decay(0.1, global_step, 1, 0.96, staircase=True)
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x)
train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y, global_step=global_step)注:使用指数衰减的学习率,在minimize函数中传入global_step将自动更新global_step参数,从而使得学习率也得到相应更新。上面这段代码中设定了初始学习率为0.1,因为指定了staircase为True,所以不是平滑更新,而是阶梯式更新,所以每训练1轮后学习率乘以0.96。其中y代表的是损失函数。
5. 过拟合问题
5.1 正则化
为了避免过拟合的问题,一个非常常用的方法时正则化(regularization),正则化的思想就是在损失函数中加入刻画模型复杂程度的指标。假设用于刻画模型在训练数据上表现的损失函数为J(θ),那么在优化时不是直接优化J(θ),而是优化J(θ)+λR(w)。其中R(w)刻画的是模型的复杂程度,而λ表示模型复杂损失在总损失中的比例。常用的刻画模型复杂程度的函数R(w)有两种,一种时L1正则化,计算公式是:
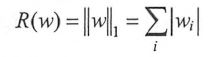
另一种时L2正则化,计算公式是:

无论时哪一种正则化方式,基本的思想都是希望通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪声。但这两种正则化的方法也有很大的区别,首先,L1正则化会让参数变得更稀疏,而L2正则化不会,所谓参数变得稀疏是指会有更多的参数变为0,这样可以达到类似特征提取的功能。在实践中,也可以将L1正则化和L2正则化同时使用:

下面代码给出通过集合(collection)的方式计算一个5层神经网络带L2正则化的损失函数的计算方法:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 生成模拟数据集
data = []
label = []
np.random.seed(0)
# 以原点为圆心,半径为1的圆把散点划分成红蓝两部分,并加入随机噪音。
for i in range(150):
x1 = np.random.uniform(-1, 1)
x2 = np.random.uniform(0, 2)
if x1 ** 2 + x2 ** 2 <= 1:
data.append([np.random.normal(x1, 0.1), np.random.normal(x2, 0.1)])
label.append(0)
else:
data.append([np.random.normal(x1, 0.1), np.random.normal(x2, 0.1)])
label.append(1)
data = np.hstack(data).reshape(-1, 2)
label = np.hstack(label).reshape(-1, 1)
plt.scatter(data[:, 0], data[:, 1], c=label,
cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.show()
# 定义一个获取全重,并自动加入正则项到损失的函数中
def get_weight(shape, lambda1):
var = tf.Variable(tf.random_normal(shape), dtype=tf.float32)
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambda1)(var))
# 定义了一个集合,集合的名字是‘loss’,每次都将第2个参数的值加入到集合中,lambda1为正则化的权重
return var
# 定义网络结构
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
sample_size = len(data)
# 每层节点的个数
layer_dimension = [2,10,5,3,1]
n_layers = len(layer_dimension)
cur_layer = x
in_dimension = layer_dimension[0]
# 循环生成网络结构
for i in range(1, n_layers):
out_dimension = layer_dimension[i]
weight = get_weight([in_dimension, out_dimension], 0.003)
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))
cur_layer = tf.nn.elu(tf.matmul(cur_layer, weight) + bias)
in_dimension = layer_dimension[i]
y= cur_layer
# 损失函数的定义。
mse_loss = tf.reduce_sum(tf.pow(y_ - y, 2)) / sample_size
tf.add_to_collection('losses', mse_loss)
loss = tf.add_n(tf.get_collection('losses'))
# 定义训练的目标函数loss,训练次数及训练模型
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
TRAINING_STEPS = 40000
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
sess.run(train_op, feed_dict={x: data, y_: label})
if i % 2000 == 0:
print("After %d steps, loss: %f" % (i, sess.run(loss, feed_dict={x: data, y_: label})))
# 画出训练后的分割曲线
xx, yy = np.mgrid[-1:1:.01, 0:2:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y, feed_dict={x:grid})
probs = probs.reshape(xx.shape)
plt.scatter(data[:,0], data[:,1], c=label,
cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.contour(xx, yy, probs, levels=[.5], cmap="Greys", vmin=0, vmax=.1)
plt.show()6. 滑动平均模型
在Tensorflow中还提供了tf.train.ExponentialMovingAverage来实现滑动平均模型。在初始化ExponentialMovingAverage时,需要提供一个衰减率,这个衰减率将用于控制模型更新的速度,ExponentialMovingAverage对每一个变量会维护一个影子变量(shadow variable),这个影子变量的初始值就是相应变量的初始值,而每次运行变量更新时,影子变量的值会更新为:
shadow_variable = decay * shadow_variable + (1 - decay) * variable
其中shadow_variable为影子变量,variable为待更新的变量,decay为衰减率。从公式中可以看到,decay决定了模型更新的速度,decay越大模型越稳定,在实际应用中,decay一般会设成非常接近1的数(比如0.999),为了使得模型在训练前期可以更新得更快。
注:如若转载,请注明出处。